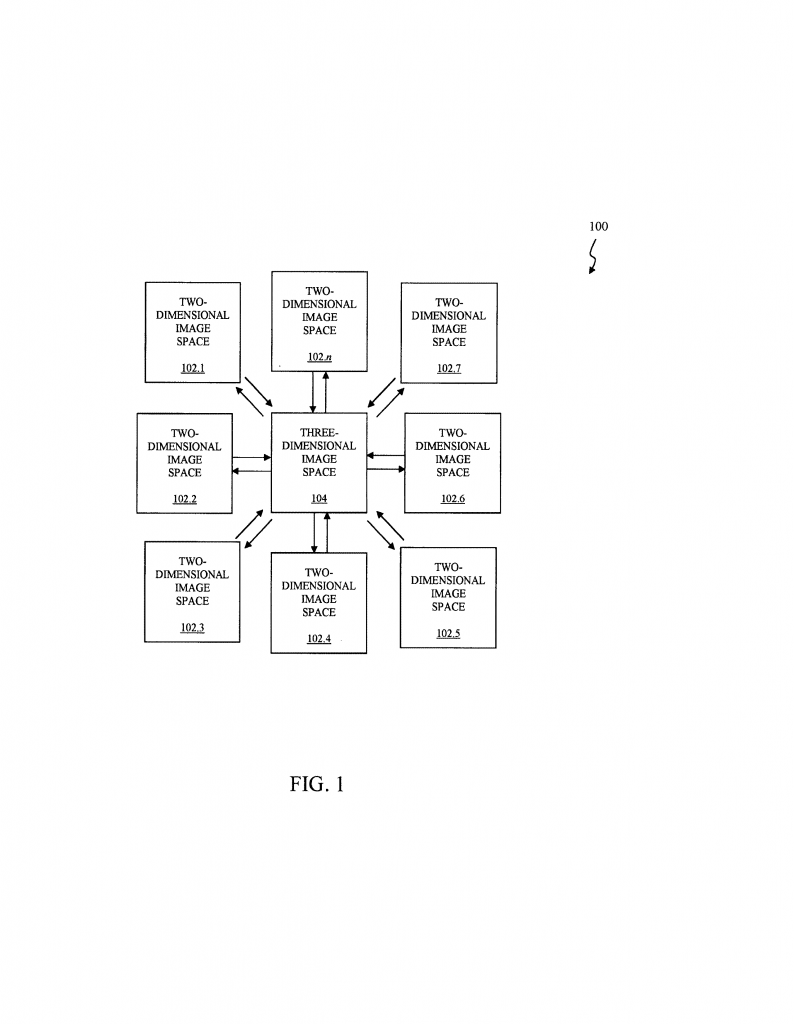
Transforming 2D Photos with 3D Imaging for Next-Gen Visual Applications in Media and Design

Invented by NOLAN; William Andrew, ROMASZEWICZ; Michael, Sphere Entertainment Group, LLC

Digital images are everywhere. From the photos on your phone to the videos that stream on giant screens, images bring stories to life. But behind the scenes, there is a hidden world of computer tricks that help these images look right, no matter what device or display you use. Today, we are going to walk through a new way of changing images from one type to another using a smart process called three-dimensional (3D) image transformation. This is based on a recent patent application, which opens the door to faster, easier, and more flexible ways to change images for all kinds of uses.
Background and Market Context
To understand why this new 3D image transformation matters, let’s start with the world of media and entertainment. The United States has the biggest media industry in the world, making up about a third of the global market. This industry covers everything from movies and sports to concerts and theater shows. Every event uses special graphics—like pictures, animations, and videos—to make the experience more exciting and real for viewers.
Imagine a concert with huge screens or a sports game with instant replays and special effects. These visuals are made using different types of image formats. For example, a video from a camera might be in a “fisheye” format, which looks like a round bubble. But the computer graphics added later might be in a “flat map” style called equirectangular projection. Combining these images is hard because they use different shapes and layouts.
Until now, changing an image from one format to another meant a lot of hard work. Each type of image format needed its own set of rules and math tricks to turn it into a different format. If you had five different formats, you would need a long list of special formulas—one for each possible pair. This meant more time, more memory, and more chances for mistakes. It also made it hard to add new formats or keep up with new kinds of displays.
As the demand for immersive and interactive media grows—think virtual reality, live events, and social media—companies need a better way to move images between different formats quickly and without losing quality. They want to mix camera footage with computer graphics, share content across platforms, and display it beautifully anywhere, from a phone in your hand to a dome over your head.
This is where the new 3D image transformation steps in. Instead of jumping straight from one format to another, it takes a smart detour: it turns the image into a 3D shape, then turns it back into the new 2D format. This extra step makes everything simpler, faster, and more flexible. It is like using a common language so every format can talk to every other one, without needing a separate translator for each pair.
By solving this problem, the new approach makes it easier for companies to create amazing visuals, adapt to new display types, and give viewers a more immersive experience. In a world where content moves across screens and devices every second, this kind of smart image transformation is a big leap forward.
Scientific Rationale and Prior Art
Let’s look closer at how images are changed from one format to another, and why this new way is better.

In digital graphics, an image is made up of many tiny dots called pixels. Each pixel has a position, like an address, in a two-dimensional (2D) grid. But not all images use the same grid. Some images are flat, like a photo from a regular camera. Others are curved or wrapped, like a picture taken with a fisheye lens or mapped onto a sphere.
When you want to use images together—for example, adding special effects to a live video—you need to make sure their grids match. This is called image projection. The traditional way is called “direct two-dimensional projection.” Here, computers use a special formula (called a projection function) to turn the pixel positions from one format into positions in another format.
But there is a catch: if you have many different formats, you need a separate formula for every pair. For five formats, that means 20 formulas for going from one format to another, plus another 20 to go back. Every time a new format comes along, you need even more formulas. This makes the system slow, clunky, and hard to update.
Some of the common projection types are:
- Equirectangular projection: A flat map of a sphere, like maps of the Earth.
- Fisheye projection: A round, wide-angle view, like looking through a peephole.
- Cubemap projection: The image is split into the faces of a cube, often used in 3D games.
- Latitude/longitude projection: Another way to flatten a sphere onto a grid.
Old systems needed a special formula for each way two formats could connect. Each formula handled the math needed to map every pixel from one grid to another. If you wanted to add a new projection, you needed to program new math for every possible connection with all the old ones. This was not only slow, but also wasted memory and made the system fragile.
Some advanced graphics tools tried to fix this by using intermediate steps, but they still required lots of formulas or suffered from slow performance. They also did not scale well to very large images or live video.
To make matters worse, the traditional method handled each pixel one at a time. For big images or video, this meant lots of repeated work and slow results, especially when running on regular computer chips (CPUs).
What was really needed was a smart way to handle all image types using fewer formulas, less memory, and faster math. This would make it easier to add new formats, speed up the process, and work better on powerful graphics chips (GPUs) that can handle many calculations at once.
The new invention described in the patent application does exactly that. It introduces a clever shortcut: instead of jumping directly from one 2D image format to another, it uses a 3D “universal space” in the middle. Every image is first mapped into this 3D space (using a forward projection), and then mapped from the 3D space into the target 2D format (using a reverse projection). Because every format only needs to know how to talk to the 3D space, you only need two formulas per format—one for in, one for out. This cuts down the total number of formulas by a huge amount.
This approach is not only simpler, but also much faster, especially when using parallel computing on graphics chips. It can handle big images and many formats without slowing down or using too much memory. It is also flexible: if a new format comes along, you just add two new formulas, not a whole web of connections.
By understanding how traditional image projection works, and why it struggles with scale and flexibility, we can see why the 3D image transformation method is a big improvement. It solves key problems that have held back media production and display technology for years.
Invention Description and Key Innovations
Let’s break down what the patent application introduces and why it is a breakthrough.
At its heart, the invention is a computer system and a new method for changing images from one 2D format to another, with a 3D space in the middle. Here’s how it works in simple steps:
1. The system stores an input image in a first 2D format, such as a fisheye, equirectangular, or cubemap format.
2. It uses a processor (like a CPU or GPU) to read the image and run special instructions. These instructions first map the 2D pixel positions into a 3D space. This 3D space can be a sphere, cube, cylinder, or any shape that matches the image’s needs.
3. Next, the system maps these 3D positions into new 2D positions for the target format. For example, it might flatten a sphere onto a grid for a latitude/longitude format.
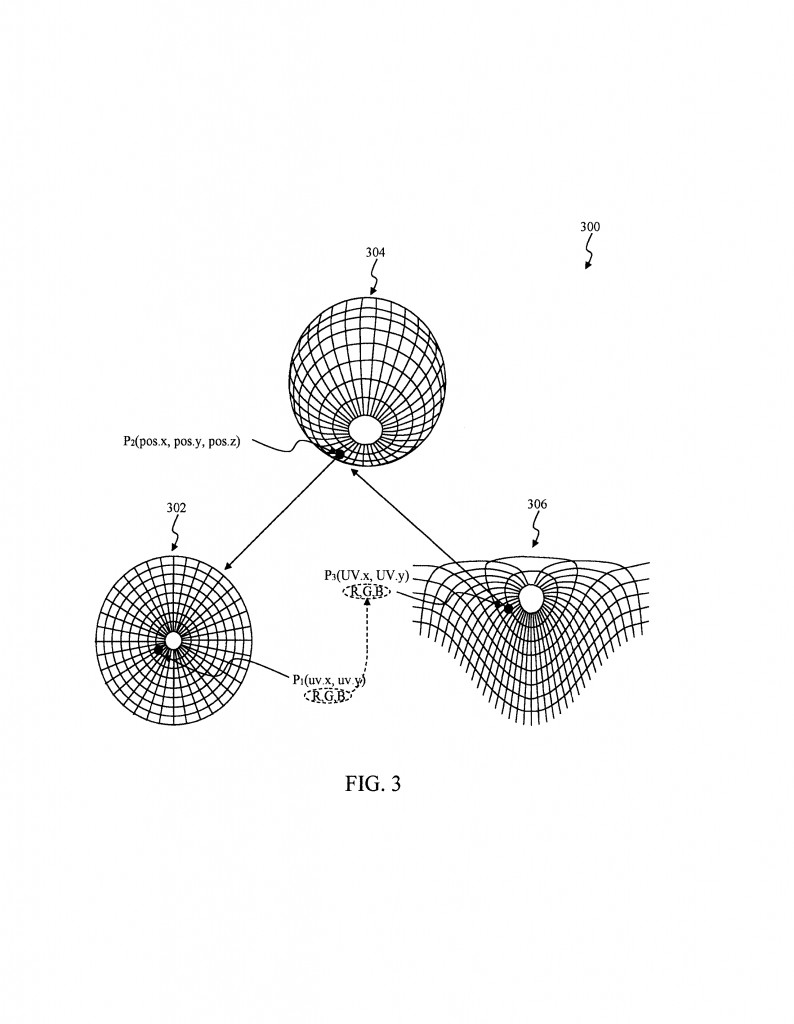
4. The system then assigns color or brightness values from the original image to the new positions, making sure the output image looks correct in the new format.
5. Finally, the output image is shown or used wherever needed: on a display in a concert hall, in a virtual reality headset, or as part of a live video stream.
The key innovation is using the 3D space as a “universal translator.” Each format only needs to know how to go to and from the 3D shape, which means adding new formats is easy—just add two formulas (in and out) for the 3D link.
The patent details several types of projection functions:
– Mathematical forward projection functions turn 2D positions into 3D positions. For example, a fisheye image’s pixels are mapped onto a sphere’s surface.
– Mathematical reverse projection functions take points on the 3D shape and find their positions in the new 2D format. For example, flattening the sphere’s surface back into a rectangle.
The invention supports many common projection types, and the math for each is included in the patent. This allows for easy transformation between equirectangular, fisheye, cubemap, and other formats. The system can work with images from cameras, computer graphics, or even live feeds from the internet.
Another important point is speed. Because the mapping can be done in parallel—many positions at once—using modern graphics chips, the system is much faster than the old way. The time it takes does not go up as the images get bigger. This is a huge advantage for high-resolution video or live events.
The system also uses less memory, since it does not need to store lots of special formulas or intermediate results. This makes it ideal for use in cloud computing, mobile devices, or any place where resources are limited.
The patent also covers how this technology can be used in real venues. For instance, a concert hall or sports arena can use a computer system to grab images (like artwork or video), change them to match the shape of their displays (maybe a dome or curved wall), and show them in perfect quality. The same system can pull images from the web, social media, or live cameras and make them look right on any screen.
The claims in the patent spell out the details: the computer system, the method for transforming images, the types of projections it supports, and how it can be used in venues or with different types of displays.
In summary, the key innovations are:
– Using a 3D space as a universal mapping link between 2D formats.
– Simple, scalable projection functions for each format.
– Fast, parallel processing for big images and live video.
– Easy addition of new formats with minimal extra work.
– Support for a wide range of applications, from live events to social media and VR.
This invention makes image transformation simpler, smarter, and ready for the future of digital media.
Conclusion
The world of digital imaging is always changing, with new formats, devices, and experiences popping up every year. The new three-dimensional image transformation method described in this patent application is a big step forward. By using a 3D space as a bridge between image formats, it solves problems of speed, flexibility, and scalability that have held back media creators and event venues for years.
This approach means no more tangled web of special formulas for every format-to-format conversion. Instead, every format just learns how to talk to the 3D space, making it easy to add new types or update old ones. The system works fast, uses less memory, and is perfect for modern graphics hardware.
In the end, this technology will help create smoother, more immersive experiences for viewers everywhere—on phones, in stadiums, at home, or in virtual worlds. As the need for flexible, high-quality image transformation grows, this invention stands out as a practical, powerful solution that is ready to keep up with the future of digital media.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250363735.

