Query Refinement Using Optical Character Recognition

Invented by Yim; Keun Soo

Imagine you snap a picture of a sign, a menu, or a page from a book—and your device instantly knows what you want to do next. Maybe you want a translation, a definition, or to find a product online. Today, search engines try to help with this, but often miss the mark. A new patent application aims to make these tools much smarter. Let’s break down what this technology does, why it’s needed, how it builds on old ideas, and what makes it special.
Background and Market Context
We live in an age where our phones and computers are always with us. People use these devices to look up information all the time. It’s easy to type a word into a search box, but sometimes, typing is not possible or just too slow. That’s where image-based search comes in. You can point your camera at something, take a picture, and let your device figure out what you want.
Many modern phones and apps let you take pictures to search for things. For example, you can snap a photo of a restaurant sign to get reviews, or a page in a foreign language to get a translation. This is called multimodal search—using more than just text, like pictures or audio, to search for information.
But there’s a problem. When you take a picture that has text, the device uses a tool called Optical Character Recognition (OCR) to turn the picture into words. Then, it sends those words as a search query. If the OCR makes a mistake, or if the text alone isn’t enough, you get bad search results. Users often have to fix the search themselves by typing or taking more photos. This wastes time and can be frustrating.
As more people use voice, image, and other “smart” ways to search, the need for better results grows. Businesses want their apps to be fast and helpful. Users want answers without extra work. Making searches from images more accurate is a big deal in tech—and a real need in the market.
Scientific Rationale and Prior Art
Let’s look at how things have worked before. When a search app receives an image, it uses OCR to get the text from the picture. The recognized text is then sent, as-is, to the search engine. If the OCR misreads a word—like reading “vunning” instead of “running”—the search engine has to work with that mistake. Often, the results are confusing or wrong.
Older systems did not try to fix or refine the search query beyond what the OCR gave them. They also did not try to figure out what the user really wanted. They only sent the text, got back search results, and showed them to the user. If the results were bad, it was up to the user to try again using different words or more pictures.

Some systems tried to improve this with “universal” fixes—like auto-correcting spelling or using general rules for all searches. But these fixes were broad and did not use any clues from what the user was trying to do. They also did not look at what other users had searched for in similar situations.
Recent advances in machine learning have brought in smarter models. For example, some apps use models trained to predict what text might come next in a sentence, or what a user might be looking for. These models can suggest search completions or corrections based on patterns in lots of past searches. But even with these models, most systems only use them for typed text, not for text recognized from images. And they rarely tie together error correction, intent prediction, and query refinement in one smart process.
In summary, the old way was simple but limited:
– It took the text from an image and sent it straight to search.
– It did not fix mistakes or try to understand what the user wanted.
– It did not learn from how other people had searched in similar situations.
– It left most of the work to the user if the results were not helpful.
This new invention changes all of that by combining smarter error correction, intent prediction, and query refinement, all tuned to the user’s actual needs.
Invention Description and Key Innovations
Now let’s explore what this new patent application covers. The invention is a method for making image-based search smarter and more helpful, by layering several advanced steps:
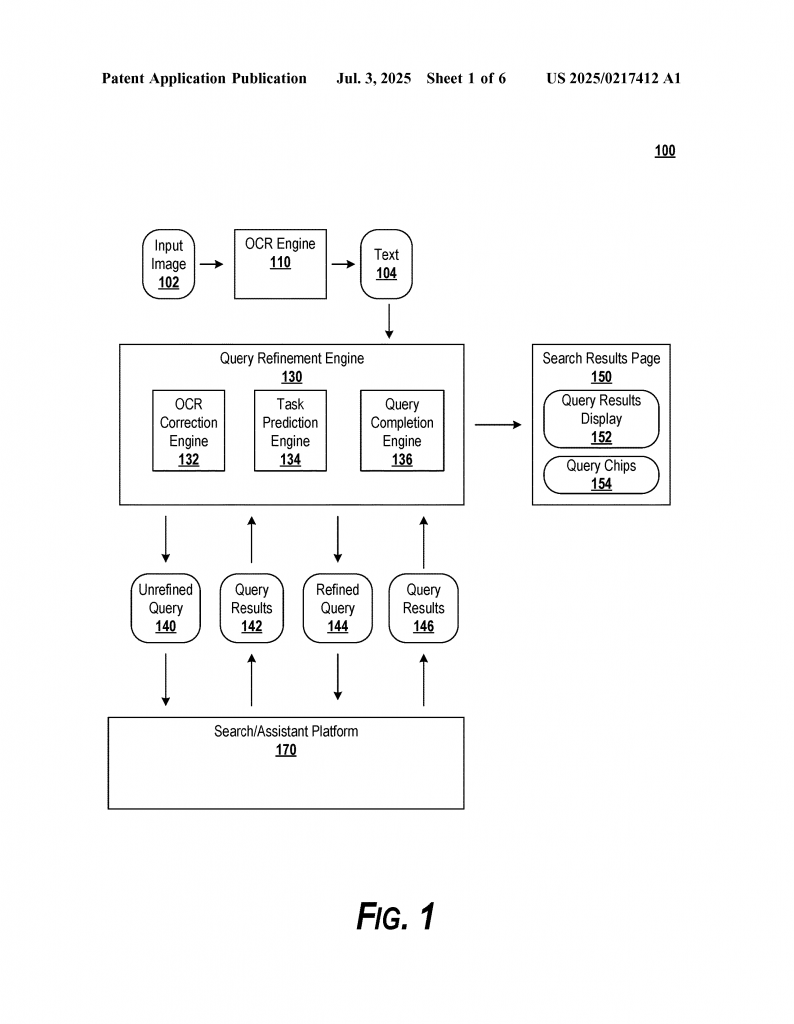
1. Smart OCR Correction
When you take a picture with text, the system uses OCR to read the text, just like before. But now, it checks the OCR output for likely mistakes. It uses error tables—either static (set in advance) or dynamic (learned over time)—to spot which letters or words might be wrong. For example, if “vunning” is read, but the system knows that “v” is often confused with “r”, it can correct the word to “running.” This correction can be based on how often certain mistakes happen or on real-time data.
2. Predicting User Intent (System Tasks)
The next step is figuring out what you want to do. Is your goal to translate the text, look up a product, find a definition, or something else? The system uses not just the text, but also hints from the image or even audio, to guess your intent. For example, if the text is in another language, it may decide you want a translation. If the text includes an airport code or a price, it may guess you want flight info or to buy something.
This prediction uses machine learning models trained on lots of past user queries. The models can look at the text, the context, and even details from the image or other inputs to decide what task to focus on.
3. Query Refinement Using Past Searches
After guessing your intent, the system runs a search using the corrected text. If the first set of search results does not seem to answer your need (as judged by the intent prediction), the system gets smarter. It looks at a huge database of past user queries—what others have searched for after seeing similar text or images. It then uses this knowledge to suggest improved or “refined” queries that are more likely to help.
For example, if you took a picture of a medicine box and the text reads “acetaminophen dosage”, but the results are vague, the system might notice that many users in this case searched for “acetaminophen dosage for children” or “acetaminophen side effects.” It can suggest these refined queries to you, or even run them automatically to get better results.
4. Machine-Learned Query Completion
The system can use models (like large language models) that are trained to finish incomplete phrases or guess what the full query should be. If the OCR gives a piece of text, the model can suggest a more complete or popular search phrase. This step is based on how real people have searched in the past and can be fine-tuned over time.
5. Smart Search Result Pages and User Interface
The end result is a search page that is much more helpful. It can show you the results for your original query, plus suggestions for refined queries as easy-to-tap buttons (“chips”). If you tap one, you get new results right away. Or, it can show you results for the refined query and let you go back to your original search if you want. This makes it easy to get to the right answer without typing or repeating your search.
6. Efficient Use of Computing Power
Not every search needs refinement. The system only does the extra work of refining queries when it looks like the first results don’t match your intent. This saves battery, bandwidth, and processing time—important for both users and service providers.
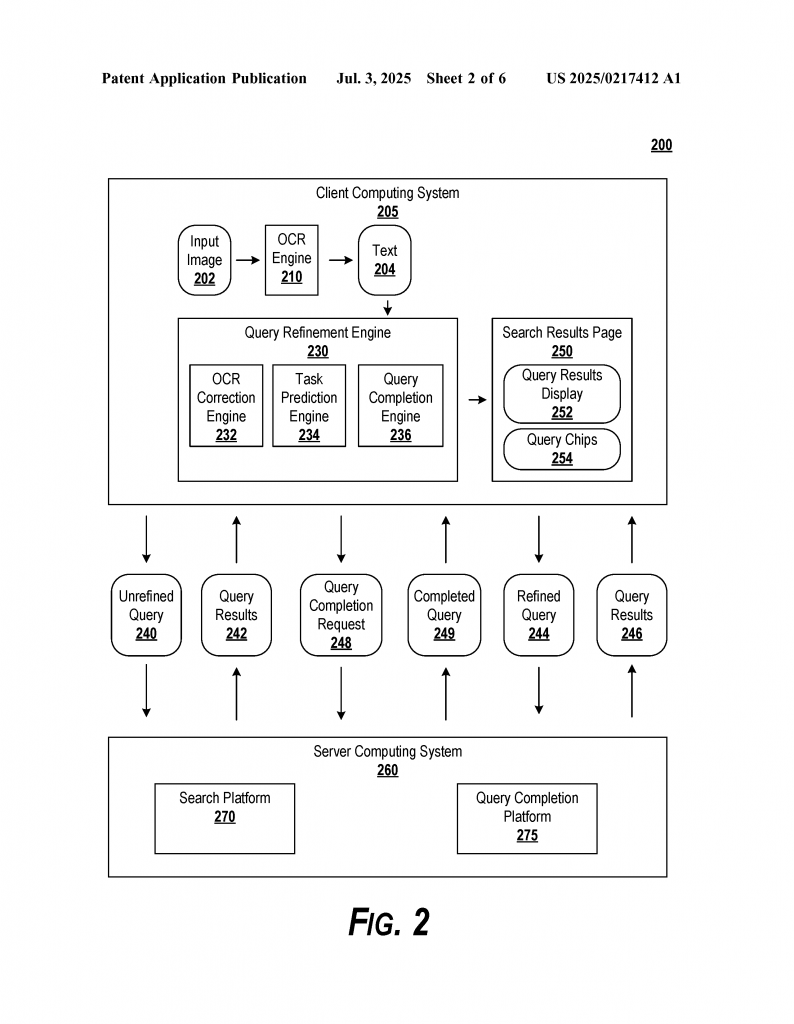
7. Flexible Deployment (Client and Server)
Parts of the process can run on your device (the “client”), while others can run on powerful servers. For example, simple OCR and corrections might happen on your phone, but the heavy lifting for query refinement can happen in the cloud. This makes the system fast and scalable.
8. Multi-Modal and Contextual Input
The system isn’t limited to just images. It can use audio (like voice commands) or other data to help understand what you want. For example, if you take a picture and also say “translate this,” the system can combine both clues to serve you better.
Technical Benefits
By using these steps, the system brings many benefits:
– Fewer mistakes from OCR, thanks to smart correction
– Better understanding of what the user wants, not just what the text says
– Search results that match real intent, not just the raw text
– Less need for users to redo searches or type extra information
– Faster, more efficient use of device and network resources
Real-World Example
Imagine you’re traveling and see a sign in a foreign language. You snap a photo. The system reads the text, corrects any OCR errors, guesses—based on language—that you want a translation, and shows you the translated text. If you snap a picture of a medicine label, it might recognize you want dosage info, and suggest the most common questions people ask about that medicine. If you take a picture of a product and the OCR reads the brand name, but not the model, the system can suggest refined queries based on what other users have searched for with similar images.
How to Take Advantage of This Technology
If you build search or assistant apps, you can use this approach to delight users. Start by making sure your OCR is accurate and can correct errors. Use machine learning to predict what users want, not just what they show you. Tap into your own data on what users have searched for before to offer refined queries and help users get to answers fast. Design your search results page to make it easy for users to try these refined queries with just a tap. And, use resources wisely—don’t do extra work unless it helps the user.
Conclusion
This new patent application marks a big step forward in how devices process image-based searches. By bringing together error correction, intent prediction, and query refinement, it bridges the gap between what users show and what they really want. The system is smart enough to fix its own mistakes, smart enough to guess your goal, and smart enough to learn from what others have needed before you. The end result is less frustration, quicker answers, and a smoother user experience.
As image-based search becomes more common, these innovations will set the standard for what users expect—and what smart apps can deliver. Whether you’re a developer, a business owner, or just a tech fan, understanding these advances can help you stay ahead in a world where every picture really is worth a thousand words.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217412.

