Accelerating AI Insights: Hardware Solution Speeds Up Graph Neural Network Processing for Enterprise
Invented by KUMARAPILLAI CHANDRIKAKUTTY; Harikrishnan, MUNIPALLI; Sirish Kumar, SHASHANK; FNU, HTET; Aung Thu, Microsoft Technology Licensing, LLC
Graph Neural Networks (GNNs) are changing how computers learn and understand connected data, but training these networks can be slow and use lots of memory. This new patent application reveals a special hardware solution that makes GNNs much faster and smaller, bringing better AI to all kinds of devices—from phones to big servers. Let’s explore how this invention works and why it matters.
Background and Market Context
Artificial intelligence is everywhere now. We see it in phones, cars, smart speakers, and big data centers. These systems use different kinds of neural networks to make smart choices quickly. One powerful type is the Graph Neural Network (GNN). GNNs help AI understand things that are connected, like social networks, molecule shapes, or routes in traffic maps. They are very good at answering questions about how things are linked together.
But GNNs are not easy to train. When you make a GNN, you start with a big web of nodes and lines—like a spider’s web, but much bigger. Training means teaching the GNN to recognize patterns in this web. This takes lots of time and power. In big centers, CPUs and GPUs—computer parts made for regular programs or video games—work on these tasks. But even strong GPUs can get overwhelmed. The training can last hours or even days, and the computer can’t do much else while it’s working. The GNN also takes up a lot of space in memory. For small companies or anyone using a phone or a laptop, this is a big problem.
Today, making GNNs faster and smaller is a big goal for the tech world. If you can train a GNN quickly and make it use less memory, you can use it in more places. It can help phones answer questions faster, let cars learn about traffic in real time, and help doctors spot patterns in patient data without waiting long or using huge computers.
But there is another problem. Even after a GNN is trained, it is often too big. It has extra nodes and connections it doesn’t really need. If we can “prune” it—cut out the extra parts—we can make it much smaller and just as smart. But pruning also takes time and power. That’s why a special solution is needed, one that can do both training and pruning quickly and without using up all the computer’s energy.
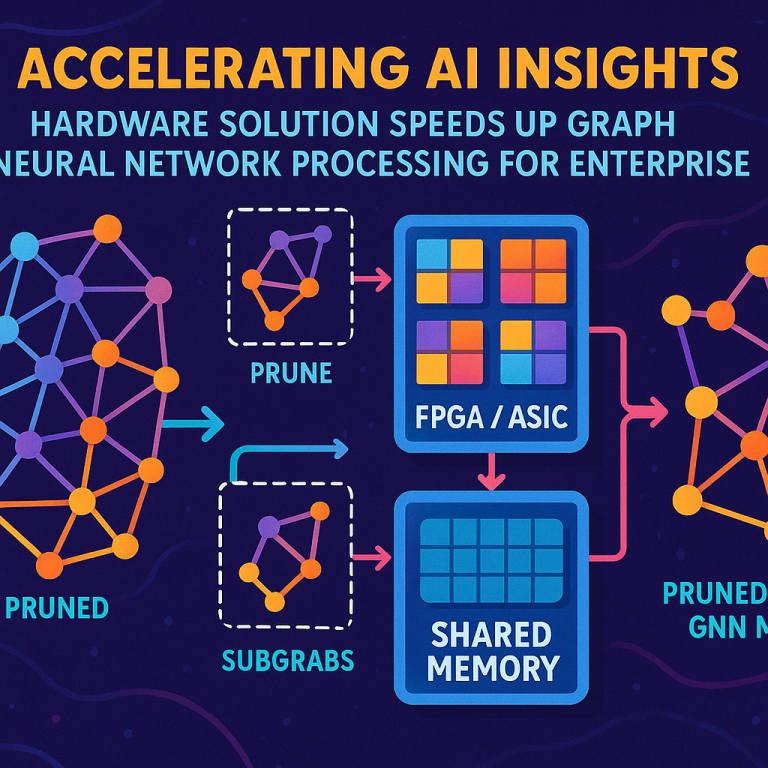
This is where the invention in this patent comes in. It is a new kind of hardware add-on, made to handle GNNs from start to finish. It takes in a big, untrained GNN, splits it into smaller parts, trains each part, prunes away the unneeded stuff, puts it all back together, and sends it to your device—ready to use. And it does all this much faster than regular computers, using less memory and power. This could change how AI works for everyone.
Scientific Rationale and Prior Art
To understand why this invention matters, let’s look at how things were done before and what makes this new idea different. GNNs are powerful because they work with data that is shaped like a graph—a set of things (nodes) with links (edges) between them. But this shape makes them tricky to train. You need to keep track of lots of connections, and when you try to teach the GNN, every change can affect many other parts of the network. This means lots of math and lots of memory use.
For years, people used regular CPUs and GPUs to train GNNs. CPUs are good for many tasks at once, and GPUs are great for handling lots of simple tasks together. But both are made for many jobs, not just GNNs. When you use them for GNNs, they get bogged down. The training is slow, and pruning (removing extra parts) is even slower. You can try to split the GNN into smaller parts and train them separately, but coordinating all the parts takes time, and the memory gets filled up fast.
Some people have tried using special chips called FPGAs (Field Programmable Gate Arrays) or ASICs (Application Specific Integrated Circuits). These chips can be set up to do only one thing really well. You can tell an FPGA to process GNNs, and it will do just that—no wasted effort. ASICs are like FPGAs, but even more focused; they are built for one job from the start. These chips are great for saving energy and doing tasks in parallel (many at once). But even with these chips, you need a smart way to split the GNN, train each part, prune it, and put it all back together.
Another problem is how you decide what to prune. Some old methods just look at the size of the connections—if a connection is small, cut it. But this doesn’t always work. Sometimes, a small connection is very important for learning. Newer methods, like GraSP (Gradient Signal Preservation), look at how much each part helps the GNN learn. GraSP tries to keep the parts that matter most for passing learning signals through the network. This keeps the pruned network just as smart as before, but much smaller.
But even with smart pruning, doing all this on regular hardware is slow. You need a system that can:
1. Split the big GNN into small parts.
2. Train and prune each part at the same time, in parallel.
3. Keep all parts in sync, so they can be joined together later.
4. Do this quickly and with little energy use.
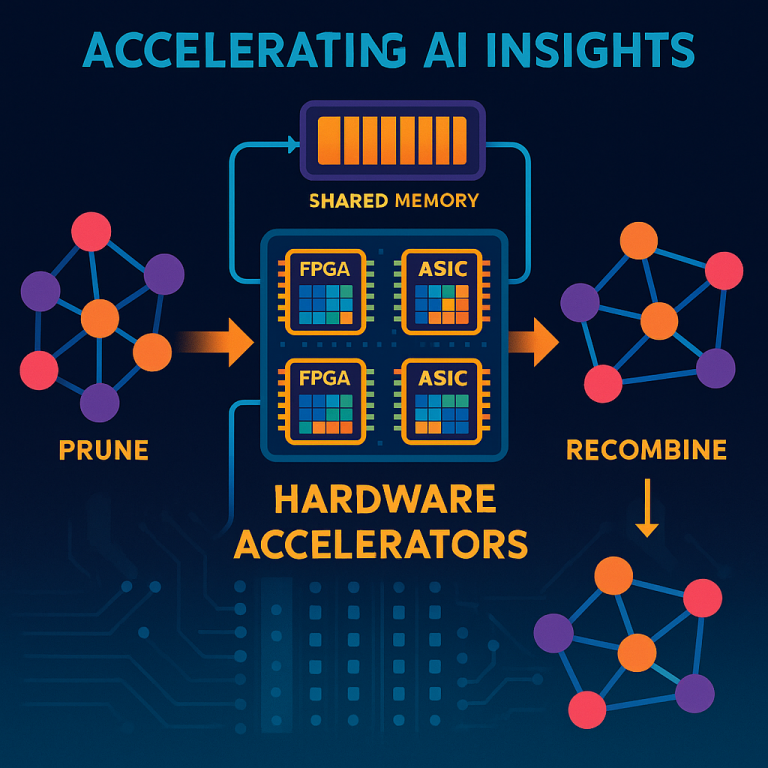
No one had put all these steps together in one hardware system. Most systems did training or pruning, not both. Or they used software for the hard parts, which slowed things down. This new patent brings all the pieces together in a new way. It uses many FPGAs or ASICs working in parallel, each with its own small processor, all sharing memory. Each processor gets a piece of the GNN, trains it, prunes it using GraSP, and sends it back. The shared memory lets them talk to each other and combine the results. This setup is fast, uses less power, and gives you a small, smart GNN ready for any device.
Invention Description and Key Innovations
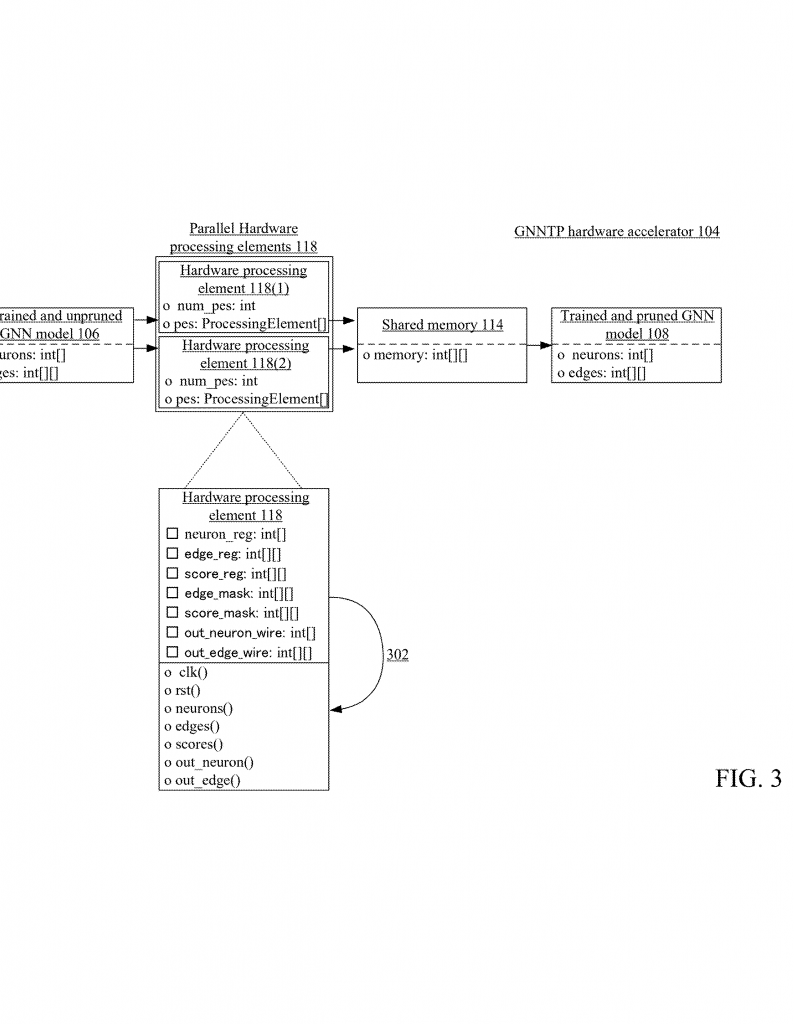
This invention is a special system for training and pruning GNNs. It is made of two main parts: a device (like a phone, tablet, or server) and a hardware accelerator (the GNNTP hardware accelerator). The device sends an untrained GNN model to the accelerator. The accelerator does the hard work and sends back a trained and pruned GNN model that the device can use to answer questions or do tasks.
Here’s how the system works, step by step:
1. Receiving the GNN Model: The device has a big, untrained GNN model. This is too big and slow for the device to handle by itself. So, it sends this model to the hardware accelerator.
2. Splitting into Subgraphs: The accelerator takes the big GNN and breaks it into smaller pieces, called subgraphs. Each subgraph is small enough to fit on one of the processors inside the accelerator.
3. Parallel Processing: The accelerator has many processors (called hardware processing elements). These can be inside FPGAs or ASICs. All processors work at the same time, each on its own subgraph. This makes the process much faster than using one big processor.
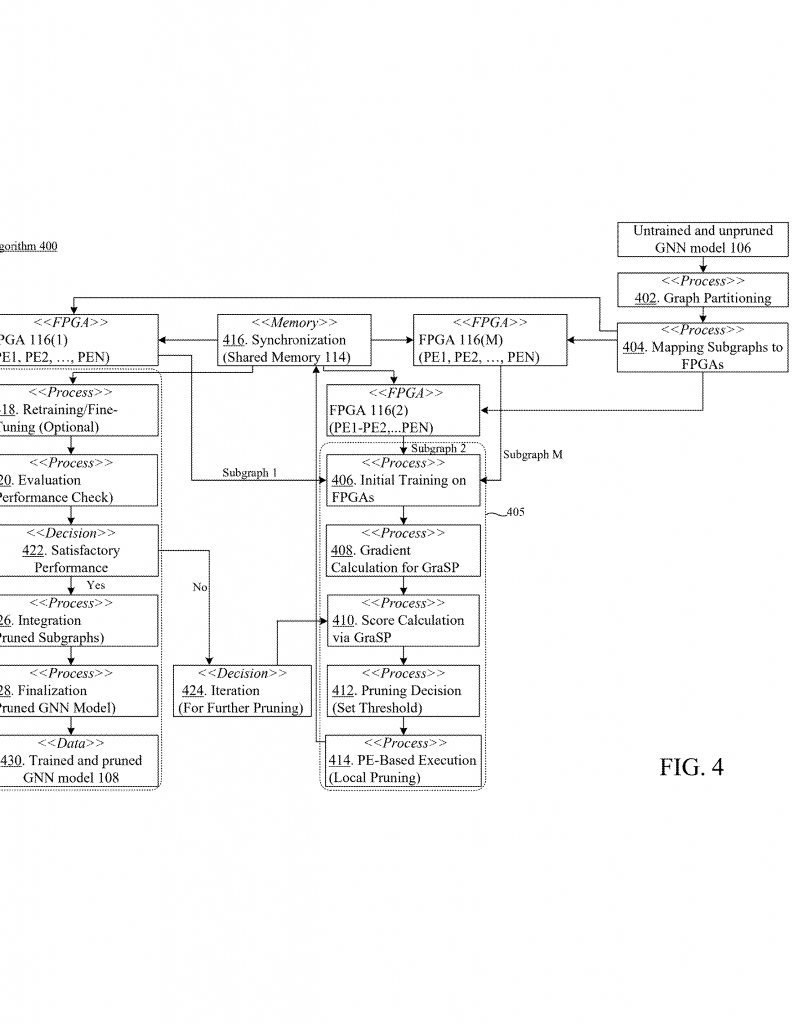
4. Training and Pruning with GraSP: Each processor trains its subgraph using a smart pruning method called GraSP (Gradient Signal Preservation). This method looks at how important each node and connection is for learning. It keeps the important parts and prunes away the rest. This is not just about size—it’s about keeping the brain of the network alive while making it smaller.
5. Shared Memory for Teamwork: All processors use the same pool of memory. This shared memory lets them put their pruned subgraphs together and make sure they fit. If a subgraph needs to talk to another, they can share info quickly. This makes the whole process smooth and keeps all parts in sync.
6. Recombining: Once all subgraphs are trained and pruned, the accelerator puts them back together into a single, smart, and small GNN model. If needed, the system can check how well the new model works. If it’s not good enough, it can go back and retrain or prune more, until the GNN is just right.
7. Sending Back to Device: The final, trained and pruned model is sent back to the device. Now, the device can use this small, fast GNN to do smart tasks—like answering user questions—without needing lots of memory or power.
The key innovations in this invention are:
A. Specialized Hardware Accelerator: Unlike regular computers, this system uses hardware built just for GNN training and pruning. FPGAs and ASICs can be made to do only what is needed—nothing more, nothing less. This means less wasted energy and much faster results.
B. True Parallelism: All parts of the GNN are processed at the same time. This is like having a team of workers, each with their own job, instead of one person doing everything. The shared memory makes sure everyone is working together and nothing gets lost.
C. Smart Pruning with GraSP: The GraSP algorithm is not just about cutting out parts—it’s about keeping the parts that help the GNN learn best. This means the final model is not just smaller, but also just as smart (or almost as smart) as the big one.
D. Flexible and Scalable: The system can use one or many FPGAs or ASICs. It can handle small or very large GNNs. It can be used in a phone, a laptop, or a big data center. The same system works everywhere.
E. Pipeline Processing: The processors work in a pipeline, passing subgraphs along as they finish. This keeps everything moving and avoids bottlenecks.
F. Adaptive Thresholds: The system can adjust how much it prunes based on how well the GNN is performing. If pruning too much makes the GNN worse, it can prune less, or retrain and try again. This makes the system smart and able to give the best results every time.
G. Saves Energy and Memory: By doing all this in hardware and only keeping what matters, the system saves lots of power and memory. This is good for phones, tablets, and other devices that can’t use as much energy as big servers.
H. Ready for Real-World Use: The final, pruned GNN can be used in any device—phones, tablets, laptops, cars, or servers. It can answer questions, help with navigation, spot patterns in data, or do any other smart task that GNNs are good at.
The patent also describes how the system can use different pruning methods if needed. While GraSP is the main one, others can be added. The system is built to be flexible and ready to grow as AI changes.
Conclusion
This patent shows a new way to make GNNs faster, smaller, and ready for any device. By using special hardware, working in parallel, and pruning smartly with GraSP, the system can take a big, slow GNN and turn it into a small, quick one—without losing its smarts. This makes AI more useful for everyone, from big companies to anyone with a smartphone. As AI keeps growing, systems like this will help bring smart features to more places, using less energy and working faster than ever before.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250362958.

