Unlock Actionable Insights from Audio Data with AI-Driven Audio-Text Knowledge Graphs for Enterprises
Invented by Lin; Wei-Cheng, Wu; Ho-Hsiang, Ghaffarzadegan; Shabnam, Bondi; Luca, Kumar; Abinaya, Das; Samarjit
Understanding sounds and connecting them with words is a hard task for computers. A new patent application shows how to use knowledge graphs and large language models to make this easier and smarter. In this article, we break down this invention in simple words. We’ll first look at the market background, then discuss the science and older ways of doing things, and finally unpack the invention and what makes it special.
Background and Market Context
People use sound every day, from listening to music to talking on the phone. Computers are now learning to understand sounds too. This is useful in many areas—like smart assistants, customer support, video sharing websites, and even in cars. But computers don’t just need to “hear” sounds; they need to know what those sounds mean. For example, is it a dog barking, a door closing, or someone laughing? And if there is text about those sounds, like captions or tags, computers need to connect the right words to the right sounds.
Many businesses and new products depend on machines understanding audio. Music apps want to recommend songs by mood. Video platforms need to tag clips for search. Cars need to detect sirens, and hearing aids must filter important speech from background noise. In all these cases, computers must connect audio with language. This is called audio-text modeling. It’s getting more important as voice and sound become bigger parts of technology.
But there’s a problem. Humans are very good at using what they already know to make connections. Computers, on the other hand, can struggle. For example, if a sound is new or not labeled, a computer may not know what it is. Or, if a sound could mean more than one thing (like a “bang” could be a door or a gunshot), computers need more clues to pick the right answer.
This is why companies want better systems that help computers use both sound and language together—and do it in a way that uses knowledge, not just guesses. Knowledge graphs are one way to do this. They are like maps that show how things are related, with facts and meaning built in. If computers can build these maps and use them with sound and text, they can get much better at understanding the world.
As audio and voice become more important in devices and services, the market is hungry for better solutions. Businesses want smarter search, more helpful assistants, richer media tagging, and safer cars. But old methods are slow, need lots of human work, and often miss the big picture. This is where the invention covered by the patent comes in.
Scientific Rationale and Prior Art
Let’s talk about how computers have tried to solve this problem before and why those ways fall short. For a long time, machines used simple tags or labels for sounds. If a sound clip was of a barking dog, someone would write “dog” or “bark” as the label. These labels help, but they are limited. They don’t show how “dog” is related to “pet,” “animal,” or “noise.” They don’t show if the bark was happy, angry, or far away. Most of all, computers need humans to write all these labels, which takes a lot of time and effort.
To improve this, researchers started using machine learning. These are computer programs that learn from lots of data. For example, if you give them thousands of sound clips with labels, they can learn to spot patterns and guess the label for a new clip. This works better, but still has limits. Machine learning models can get confused if the data is messy or if there are sounds that are not labeled. They also can’t really “think” about meaning—they just look for patterns.
A bigger leap came with knowledge graphs. A knowledge graph is like a web, where each point (called a node) is an object or a concept—like “dog,” “bark,” “park,” or “owner.” Lines (called edges) show how these things are linked—maybe “dog” is a kind of “animal,” and “bark” is a sound made by “dog.” If computers can build and use these graphs, they can understand not just facts, but how facts connect.
But building these graphs is hard. Making them by hand is slow and expensive. Automatic ways often need lots of labeled data, which again means lots of work by people. There’s also the risk that computers make mistakes—they might link things that should not be linked, or miss important connections. Recent advances in large language models (LLMs), like ChatGPT, have opened new doors. LLMs can read, write, and reason with language. They can take a prompt and generate text, or answer questions about knowledge. They can help build knowledge graphs by reading metadata and guessing missing links.
Still, there are problems. LLMs can “hallucinate,” which means they might make up facts that sound right but are not true. This can confuse systems and lead to bad results. Also, most LLMs and knowledge graphs have focused on text, not on audio. There is a gap in combining sound and language in a way that really uses knowledge, not just labels.
Some efforts have tried to bring audio and text together. For example, some tools turn speech into text and then use language models to process it. Others use audio features (like pitch or volume) as extra clues. But these methods often miss the deeper links between sound, meaning, and context. They don’t use a true knowledge graph that brings everything together.
In summary, the prior art includes simple labels, machine learning models, and some knowledge graphs. There are also LLMs that can process language. But there are gaps: human labeling is slow, machine learning can miss meaning, and LLMs can make mistakes. Most of all, no one has fully combined audio, text, and knowledge graphs in an automatic way that is robust and practical. This is the scientific gap that the patent aims to fill.
Invention Description and Key Innovations
Now let’s dig into what the invention actually does, and why it matters.
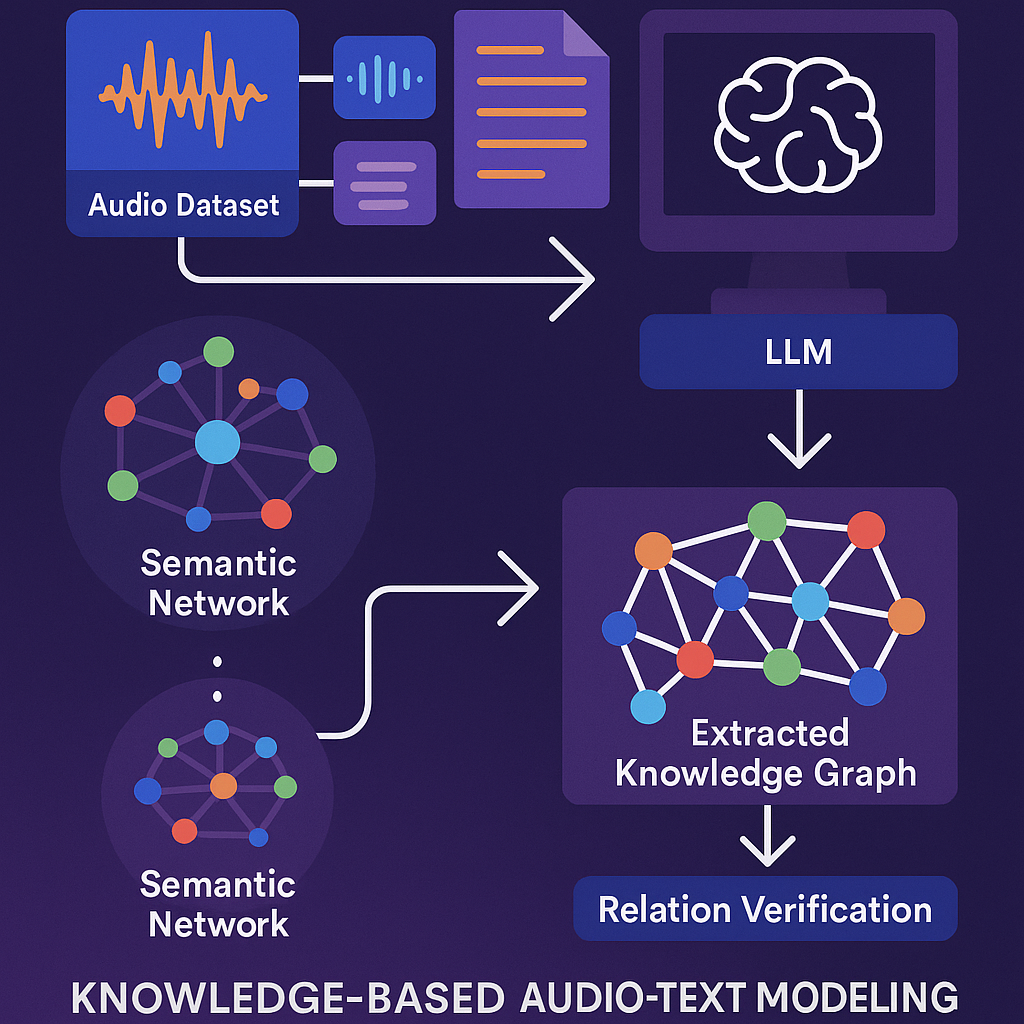
At its heart, the invention is a way for computers to build and use knowledge graphs that connect audio and text, using the power of large language models. The system is made up of several steps, each designed to make the whole process automatic, smart, and reliable.
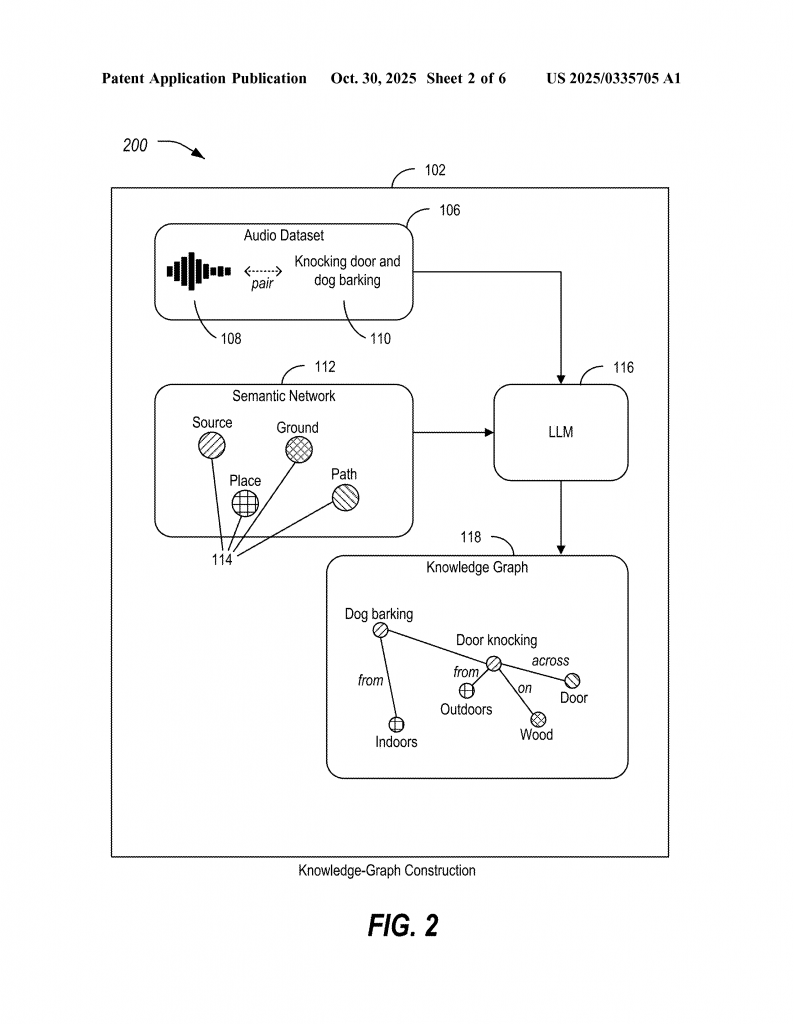
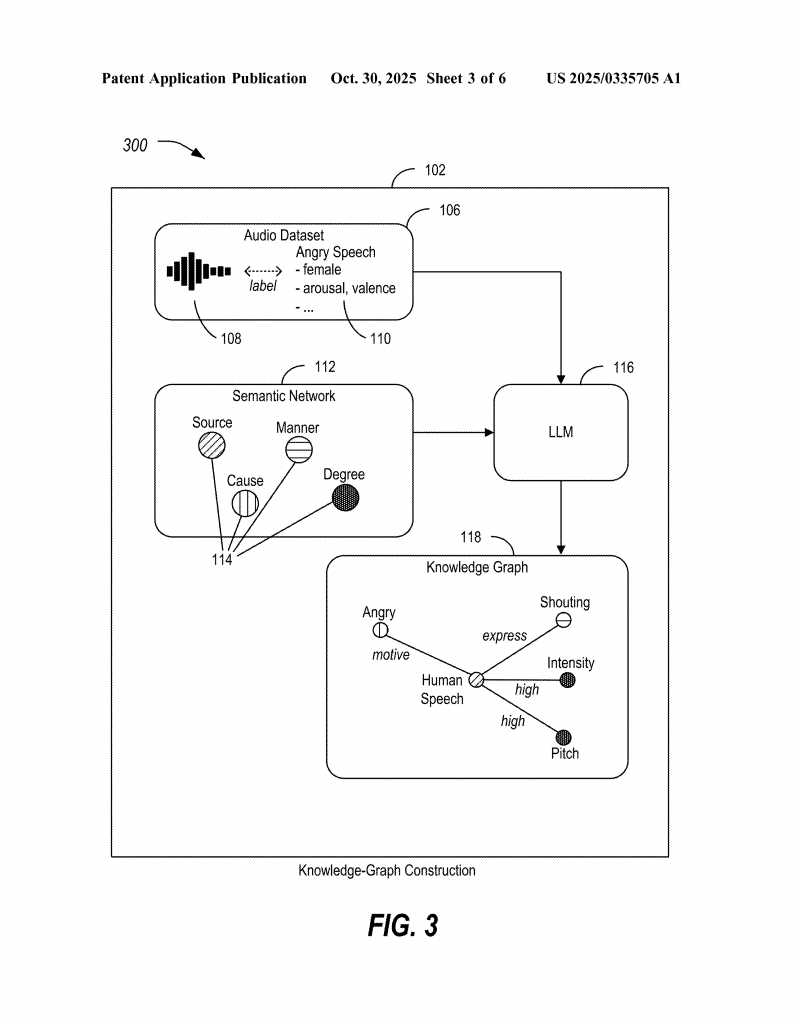
The process starts with an audio dataset. This is a collection of sound clips, like recordings of dogs barking, doors closing, people talking, or music playing. Each clip comes with metadata. This metadata can be things like a human-written caption (“Dog barking in the park”), a label (“dog, park, barking”), or even information made by a machine learning model (like “emotion: happy, pitch: high”).
Next, the system finds “graph nodes of interest.” These are the key ideas or facts to put into the knowledge graph. For example, nodes might include “source” (who or what made the sound), “place” (where the sound happened), “ground” (what the sound bounced off), and “path” (how the sound moved). These nodes can come from several places: they can be picked by a human expert, pulled from a database, found by searching a semantic network (like FrameNet, which lists common language frames), or even suggested by the LLM itself.
Once the nodes are set, the real work begins. The system uses a large language model to sort the metadata into the right nodes. If the metadata says “Dog barking in the park,” the model will put “dog” into the “source” node, and “park” into “place.” If some nodes are empty—say, no one wrote what the “ground” was—the model can be asked to guess (for example, “What is the ground for a barking dog in a park?”). This way, the model fills in gaps using its broad knowledge.
But the system doesn’t stop there. It uses the LLM again to check the links between nodes. For example, does it make sense to connect “dog” as a source to “grass” as a ground? The LLM is prompted to verify these links, like a fact-checker. This step is key—it helps stop the system from making up bad links or “hallucinating.” The result is a knowledge graph that is both rich and reliable.
The finished, validated knowledge graph can now be used in many ways. For example, it can help with:
Audio Classification: The knowledge graph lets the system spot sound events and tag them more accurately. It can see not just what the sound is, but how it fits into a bigger story.
Audio Captioning and Retrieval: The graph can power smarter search. If you want to find all clips with “dogs barking outdoors,” the system can use the graph to match both “dog” and “outdoors,” even if the words used in the caption are different.
Representation Learning: The knowledge graph can be turned into a matrix that helps train machine learning models. These models can learn the hidden structure in sounds and their meanings, making them smarter for tasks like question-answering about audio.
Contrastive Learning and Clustering: The graph can help group sounds in meaningful ways, like all “happy” sounds, or all “indoor” sounds, giving better control over learning and search.
Prompt Engineering and Generative Models: The graph can help craft better prompts for LLMs or generative AI. For example, it can help generate audio or text that fits very specific needs (“Make a sound of a metal door closing in a hallway”).
The invention can be put into practice in different ways: as a software method, as a hardware system, or as code stored on a computer-readable medium. It can work in the cloud, on a server, or even in a personal device.
Let’s walk through an example to make it clear. Imagine you have a clip of audio: a dog barking as someone knocks on a door. The metadata says, “Dog barking and door knocking.” The system picks nodes: “source,” “place,” “ground,” and “path.” The LLM fills in “dog” and “door” as sources, “outdoors” or “indoors” as places, and guesses “wood” as the ground for knocking. It checks if these links make sense. Now, you have a graph that shows not just the labels, but how the sounds relate—“dog barking” from “outdoors,” “door knocking” on “wood,” and so on.
This graph can help you search for all clips where a dog barks on grass, or where knocking happens on wood. It can even help generate new audio or captions, with control over each part (“change ‘wood’ to ‘metal’ and make a new sound”).
The key innovations are:
1. Using both audio and text together, not just one or the other.
2. Automatic building of knowledge graphs with the help of LLMs, reducing the need for human labeling.
3. Filling in missing data by having the LLM reason about the context.
4. Verifying the links with the LLM to prevent made-up or weak connections.
5. Making the final graph usable for many downstream jobs: search, tagging, generation, learning, and more.
This approach is more robust, less labor-intensive, and much smarter about meaning and context than older methods. It lets computers not only label sounds, but understand and use them in rich, human-like ways.
Conclusion
This patent shows a big step forward in how computers can connect audio and text. By using knowledge graphs and large language models together, the system can build maps of meaning from sound and words. It can fill in gaps, check its own work, and help with many important jobs—like searching, tagging, and even making new sounds or captions.
For businesses, this means less time spent on manual labeling, better search and tagging, smarter assistants, and richer user experiences. For researchers, it opens new doors in AI and machine learning. And for everyone, it means computers that understand sound more like people do.
As the world gets noisier and more connected, systems that can truly “listen” and “understand” will become more valuable. This invention shows how that future can be built—step by step, sound by sound, word by word.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250335705.

