AI System Boosts Multilingual Text Understanding for Global Businesses and Content Platforms
Invented by CHATTERJEE; Arindam, SHARMA; Chhavi, EKBAL; Asif, Wipro Limited
Understanding text that mixes two or more languages, also known as codemixing, is a real challenge for computers. A recent patent application introduces a new way for Generative Artificial Intelligence (GenAI) to better handle these mixed-language texts. In this article, we’ll break down why this matters, how it builds on existing research, and what’s special about this new invention.
Background and Market Context
Every day, people around the world use more than one language in the same sentence. This is called codemixing. You see it on social media, in text messages, and even in customer service chats. For example, someone might say, “Let’s go to the mercado later,” mixing English and Spanish. For people, this feels natural, but for machines, such as AI chatbots or translation apps, it’s confusing.
The world is becoming more connected, and many countries are home to people who speak more than one language. In India, for example, English and Hindi are often blended together. In the United States, Spanish words might appear in everyday English conversations. Businesses, schools, and governments want computers to understand this kind of language so they can give better service, make smarter decisions, and reach more people. The demand is huge — think of all the customer support bots, content filters, and language learning apps that need to make sense of mixed-language text.
But computers have trouble. Most AI and language models are trained on data from just one language at a time. When they see a sentence that jumps between languages, they get lost. This leads to mistakes — wrong translations, missed meanings, or answers that make no sense. This is a big problem for companies that want to serve international or bilingual customers, and for anyone who wants to use AI in a real-world, multilingual setting.
The market for AI tools that can handle mixed-language input is only going to grow. Social media platforms want to analyze posts and comments in all their messy, mixed glory. E-commerce companies want to understand reviews and questions from customers using different languages at once. Even government agencies want to process forms and documents from people who don’t stick to just one language. The need for smart, mixed-language understanding is everywhere.
This patent application comes at the perfect time. It promises to help computers truly understand and process text that blends two languages, opening the door for smarter AI assistants, better customer service bots, and more accurate tools for people everywhere.
Scientific Rationale and Prior Art
The science of teaching computers to understand human language is called Natural Language Processing, or NLP. Most NLP systems are built for just one language, like English, French, or Spanish. Over the years, researchers have tried different methods to help computers deal with more than one language. But when two languages are used together in the same sentence, things get tricky.
Early solutions used rules to try and separate the languages. For example, if a word is in Spanish, use one set of rules; if it’s in English, use another. But language is messy. People don’t follow a script. They might switch mid-sentence or even mid-word! Rule-based systems simply couldn’t keep up.
Later, machine learning models were trained on large piles of text. If you feed a computer enough English and enough Spanish, it gets pretty good at each. But mixed-language sentences are rare in most training data. That means models trained this way get confused when they see codemixed text. They might translate part of the sentence right and mess up the rest.
Researchers tried to fix this by making “parallel corpora,” which are big collections of sentences in two languages. But finding or building huge collections of real codemixed sentences is hard. There just isn’t enough data out there. Without data, even the best AI models can’t learn properly.
Some more recent work uses neural networks, like transformers, which are very good at spotting patterns in text. These models, like the famous GPT or BERT, can handle many languages, but they still struggle with codemixing. That’s because they haven’t been trained on enough examples of mixed-language sentences. They see codemixed text as something strange and don’t know what to do.
One common workaround has been to fine-tune pre-trained models on small collections of codemixed data. This helps a bit, but if the data is too small or too narrow (focused on just one topic), the model doesn’t get good at codemixing in general. It might work for one company’s customer support, but not for social media posts or medical documents.
In short, the science so far has hit a wall: there’s not enough data, and there’s no good way to teach models about the complexity of real codemixed language. The few existing systems are not accurate enough, and they can’t be adapted easily to new languages or new topics. This is where the new patent application steps in, offering a fresh approach.
Invention Description and Key Innovations
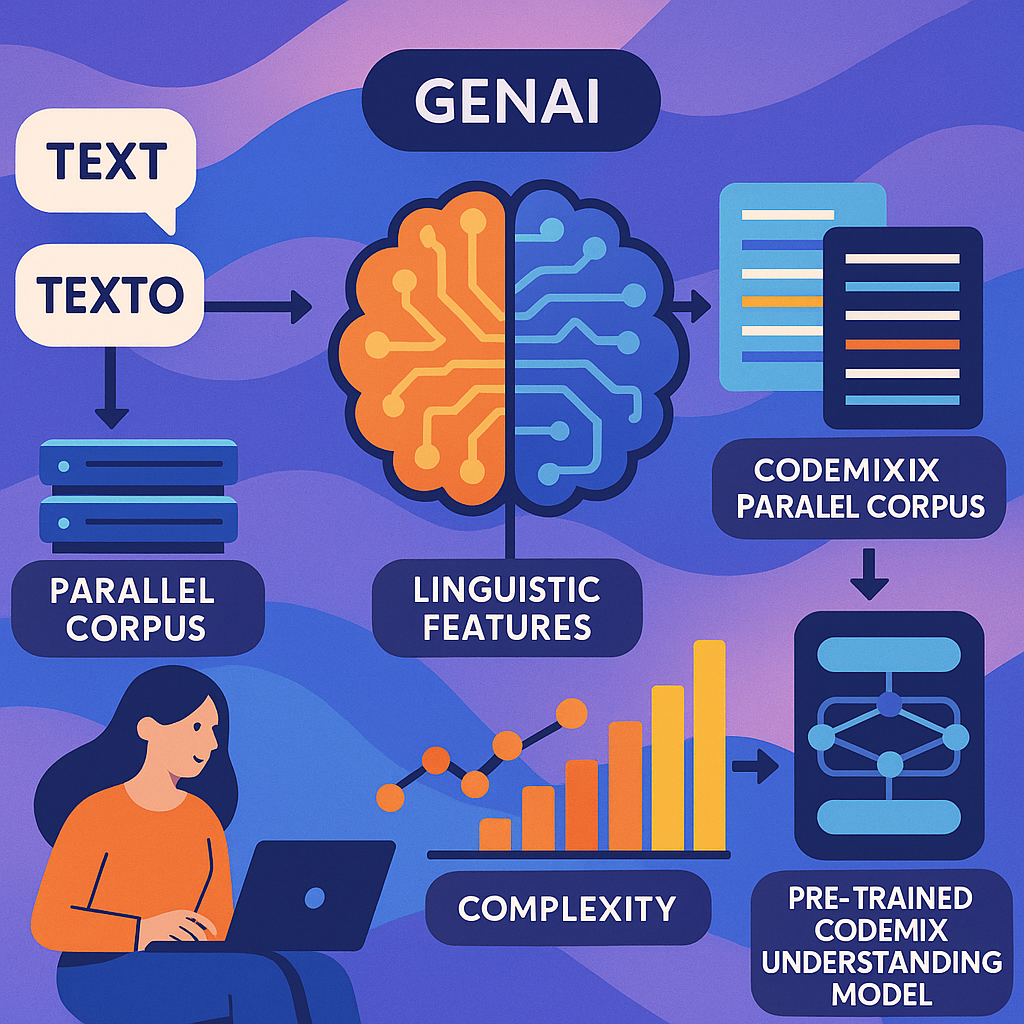
The heart of this invention is a better way to train GenAI models to understand and process mixed-language text. The method uses smart data preparation, clever use of language features, and a teaching style called “curriculum learning” to make AI models that really get codemixing.
Here’s how it works, in plain language.
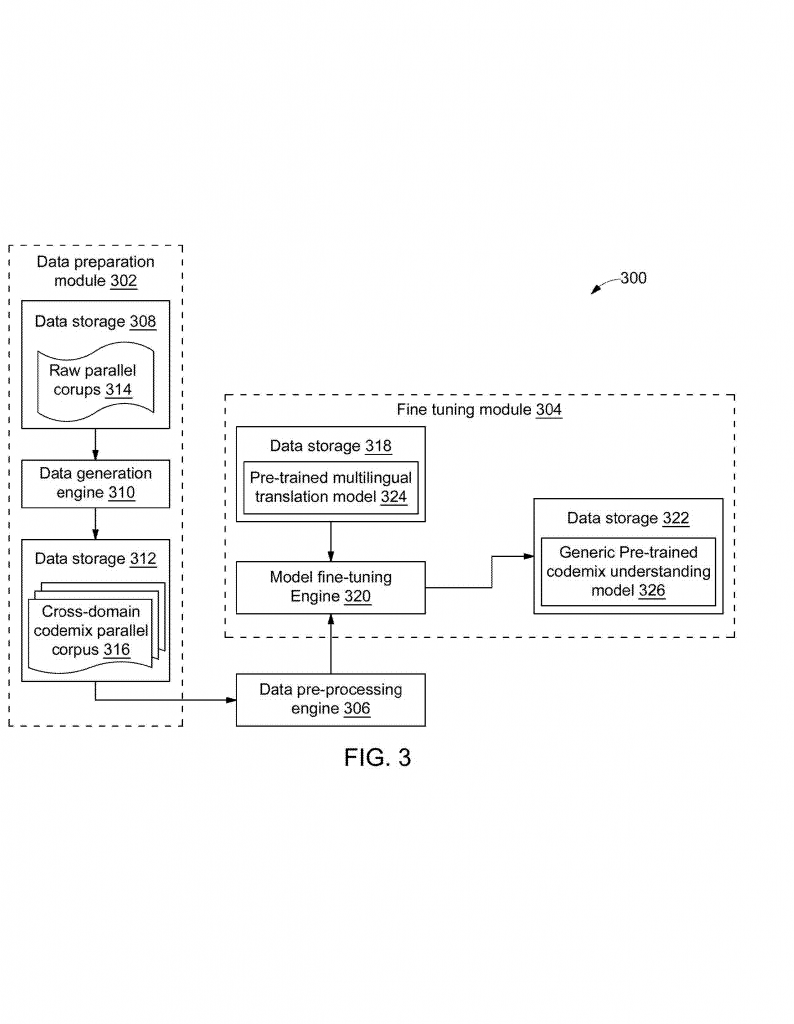
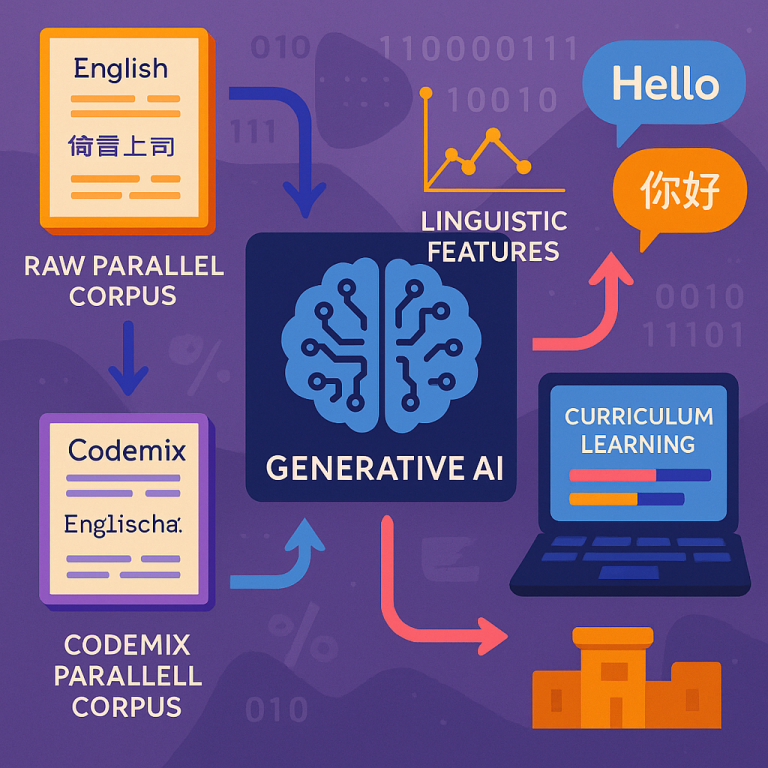
First, the system collects a “raw parallel corpus.” This means it gets lots of text samples in two languages that say the same thing. For example, a sentence in English and its matching sentence in Spanish. This is called “parallel” because the meaning matches in both languages, even if the words are different.
Next, the system uses special tricks from statistics and linguistics to create new, codemixed sentences. It mixes up the English and Spanish versions to make sentences that jump between the two languages, just like real people do. Along with these mixed sentences, the system also records some smart features, like which words belong to which language, where the language switches happen, how much mixing there is, and which language is the “main” one in the sentence. These features help the AI model understand the structure of codemixed text.
But not all codemixed sentences are equally hard. Some might have just one language switch, others might jump back and forth many times. Some use rare words, while others stick to common language. This invention rates each sentence based on how complex it is, using a mix of the number of language switches, how mixed up the words are, and how rare the vocabulary is.
Now comes the clever part: curriculum learning. Just like a child learns easy words before hard ones, the AI model is first trained on the simple codemixed sentences, then on the harder ones. This way, the model builds up its skills gradually, getting better at handling complex, real-world codemixing step by step.
The invention doesn’t stop there. It also allows the system to gather domain-specific text — for example, medical or legal documents — and repeat the same process. The AI can then be fine-tuned to understand codemixing in that special area, making it even more useful for companies or organizations in those fields.
The technical system is flexible. It can run on any modern computer, using a mix of processors and memory to handle the data and model training. The invention can be built into translation apps, chatbots, content moderation tools, and more.
So what’s really new here? It’s the way the invention:
– Creates a big, realistic codemix dataset by combining parallel corpora and smart linguistic features.
– Measures and sorts the complexity of codemixed sentences so the AI can learn in a smart order.
– Uses curriculum learning so the AI builds up its codemix skills gradually, just like a student.
– Fine-tunes generic and domain-specific models, so the same method can adapt to any topic.
With these steps, the invention solves the key problems of not having enough codemix data, not knowing how to teach models about real codemixing, and not being able to adapt to different domains. It’s a big step forward for making AI that truly understands how people use language in the real world.
Conclusion
This new patent application brings a fresh and powerful approach to teaching GenAI models how to understand mixed-language, or codemixed, text. By creating rich, realistic datasets, measuring sentence complexity, and using a curriculum learning approach, the invention allows AI to learn codemixing step by step. It can be adapted to different domains, making it useful for many businesses and organizations. As our world becomes more multilingual and more connected, tools like this will be essential for smarter, more helpful AI. The future of language understanding in AI is brighter — and much more inclusive — thanks to inventions like this.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250363315.

