New Headline: “Unified Risk Scoring Transforms Cloud Software Deployments for Proactive Failure Prevention” SEO Keywords embedded: risk scoring, cloud software deployments, failure prevention, cloud computing, proactive risk management Industry/application area subtly indicated: cloud software / cloud computing / enterprise IT **Explanation:** This headline speaks directly to leaders in cloud software or IT, making clear that the invention offers a unified way to anticipate and manage deployment risks—helping organizations prevent costly failures before they happen.

Invented by MEYER; Chase Ryan, ASOK; Abhijith, MOORE; Josh Charles, CHEN; Yingying, MADHANAGOPAL; Vijaybalaji, NAG; Amitabh, SHAIKOT; Shariful Hasan, KUMAR; Abhishek, VELUSWAMI; Senthilkumar, DHADDA; Harjinder Singh, PERSEMBE; Ahu, HOSSAIN; Mohammed Nafij, KRAVSOV; Irina, MEGHWANSHI; Mayank, ZHENG; Lin, BOAKYE; Afia, DAOUPHARS; Julien, BAPAT; Akshay Sudhir

Making sure that software updates in cloud systems do not cause problems is very important. With cloud platforms being so big and complex, any mistake can impact lots of users. This blog post will help you understand a new way, described in a recent patent application, for figuring out how risky it is to update software on clusters of computers in the cloud. We’ll look at why this matters, how past solutions work, and what makes this new invention special and helpful for today’s needs.
Background and Market Context
The world relies on cloud computing for almost everything—banking, health, shopping, entertainment, and more. Cloud platforms are made up of many clusters, which are groups of computers called nodes. Each node often runs several virtual machines. These virtual machines are like computer programs that act as full computers, sharing the hardware but working separately. This setup is great for saving space and money, but it also means that when you change something—like updating software or installing a new operating system—one small problem can spread quickly and hurt many users at once.
Cloud companies want to give their users a reliable, always-on service. But as these systems get bigger, with thousands of clusters and millions of nodes, it gets harder to keep things running smoothly, especially when updating software. If a problem happens during an update, it can cause downtime, data loss, and unhappy customers. For important users like hospitals, government offices, or big companies, even a short outage can be a big deal.
Because of these risks, companies have created systems to check how risky it might be to update their software. They want to find out if a new update is safe or if it could cause problems. But most of the old systems only look at clusters as a whole, not at each node or virtual machine inside them. This means they might miss small problems that could grow into big ones. Also, they often do not pay attention to which users or virtual machines are more important, like those running hospital software or storing sensitive information.
There’s a clear need for a smarter, more careful way to check risks. Cloud providers must be able to look closely at every part of their system and understand not just how likely a problem is, but also how bad it would be if something goes wrong. With more and more important services moving to the cloud, this need only gets bigger.
Scientific Rationale and Prior Art

In the past, risk checking for cloud software updates mostly used simple math or statistical models. These models look at things like how often a cluster has had problems before, or what kind of hardware it uses, to guess if an update might go wrong. Usually, these checks are done at the cluster level, meaning they look at the entire group of nodes as one big block. This is easier to do, but it often misses the smaller details.
One problem with old methods is that they treat all nodes and virtual machines as if they are the same. But in real life, different nodes can have different hardware, different virtual machine sizes, and different jobs. For example, one node in a cluster might be running a hospital’s patient system, while another is just handling test data. If the risk system treats them the same, it might let a risky update go through and cause trouble for the most important users.
Old models also mix up different causes for problems. For example, if a virtual machine stops working, older systems might count that as a problem with the software update, even if it was caused by something else, like a user mistake. This makes the risk calculations less accurate. Also, older systems often do not check if a node or virtual machine has been tested enough with the new software, which means they might miss unexpected problems.
Some past systems have tried to improve by collecting more data. They look at things like the type of hardware, the version of the operating system, or the amount of memory and storage. But even then, they mostly use this data to make broad guesses, not to look closely at each node or user. They also rarely consider how important each node or virtual machine is, or who is using it.
With more critical services moving to the cloud, and with cloud platforms becoming more complex, these old ways are just not enough. There is a need for a system that can look at every detail, tell the difference between a small risk and a big risk, and make sure that important users get extra care during software updates.
Invention Description and Key Innovations
The new method in the patent application changes how risk is checked before software updates in cloud systems. Instead of just looking at clusters as a whole, it looks at each node and each virtual machine closely. Here’s how it works and what makes it better:
1. Collecting Detailed Data
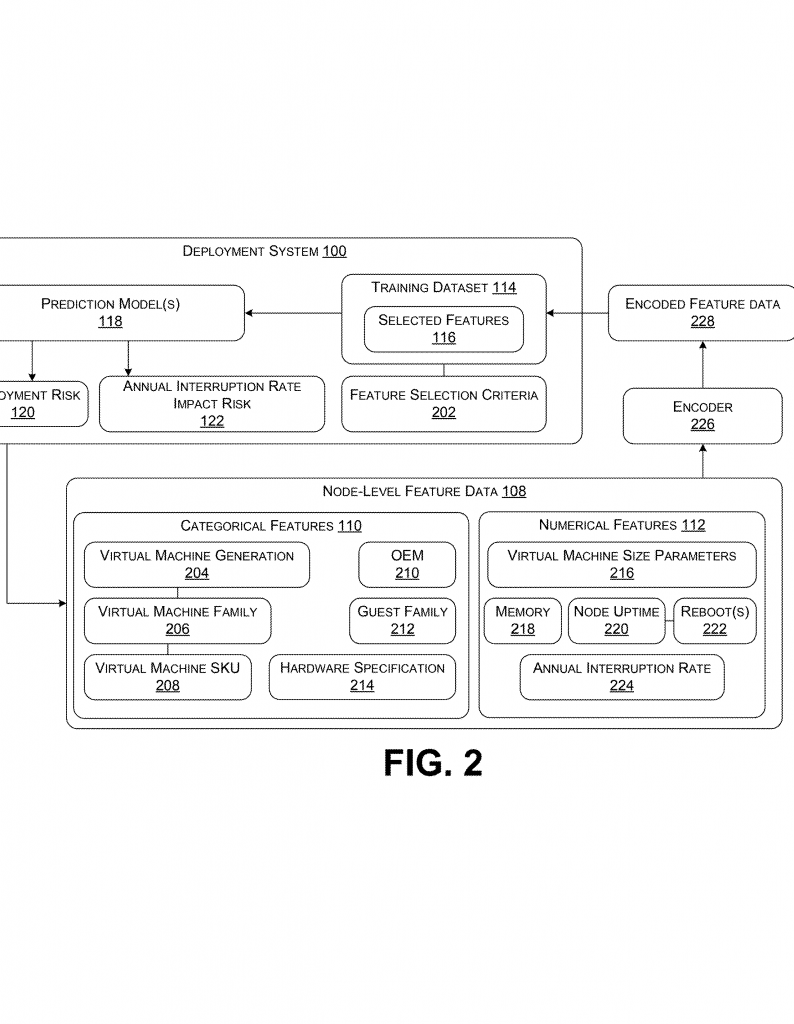
The system starts by gathering lots of information from every node in a cluster. This includes things like the type of hardware, the family and generation of the virtual machine, how much memory and storage each one has, what operating system it’s running, and how many virtual machines are on each node. This detailed information is called node-level feature data.
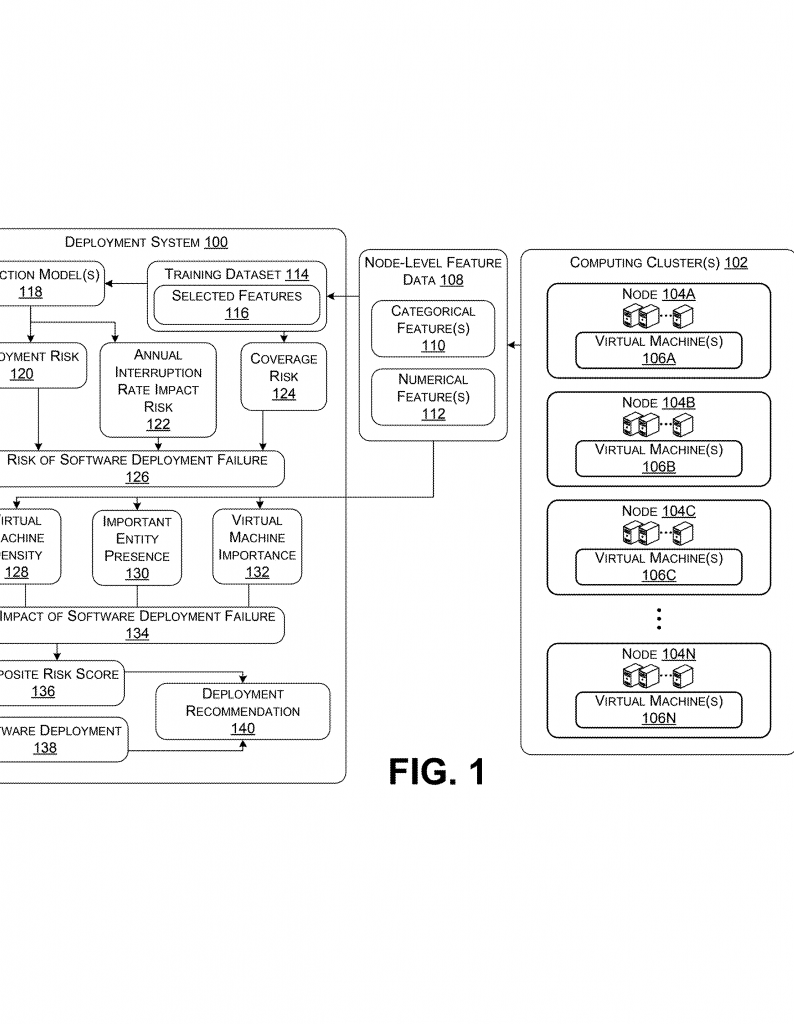
2. Training Smart Models
The collected data is used to train a smart computer model. This model learns from past updates—what went right, what went wrong, and why. It uses this learning to predict how risky a new update might be for each node. The training data is usually turned into numbers so the model can understand it better, often using a method called one-hot encoding. This makes sure that the model can handle all the different kinds of information from each node.
3. Calculating Three Types of Risk Scores
Instead of just one risk score, the system looks at three main types:
- Deployment Risk Score: This shows how likely it is that the update will cause problems, based on what the model has learned from all the detailed node data.
- Annual Interruption Rate Impact Risk: This checks how often virtual machines have stopped working in the past because of updates. It makes sure to only count problems caused by updates, not by other things, making the score more accurate.
- Malfunction Likelihood Score: This looks at how likely it is for the update to go wrong on certain hardware setups, based on how much testing has been done on those setups before. If a node has not been tested much, its risk score goes up.
4. Combining the Risk Scores
These three risk scores are put together to get an overall risk of failure for the update on each cluster. This combination can be a simple average or use more advanced math, but the key is that it brings together lots of information from different places.
5. Measuring the Impact of Failure
The system also checks how bad things would be if something goes wrong. It does this by looking at:
- Virtual Machine Density: How many virtual machines are running on each node. More VMs mean more users could be affected.
- Important Entity Presence: Whether important users, like hospitals, governments, or companies with sensitive data, are using the node. If yes, problems are more serious.
- Virtual Machine Importance: How much computing power each VM is using. Bigger VMs usually mean more important jobs, so problems there matter more.
These factors are also combined to get an overall impact score.
6. Creating a Composite Risk Score
Finally, the system mixes the overall risk of things going wrong with the impact score. This gives a single composite risk score, which tells you not just how likely a problem is, but also how bad it would be if it happened.
7. Making Deployment Recommendations
Based on this final score, the system automatically decides what to do about the update for each cluster. If the risk is low, the update goes ahead. If the risk is moderate, the update is done more slowly and carefully. If the risk is high, the update is blocked until things can be checked more closely. All these decisions can be shown on a dashboard, so the people in charge can see what’s happening and why.
8. Learning and Improving Over Time
After each update, the system looks at what actually happened. If there were problems, it learns from them and updates its training data, so it gets better at predicting risks in the future.
Why This Matters and How It Helps
This new method is a big step forward because it:
- Looks at every node and virtual machine, not just clusters as a whole.
- Tells the difference between small and big risks and between problems that matter more or less.
- Pays special attention to important users and big virtual machines, so their needs are not missed.
- Learns and gets better over time, making future updates safer.
- Makes it easier for people to see what’s happening and make good decisions using a clear dashboard.
For cloud companies, this means fewer outages, happier customers, and more trust, especially from users who rely on the cloud for critical services. For businesses and public services, it means less worry about updates causing problems that could hurt people or cost money.
Conclusion
Updating software in the cloud is tricky, but with this new risk assessment method, it doesn’t have to be scary. By looking closely at every node and virtual machine, using smart computer models, and thinking about both the chances and the impact of failure, this system makes updates much safer. It also keeps getting better with time, learning from each update. This makes cloud platforms stronger and more reliable for everyone, from big businesses to everyday users. If you run cloud services or rely on them, this kind of innovation is good news—it means more uptime, fewer surprises, and a better experience for all.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250362894.

