SYSTEM AND METHOD FOR IDENTIFYING A REQUEST OF A SERVICE IN CLOUD COMPUTING
Invented by ABITBOUL; Roi, FRANCO; Guy, DANIELYAN; Roland, YAIR; Omer, R.C.Raven Cloud LTD
In the world of cloud computing, it can be hard to see what is really happening with all the things that run inside. This new patent shows a way to use machine learning to spot important requests as they happen. Let’s dive in and see why this is so needed, how the science fits in, and what makes this patent truly stand out.
Background and Market Context
Cloud computing has changed the way we use technology. Instead of owning lots of computers, businesses can rent what they need from the cloud. They get storage, servers, databases, and more, paying only for what they use. This is cheaper, faster, and easier to manage than the old way.
But there’s a catch. All this renting adds up. Cloud bills can get very big, very fast, especially for companies that run big software or websites. Much of this cost comes from running “instances”—the cloud’s way of saying computers you don’t see. Every second these instances run, companies pay. If the software running on them is slow or gets stuck, the bill goes up.
To lower costs, businesses have tried all sorts of things. They buy reserved instances that are cheaper over time, or use “spot instances” that are cheaper but go away suddenly. They resize computers to only what’s needed. These tricks help, but they don’t fix the real problem if the software itself is not working well.
The heart of the problem is software bottlenecks. Some parts of a program use up more power than needed or get stuck waiting. Finding these slow spots is hard, especially in cloud systems where things happen across many computers at the same time. The cloud splits up work, and events can happen out of order or in lots of different places. This makes it tough to see where requests start, where they end, and which parts are slow.
If you can’t see what’s really happening inside, you can’t fix it. That’s why tools that help find and follow requests as they happen in the cloud are so important. They let businesses spot the slow parts, fix them, and save money. But building these tools is tricky, because the data is messy, scattered, and hard to sort.
This is where the patent comes in. It gives a new way to use machine learning—a kind of computer learning from data—to watch what happens in the cloud, group related events, and spot important requests. With this, companies can finally understand what’s going on and make their software run better and cheaper.
Scientific Rationale and Prior Art
Before now, finding requests and slow spots in cloud workloads has been a huge challenge. When a program runs in the cloud, it sends and receives lots of little signals, called events. These can be things like opening a file, sending data, or waiting for a response. In big systems, there can be millions of these every hour, coming from many places at once.
Older tools try to follow these events using simple rules or by looking for special markers that programmers add. While this works in simple systems, it fails in the cloud, where things happen at different times and in different places. Events can get mixed up, lost, or show up out of order. Sometimes, there are no markers at all—just a jumble of raw data.
Other attempts have used basic clustering methods to group similar events or threads. Some cluster by timestamp, thread ID, or event type. But these simple methods run into problems in real cloud systems. They can’t catch the deeper meaning or order of events. They often miss connections, and their results are messy. They also can’t tell which events really matter for performance.
Some recent research has looked at using machine learning models to make sense of logs and traces. For example, transformer models—famous in text and language work—can learn patterns in sequences. But these models are hard to train for cloud events, since the data is noisy and not labeled. Without labels, the models can’t learn what is important and what is just noise.
There are also tools that try to reconstruct requests by matching up clues like thread IDs or socket connections. But in the cloud, the same request might move between threads or even computers. IDs can change, or get reused. This makes simple matching unreliable.
The patent’s approach stands out for a few reasons. First, it doesn’t need special markers or labels to start. It uses the raw events as they come, just like language models learn from text. Second, it uses a smart two-stage learning process. First, it learns to reconstruct sequences (unsupervised learning), so it understands the flow. Then, it fine-tunes itself with some labeled data to tell which events are relevant and which are just noise. This way, the model learns both the patterns and the meaning.
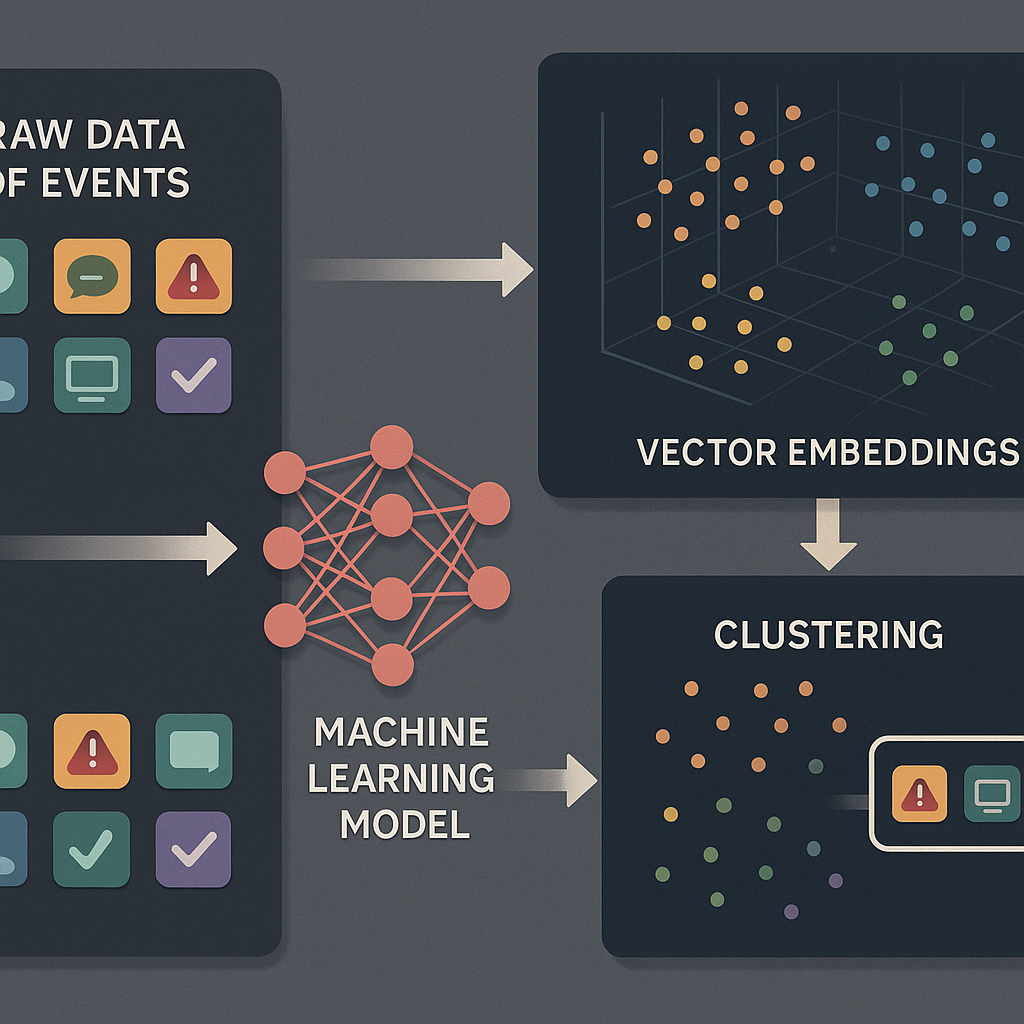
Another key step is using vector embeddings—turning each event into a set of numbers that holds its meaning, position, and context. Events that are similar have embeddings that are close together. This lets the system use advanced clustering (like K-means, BIRCH, or OPTICS) to group related events, even if they happen at different times or places.
By combining these steps, the patent’s method goes far beyond prior art. It can find where requests start and end, group all the right events together, and ignore the junk. It works even in messy, real cloud systems, with no extra help from the programmer. This unlocks real power for optimization and cost savings.
Invention Description and Key Innovations
Let’s look closely at what this patent teaches and how it works in practice.
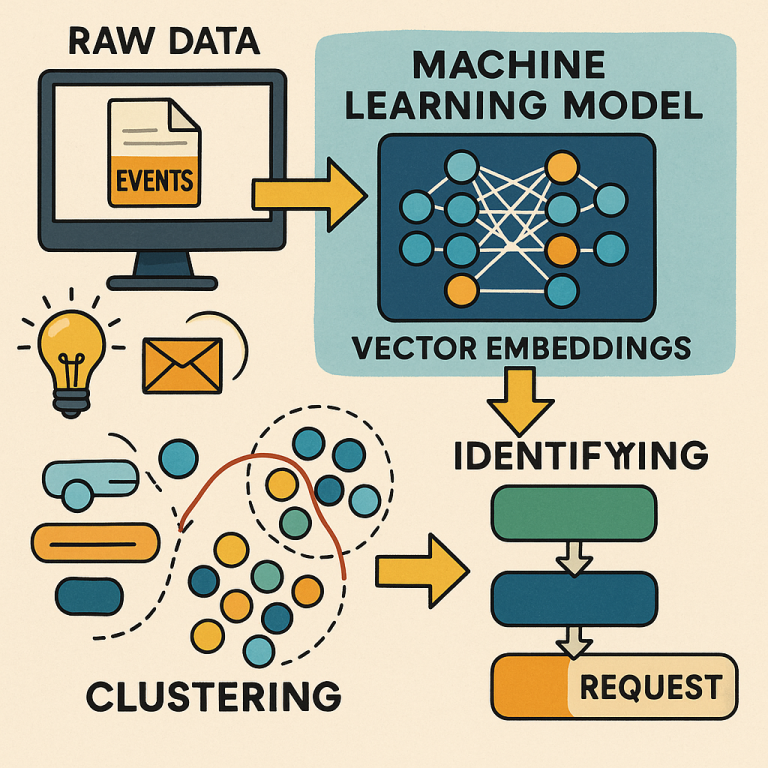
The main goal is to identify requests in a cloud system by looking at raw events as they happen. These requests are sequences of actions that belong together—like a user clicking a button, which leads to many steps inside the cloud. By spotting these requests, you can find where things get slow and fix them.
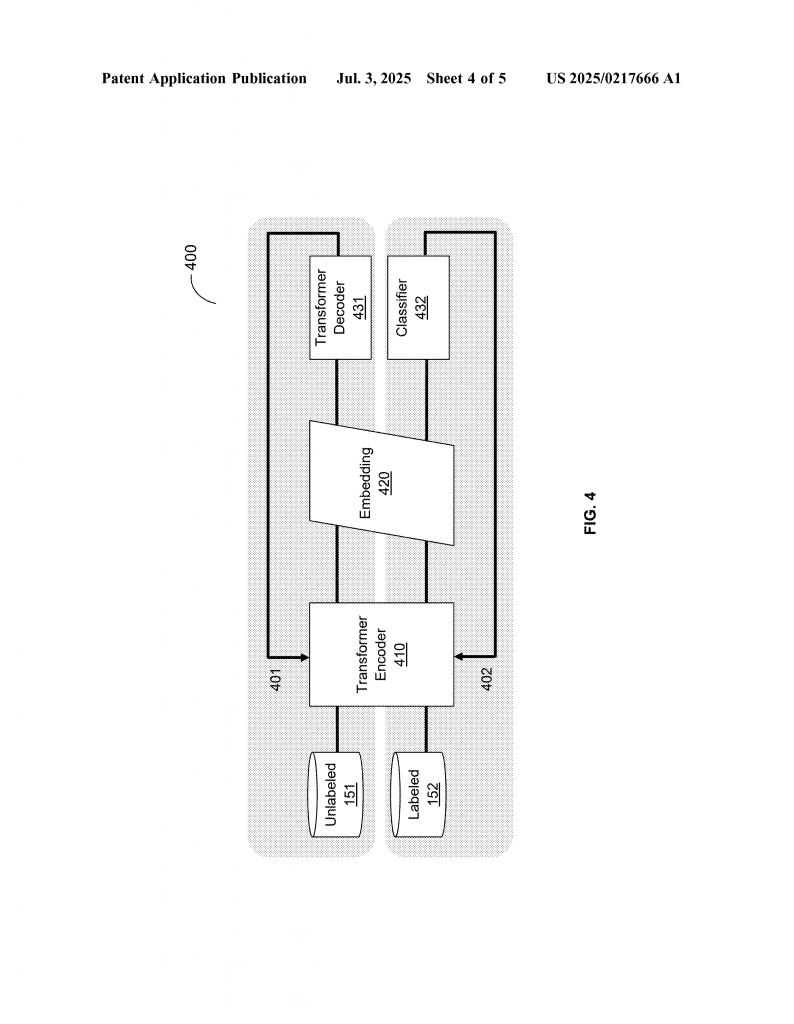
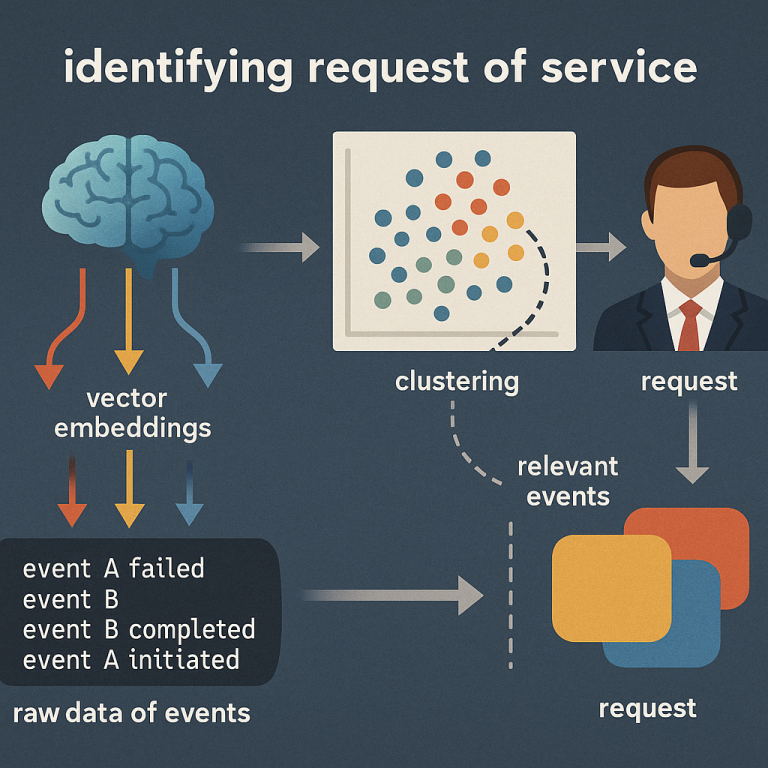
The invention starts with the raw event data. Each event might include details like a timestamp, which thread or processor it ran on, what type of event it was, and other information like file descriptors. This data is collected by small programs (“agents”) running on each cloud computer. The agents gather events as the software runs, either all the time or at set intervals, and send them to a central system for analysis.
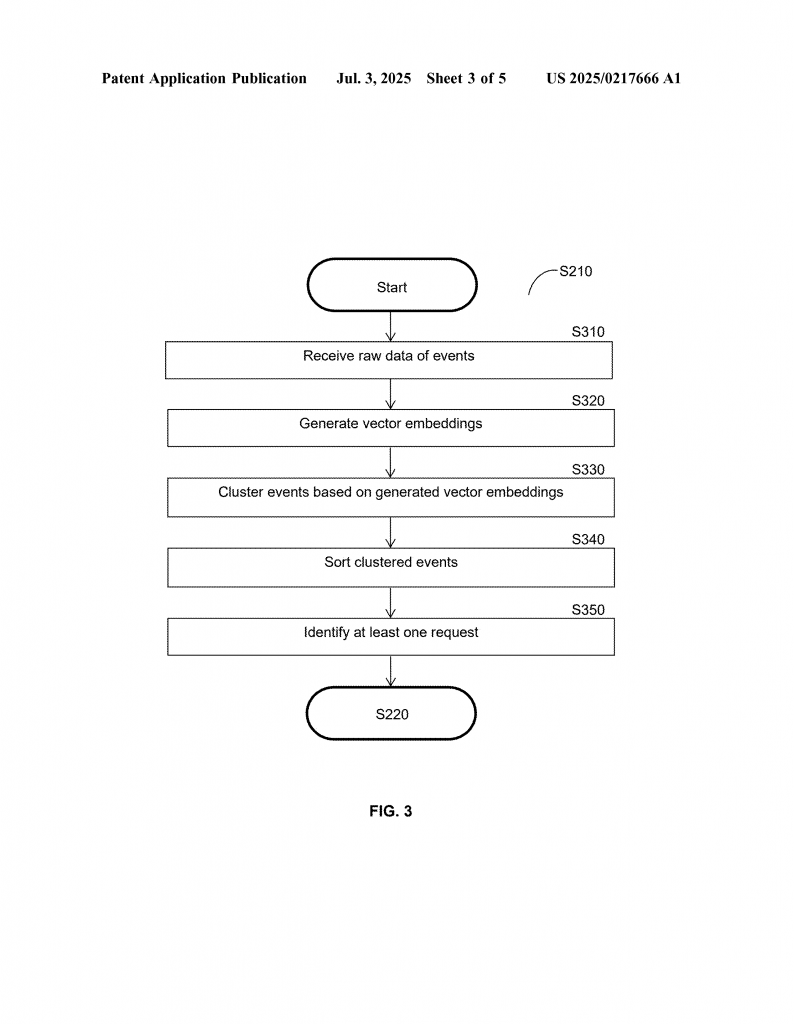
The first big step is to turn these events into vector embeddings. This means each event is changed into a group of numbers that capture what the event is, when it happened, and what it was related to. The system uses a machine learning model, like a transformer encoder, to do this. The model is trained in two stages. First, it learns by trying to rebuild event sequences from raw data, so it gets good at understanding the flow of events. Next, it fine-tunes itself with some labeled data, so it can spot which events are important and which are just noise.
Once all the events are turned into embeddings, the next step is clustering. The system groups events that are similar into clusters. Clustering can be done in different ways, like K-means (which puts events into groups with the closest embeddings), BIRCH (which builds a tree of clusters), or OPTICS (which finds clusters based on how close events are in the embedding space). Clustering can also be hierarchical, meaning there are clusters within clusters. For example, the first level might separate relevant events from noise, and the next levels might group similar types of events or threads together.
From these clusters, the system picks out the ones that contain relevant events. These are the parts of the data that matter for understanding requests and performance. Inside each cluster, the events are sorted using rules based on their timestamp, thread ID, and other info. This step puts the events in the right order, so the system can see the full sequence of a request from start to finish.
Now, with the ordered events from the right clusters, the system can finally identify each request. Each request is a sequence of events that hang together in time, thread, or context. The system marks the start and end of each request, which lets it measure how long the request took and where delays might be. If some requests are much slower than others, the system can dig in and see which events or functions are to blame.
All this happens without needing special tags or changes to the software. The system learns from the data itself. It can work on different types of cloud environments—public, private, or mixed clouds—and with many different services or workloads. The model can even be retrained or fine-tuned for new types of events or services, making it flexible for many uses.
The patent also covers how the system can be built in practice. There’s a central processing unit with memory and storage, connected to the cloud computers and user devices by the network. The software running on this central system uses the steps above to process events, cluster them, and report results. The reports can show which requests or events are slow, where bottlenecks are, and suggest ways to optimize. Fixing these problems can save real money by making the cloud run more efficiently.
In summary, the key innovations here are:
– Turning raw cloud events into smart embeddings that hold their meaning and context.
– Using a two-stage machine learning model to learn both the flow and the relevance of events.
– Clustering embeddings to group related events, even when the data is messy or out of order.
– Sorting and assembling these clusters into full requests, so start and end points can be found.
– Doing all this automatically, with little or no human labeling, and in real cloud systems.
Why This Matters
This invention solves a big problem in cloud computing. By making sense of messy event data, it lets companies see what’s really happening inside their cloud software, find and fix slow spots, and save money. The method is flexible, works in real time, and doesn’t need special changes to software. It brings the power of machine learning—already proven in language and text—to the world of cloud operations, opening new doors for automation and optimization.
Conclusion
The patent we explored today brings a fresh approach to one of cloud computing’s trickiest problems: following and understanding requests as they happen. By turning raw event logs into meaningful clusters using advanced machine learning, it reveals where time and money are lost and gives businesses the tools to fix them. This is not just a technical improvement—it is a practical step toward faster, smarter, and more affordable cloud services. For anyone running software in the cloud, these ideas point the way to a future where cloud costs are lower, performance is better, and problems are easier to spot and solve.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217666.

