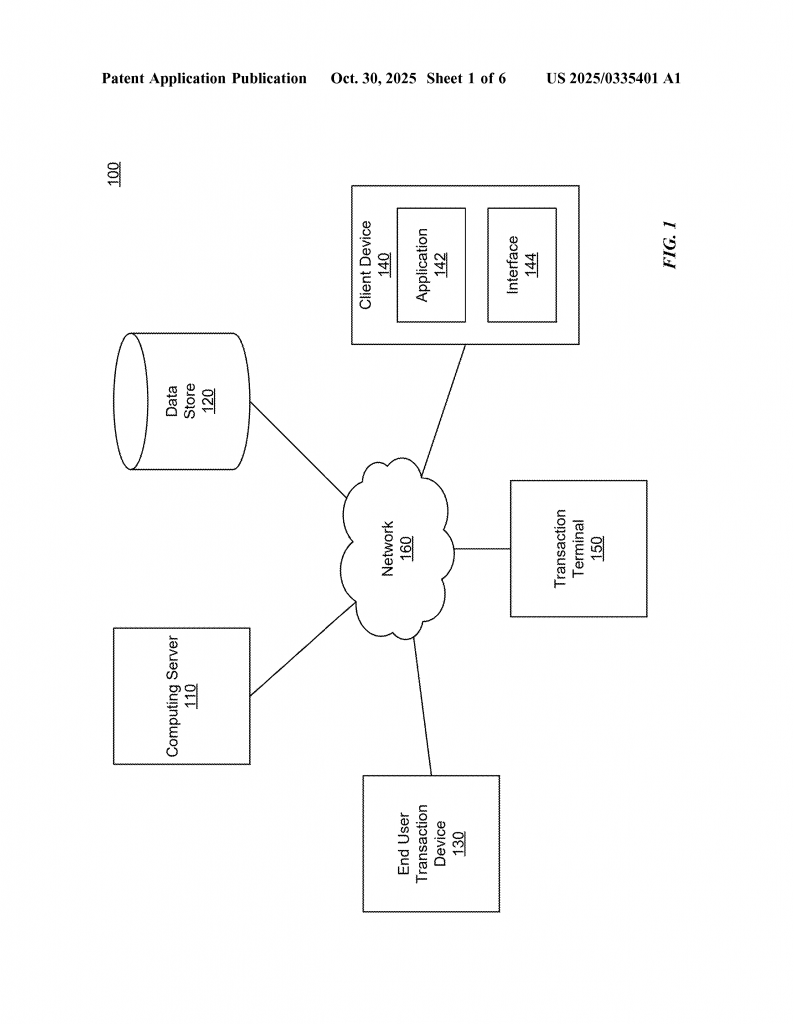
Transform Unstructured Data into Business-Ready Insights with Advanced AI Conversion Tools

Invented by Sengottuvelu; Rahul Gunasekaran

Understanding how computers can turn messy, unorganized information into clean, sorted records is important for many businesses today. The patent application we will discuss introduces a new way to do this by combining language models (like those behind AI chatbots) with rules that make sure everything fits the right structure. This article will break down the big ideas behind this invention, look at what came before, and then explain what makes this new approach special.
Background and Market Context
In today’s world, companies collect huge amounts of information. Some of this information is neat and organized—think of spreadsheets or databases. But much of it is not: emails, receipts, notes, and reports are examples of what we call “unstructured data.” Unstructured data does not fit into tables or forms easily. This makes it hard for computers to read, search, and use.
Businesses want to use all their information to make better choices, help their customers, and save money. But working with unstructured data is a big problem. If you can’t turn it into an organized form, it’s almost impossible to analyze it or use it for automation. For example, a company might have hundreds of receipts from employees for travel. Some receipts are digital, some scanned, some typed up in emails. How do you keep track of what was spent, by whom, and on what?
The usual way to solve this problem is to use special computer programs that try to pull out important details from messy text. These might look for dates, names, or dollar amounts. Some use rules that people write by hand. Others use machine learning, which means they learn patterns from lots of examples.
But these methods often fall short. The rules can break if the format changes. Machine learning models need lots of labeled examples to learn from, which takes time and effort to make. Worse, these systems can get confused if the data looks a little different from what they saw during training. This leads to mistakes and means people still need to check and fix the results.
As more companies move their operations online and deal with new kinds of documents and formats, the need to automate this process grows. There is a demand for smarter, more flexible ways to turn unstructured data into neat, structured records that computers and people can trust. That’s what this patent is aiming to address: a system that can take messy data and, using clever AI and rules, produce clean, usable records every time.
Scientific Rationale and Prior Art

Before this invention, there were two main approaches to extracting structured data from unstructured sources.
The first approach depends on “rule-based systems.” These are like sets of instructions that tell the computer what to look for. For example, a rule might say: “If you see the word ‘Total’ followed by a number, that number is the total amount.” If the receipt says “Total: $15.99,” the rule works. But if it says “Amount Due: Fifteen dollars and ninety-nine cents,” the rule fails. Rule-based systems are simple, but they break easily when the format changes, and they require a lot of maintenance as documents evolve.
The second approach is “machine learning,” especially using models that recognize named entities (like names, places, dates) in text. Developers train these models with many examples, showing them what to look for. Over time, the model gets better at finding these pieces in new documents. However, machine learning requires large amounts of labeled data to work well. Creating these labels is hard and expensive. Plus, when the data is very different from what the model saw in training, its accuracy drops.
Recently, more advanced systems use “large language models” (LLMs) like those behind chatbots. These models are trained on huge amounts of text and can generate sentences, summaries, and answers. Some developers try to get the language model to output structured data, like filling out a form or making a JSON file. They often do this by giving the model special instructions, called “prompts.” However, even with careful prompts, these models sometimes make mistakes—they might use the wrong format, miss a field, or add extra information.
To fix these errors, people sometimes write extra code to “clean up” the results after the fact. This is called “post-processing.” But it’s not perfect. The system still might produce records that do not fit the needed structure, and fixing these mistakes takes time.
Some researchers have tried to guide language models more directly. For example, they use “constrained decoding,” a process that tries to limit the model’s choices so it does not produce impossible results. Yet, current methods are either too rigid (they can’t handle all the cases in real-world data), or too loose (they let mistakes slip through).
What makes this new invention different is how it combines language models with a flexible set of rules—represented by something called a “finite state machine.” This mix allows the system to use the power of language models to understand text, but also to make sure the output always fits a structure, like a database or a JSON file. The invention can adapt to different data formats and rules, making it more reliable and easier to use in different settings.
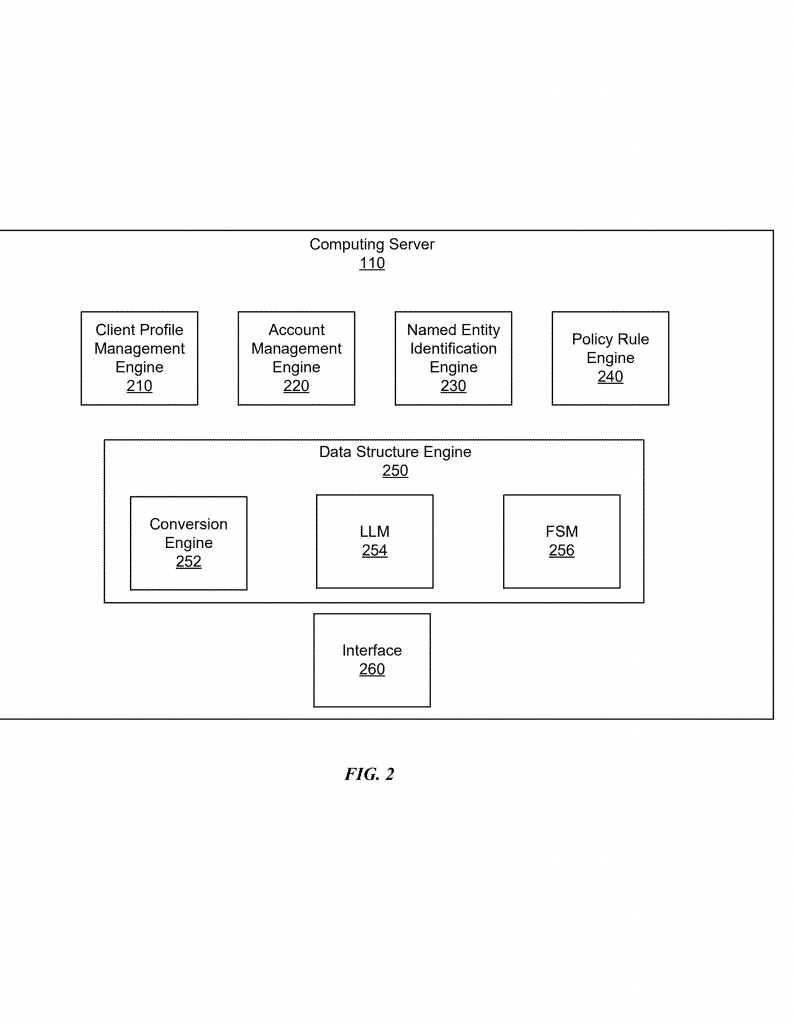
Invention Description and Key Innovations
At its heart, this invention is about taking a set of rules that describe how structured data should look, and using those rules to “steer” a language model as it reads unstructured data and writes out a clean, structured version.
Let’s break down how this works in simple steps:
1. Custom Schema Input: The process starts when someone provides a “custom-defined data schema.” This schema says what the final structured data should look like. For example, if you want output in JSON format with fields like “firstName,” “lastName,” and “amount,” you define that up front.
2. Schema as Rules (Finite State Machine): The system turns the schema into a set of rules. These rules are built into something called a finite state machine (FSM). Imagine a FSM as a flow chart that says, “After you see a field name, expect a colon. After a colon, expect a value. After a value, expect a comma or a closing brace.” This FSM knows what’s allowed next at each point.
3. Language Model Integration: The system uses a large language model (LLM) that can read and understand text. But, instead of letting the LLM pick any next word, the FSM restricts its choices. At each step, the FSM checks, “Does this next word or symbol fit the schema? If not, don’t allow it.”
4. Token Scoring and Selection: When the language model generates possibilities for the next word or symbol (these are called “tokens”), each one is given a score. Normally, the LLM picks the highest-scoring token. But here, if any token would break the schema rules, its score is changed to zero, so it won’t be chosen.
5. Building the Structured Data: This process repeats for every new piece of output. The system keeps moving through the FSM, which shifts its rules as more of the output is written. If the system ever tries to make a choice that breaks the schema, the FSM steps in and blocks it.
6. Handling Policy Rules and Notifications: The system can also check the structured data against extra business rules. For example, if a company’s policy says travel expenses over $75 must be itemized, the system looks for this. If the data doesn’t match the rules, the system can alert the user, ask for more details, or block the transaction.
This approach is clever for several reasons:
– It makes the output reliable. No matter what the original data looks like, the FSM ensures that the final result always fits the needed structure.
– It is flexible. By changing the schema and the FSM, the same system can handle different formats, like JSON, XML, HTML, or SQL.
– It reduces manual work. Because the system catches mistakes early, there’s less need for people to fix things afterwards.
– It adapts to new data. The language model can handle different kinds of input, and the FSM makes sure the output is always correct.
– It improves compliance. By checking business rules, the system helps companies follow their internal policies without extra effort.
Technically, the most important part is how the FSM and LLM work together. At each step, the FSM looks at what has already been written and decides what can come next. If the LLM suggests something outside these options, its score is set to zero and it cannot be picked. This “logit bias masking” makes the language model follow the rules strictly. The process continues until the structured data is complete and matches the schema exactly.
The system can also give feedback to users. If a receipt is missing a required item (like an itemized list for a big expense), the system can send a message asking for more information before moving forward.
The patent also covers the use of this method in software, servers, and as part of products businesses can buy or use in the cloud. It can work with many different types of data and schemas, making it useful for banks, retailers, hospitals, or anyone who needs to make sense of messy information.
Actionable Takeaways
If you want to put this invention to use, here’s what you would do:
– Define the structure you want your data in (the schema).
– Set up the system so the schema is turned into FSM rules.
– Feed unstructured data into the system and let the LLM and FSM work together to write out the structured version.
– Add your business policies if you want the system to check for compliance and send alerts.
– Use the structured output for analysis, automation, or auditing.
Conclusion
Turning unstructured data into structured records is a challenge for many modern businesses. This patent introduces a smart, flexible way to do it: by combining the language understanding of LLMs with the strict rule-following of finite state machines. The result is a system that can take messy, real-world data and reliably produce clean, organized outputs, no matter the format. It can also help enforce business policies and alert users to problems before they grow. As companies handle more and more digital information, solutions like this will be key to making sure nothing falls through the cracks and that data remains useful, trustworthy, and ready for action.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250335401.

