Unified Log Dashboard Streamlines Debugging and Compliance for Cloud Cluster Operations

Invented by Tiwary; Vishal, Shilane; Philip, Verma; Shiv Prasad
Cluster systems have become the backbone of modern data storage and processing. But as these systems grow, so do their challenges—especially when it comes to finding and fixing problems fast. In this article, we will break down a new patent application for centralized log visualization in clusters, showing you why it matters, how it builds on past ideas, and what sets it apart. If you manage or design large-scale systems, this guide will help you understand how these tools can make your work easier and more secure.
Background and Market Context
To understand this invention, imagine a busy city where every street, building, and car needs to be watched and recorded. Now, think of a cluster system as that city—a place with many computers (nodes) working together to store and process lots of information. Each node runs different apps in containers, and every action is logged. These logs are like a diary for each part of the system, recording everything that happens.
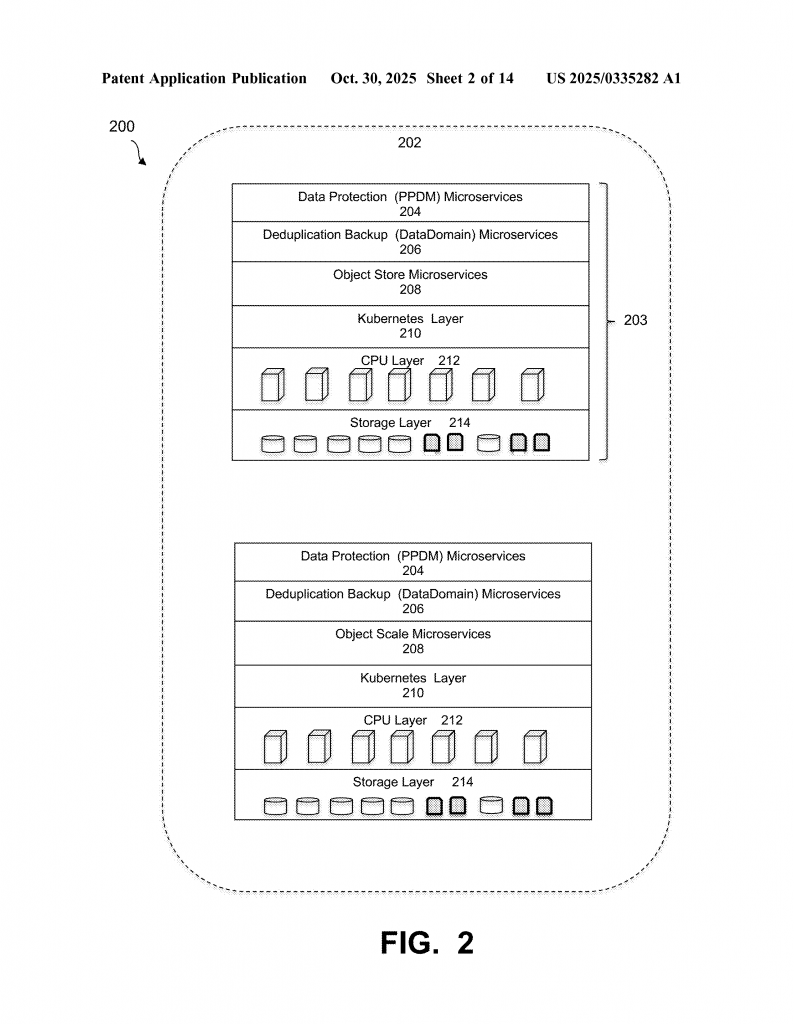
Cluster systems are used everywhere, from cloud storage to enterprise backups. They help businesses keep their data safe, restore files, and handle huge amounts of information. The Santorini file system, for example, is a cluster network that spreads data across many machines. It uses fast storage and smart ways to keep track of data, so nothing is lost even if something fails. Other products, like Data Domain, use deduplication to save space by not storing the same information twice.
But as these systems get bigger, the number of log files grows too. Every app, service, and piece of hardware writes its own logs. If something goes wrong—say, a server crashes or someone tries to break in—these logs are the first place to look. The problem is, there can be thousands or even millions of logs spread across different places, all in different formats. This makes it very hard and slow to find the root cause of an issue.
Businesses need to solve problems quickly to avoid losing money or putting data at risk. That’s why vendors who sell these cluster systems must also offer good support. When a user asks for help, the vendor often asks for a “support bundle”—a package with all the logs and data needed to understand what went wrong. But making and sending these bundles is tricky. The logs have to be found, collected, sometimes filtered to avoid sending too much private data, and then sent to the vendor.
The stakes are high, not just for fixing bugs but also for following rules. Many companies and governments have strict audit requirements. Logs must be kept safe, complete, and easy to check. Failing to keep proper logs can lead to big fines or worse. So, businesses are looking for smarter ways to gather, organize, and look at all these logs. They want simple visual tools that show what happened and when, without needing to dig through hundreds of files.
This is where the invention comes in. It offers a way to bring all the logs together, turn them into a clear format, and show them in one place. This helps users, vendors, and auditors find and solve problems faster, with less guesswork and less risk.

Scientific Rationale and Prior Art
Before this invention, managing logs in cluster systems was a tough job. Let’s look at the main ideas that have been used and where they fall short.
First, each service or app in a cluster writes its own logs. Sometimes these logs are saved on the same machine, sometimes in a central place. Most logging systems just collect these files, one by one. Some use sidecar containers—extra parts that sit next to the main app and help copy logs to a safe place. Others use tools like Fluentbit to grab logs from standard output and store them. While these methods work, they often miss logs if a machine goes down or if a service restarts in a different place. Logs can also get lost if the storage fills up or if something breaks.
Some systems try to solve this by using persistent volumes (PVs), which are storage spaces that stay even if a container stops or moves. Logs from important services are saved in their own PVs, while less important logs go to a shared PV. This helps keep key logs safe, but it adds complexity. Each service has to know where to write its logs, and someone has to keep track of all the PVs.
When it comes to looking at the logs, most tools just let you open a file and read it. If you want to find a problem, you have to know where to look. Some tools offer basic search, but they don’t help if the logs are in different formats or spread across many machines. To make things worse, logs from different vendors or old apps might use their own formats, making it even harder to make sense of everything.
Vendors have tried to help by asking users to send “support bundles” with all the logs and system info. But creating these bundles is slow and manual. Users might send too much or too little data, and sensitive information can get mixed in by mistake.
Audit logging adds more challenges. For legal reasons, some logs must be kept safe, unchangeable, and easy to check. This means storing logs with cryptographic hashes, sending copies to outside servers, and making sure only the right people can see or change them. Standard formats, like EL1, set rules for what must be logged and how.
Some prior systems try to use dashboards to show logs, like OpenSearch or Logstash. These tools can help visualize data, but only if the logs are already in the right format. Most clusters don’t do this on their own, so someone has to write scripts or use manual steps to convert logs before they can be shown in a dashboard.
In short, the old ways require too much manual work, are prone to mistakes, and don’t scale well as clusters get bigger. There is a real need for a system that can:
– Collect logs from all nodes and services, even if some machines fail
– Store logs from important parts in safe places
– Turn logs into a clear, common format
– Index and search logs quickly
– Show logs in a visual, easy-to-use dashboard
– Support audits and follow rules
– Send logs to vendors for support
The new invention builds on these needs and fills the gaps left by earlier ideas.
Invention Description and Key Innovations
This invention is all about making log management in cluster systems easy, fast, and reliable. Let’s walk through how it works and what makes it stand out.
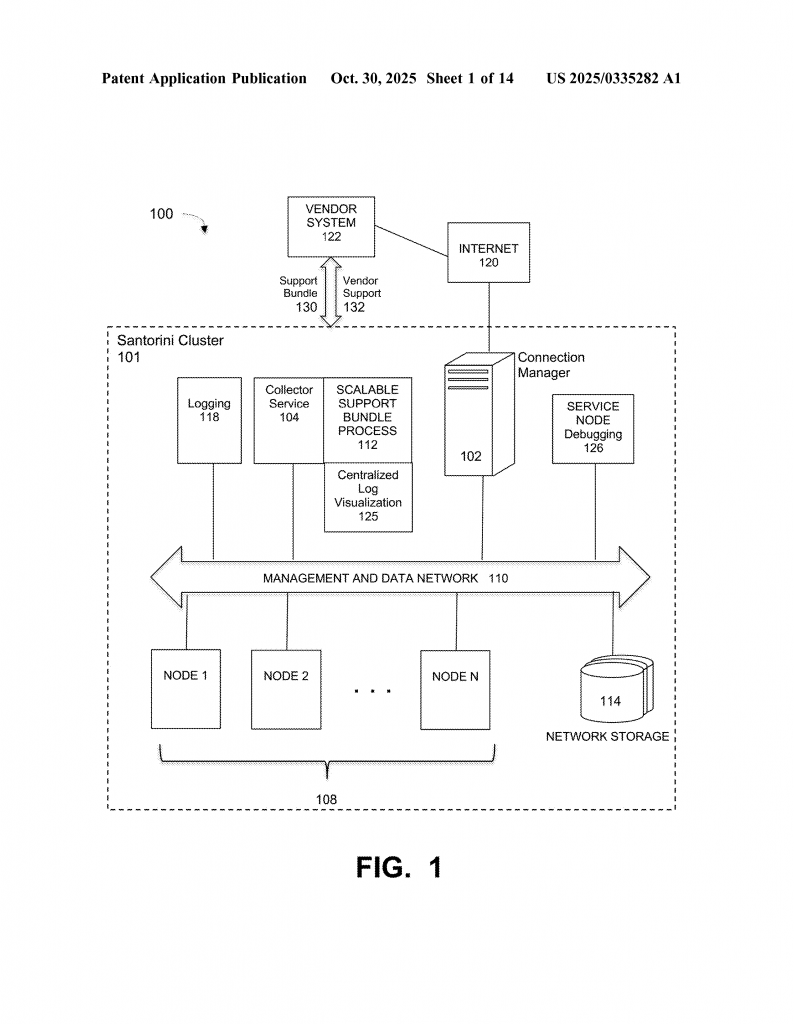
The main idea is to collect logs from every node in the cluster, no matter what app or service made them. The system uses a collector service to grab these logs, even while the system is running. Logs from important components—like the ones that handle storage or security—are saved in their own persistent volumes. This makes sure that even if one part fails, the logs are still safe. Less important logs can go to a shared storage space, which helps save room.
Once the logs are collected, the system gives each log file a unique index. Think of this like giving every diary entry its own number and label. This makes it easy to find and search for any log later, no matter where it came from.
The logs are then sent through a pipeline that turns messy, unstructured text into neat, structured data. The pipeline, which can use tools like Logstash, reads each log, picks out important details—like the time, what service made it, how serious it is, and what happened—and puts them in a standard format. This is key, because logs from different services might look very different at first.
After the logs are structured, they are loaded into a fast search engine, like OpenSearch. This engine builds a searchable index of all the logs, so you can look for any word, error, or pattern in seconds. This makes it possible to spot problems, track events, and even see trends over time.
But the real magic is in how these logs are shown to the user. The system includes a graphical dashboard—a web page or app—that lets users see all the logs in one place. You can view a histogram showing how many events happened over time, zoom in on a specific period, and click to see details about each event. Want to see all errors from a certain service in the last hour? Just type in a query and the dashboard shows you exactly what you need. Each log entry can show the date, log ID, message, and even which file it came from. This makes debugging much faster and less stressful.
If you need to send the logs to a vendor for support, the system can package up the structured logs and send them securely. The same goes for audit logs—these are kept safe, with cryptographic checks to make sure they aren’t changed. You can even send copies to outside servers if you need to follow strict rules. The system can also raise alerts if something goes wrong with the logging process, and can refuse to do actions if they can’t be logged (very important for security).
Another helpful feature is the use of trace IDs. These are unique tags given to each job or operation in the system. As the job moves through different services, the trace ID stays with it. This means you can follow the whole story of an event across every log, even if it jumps between different nodes or apps.
The system is smart about saving space. Old log files are rotated and deleted as needed, following policies set by the user or vendor. You can choose how long to keep logs, how much space to use, and which services get the most attention.
Finally, everything is designed to be scalable and automatic. The collector can grab logs from many nodes at once, using a coordinator-worker design. This means you can use the same system whether you have ten nodes or a thousand.
What really sets this invention apart is how it brings all these pieces together. It doesn’t just collect logs, or just index them, or just show them in a dashboard—it does all of these, in a way that is automatic, scalable, and easy for users and vendors. It works with new and old apps, different vendors, and can be used on-site or off-site. It supports debugging, audits, and real-time monitoring, all from one place.
In summary, the invention offers:
– Automatic log collection from all nodes and services, with safe storage for key logs
– Unique indexing for every log file, making searching fast and easy
– A pipeline to turn all logs into a clear, structured format
– A visual dashboard for easy analysis, searching, and debugging
– Support for vendor debugging and strict audit rules
– Trace IDs to follow jobs across the whole system
– Flexible, scalable design that works for any size cluster
This combination means that cluster systems can be more reliable, secure, and easy to manage. Problems are found and fixed faster, audits are easier, and users spend less time digging through endless files. It’s a big step forward for anyone running large, complex systems.
Conclusion
Cluster systems are growing in size and importance, but managing and understanding their logs has become a real challenge. This patent application offers a new solution that brings together log collection, storage, indexing, structuring, and visualization in one seamless system. By making it easy to see everything that happens in the cluster, users and vendors can solve problems faster, keep data safer, and meet audit needs with less effort. For businesses and IT teams, this means more uptime, better support, and peace of mind. If you work with clusters or large-scale storage, keeping an eye on these innovations could make your job much simpler and more effective.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250335282.

