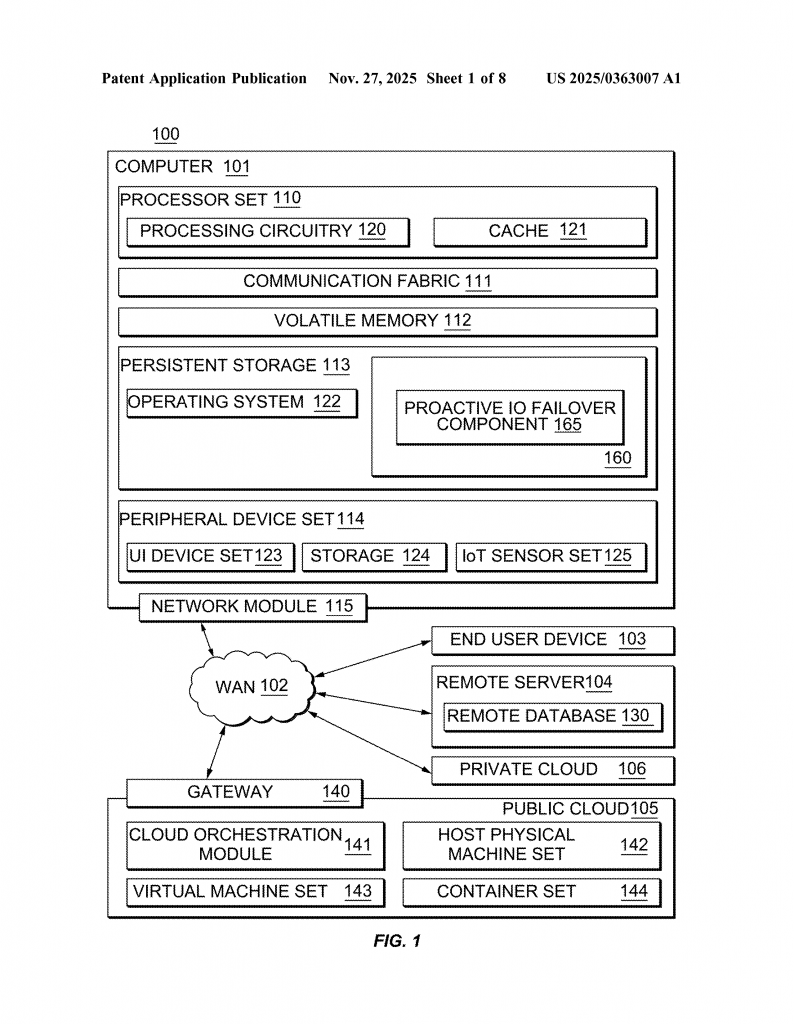
Prevent Data Center Downtime with Early Detection and Failover for Optical Transceiver Failures

Invented by KARNE; Vinayak, RAJABOINA; Yadagiri, AYYAGARI; Phani Kumar V.U., YERRAVALLI; Venkateshwar R., PANTHAM; Samyuktha

Modern computer systems rely on quick and steady connections to store and retrieve their data. Any delay or breakdown can slow everything down. This article will explain a new way to predict and avoid these problems before they cause trouble. We’ll break down the background, look at why this problem matters, explore what others have tried, and then detail the new method for predicting and fixing issues with the tiny parts that move data inside computers. This is all about making sure computers keep working smoothly, even when something inside starts to fail.
Background and Market Context
In the world of computers, storing and moving data is very important. Think about banks, hospitals, or online shopping sites. If their systems slow down or stop, it can create big problems. To keep things running, computers use special parts called host bus adapters (HBAs). These connect computers to places where data is stored, like large hard drives in a data center. Sometimes, there are many ways, or “paths,” between a computer and its storage. This is done so that if one path stops working, another can be used. This whole process is called failover.
But there’s a problem. The paths between computers and storage use small parts called optical transceiver modules—often called SFPs. These are like tiny bridges that move light signals carrying data. If an SFP starts to break, the data can slow down or get lost. Right now, most systems only notice a problem once the SFP has already failed. That means the system has to wait until the problem is obvious, then switch to another path. This waiting can slow things down for everyone using the computer system.
With more businesses using virtual machines and cloud services, many computers might share the same paths. If a shared path fails, it can affect many users at once. That’s why it’s more important than ever to notice problems early, before users see anything is wrong.
Because of this, there is a growing need for ways to watch these tiny parts and predict when one is about to fail. If the system could know ahead of time, it could switch to a safe path before anything bad happens. This idea can help banks, hospitals, schools, and any business that depends on fast, steady computer systems. It can also be very useful in places where lots of computers share the same paths to storage, like cloud data centers.
The market for this type of solution is very big. Every company that uses large computer systems and cares about uptime—meaning their systems always work—can benefit from a way to predict failures. Cloud companies, big businesses, government offices, and even some small businesses all want to avoid slowdowns. As more work is done online, the need for smooth, always-on data access keeps growing. This makes proactive failover not just helpful, but critical for today’s and tomorrow’s computer systems.

Scientific Rationale and Prior Art
The key to solving this problem is being able to see when an optical transceiver module is getting close to failing. These modules don’t just stop working out of nowhere. They show warning signs, like getting too hot, using too much energy, or sending weaker signals. If you watch these signs, you can guess when something is about to break.
In the past, systems waited until something failed completely. For example, if a data path stopped working, the system would try to use it anyway for a while—sometimes for 30 seconds or more—before realizing it was broken. Once the system noticed the failure, it would switch to another path. This meant lost time and slower service for users. Sometimes, the problem would cause delays for everyone sharing that path, especially in virtualized environments where many computers use the same hardware.
Some older systems tried to fix this by checking if a path was still working, but they didn’t look at the detailed health of the SFP modules. They waited for a complete failure, or maybe a timeout, before acting. There wasn’t a good way to watch for the early warning signs inside the modules themselves.
Other attempts to predict failures used logs or basic self-checks, but these didn’t look at the most important details. The SFP modules have built-in sensors that can report things like temperature, voltage, and signal strength. But most systems didn’t use this information to predict failures. Instead, they just waited for things to go wrong, then tried to recover.
There are standards, like the Small Form Factor (SFF) specification, that describe how to read health information from these modules. But even with these standards, most systems weren’t using this data to make smart decisions. They just used the SFPs as simple bridges and didn’t pay attention to the numbers being reported.
In short, the old way was to react to failures after they happened. The new idea is to use the health data from the SFP modules to see problems coming before they cause any trouble. This means watching for things like:
- Temperature going too high
- Voltage outside safe levels
- Signal strength getting weaker
By setting threshold values—numbers that say “this is too high” or “this is too low”—the system can be trained to spot when the module is in danger. When one of these numbers goes past its limit, the system knows it’s time to switch paths.
This is a big step forward compared to waiting for a full failure or a long timeout. It means less downtime, fewer slowdowns, and a better experience for everyone. This is especially important in large computer systems, cloud environments, and places where many users depend on the same hardware.
Invention Description and Key Innovations
This invention introduces a smart way for computers to predict when a path is about to fail and to switch to a safer path before users notice any problems. The secret is in how the system watches, identifies, and reacts to the health of optical transceiver modules (SFPs) inside the host bus adapter (HBA).
The process starts with the computer registering with the HBA. This is like telling the HBA, “Let me know if you see any warning signs.” The computer sends a special information element to the HBA, saying which health parameters to watch and what the safe limits are. These parameters are things like how hot the SFP is, how much voltage it has, how strong the outgoing and incoming signals are, and how much current is being used. For each parameter, the computer gives a number that means, “If it goes past this, something is wrong.”
Once this setup is done, the HBA keeps an eye on the SFP’s health. It checks the values at regular times. If everything is okay, it just keeps watching. But if any parameter goes past its limit, the HBA sends a notification back to the computer: “Warning! This path may fail soon.”
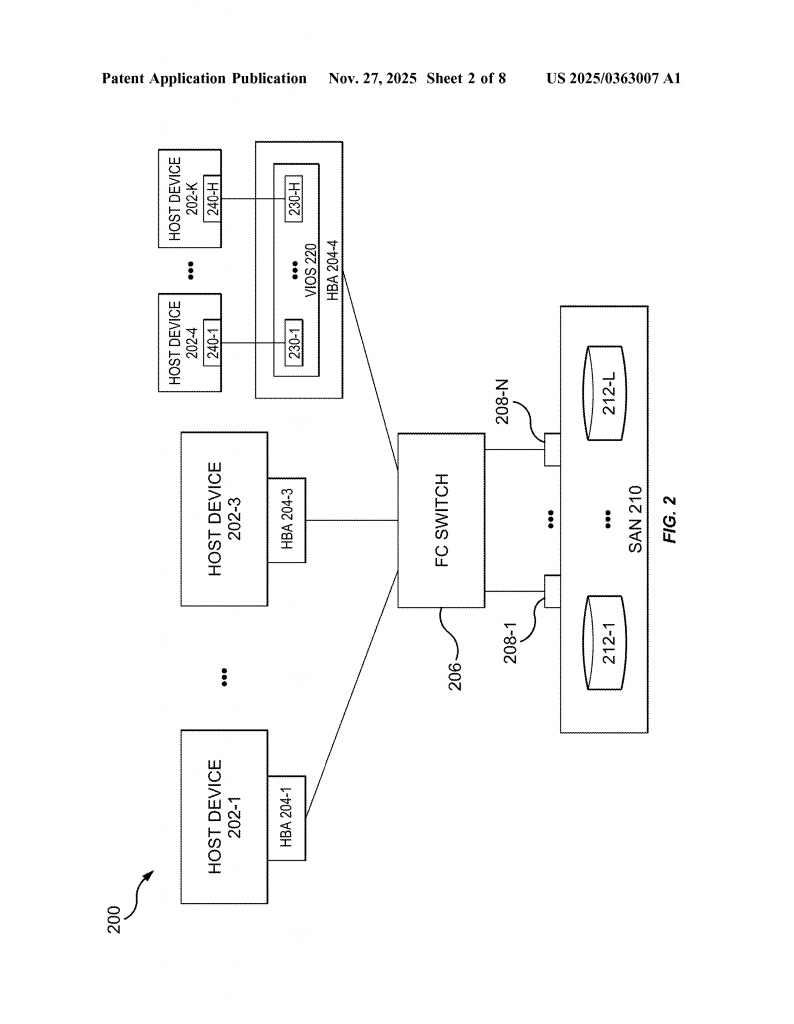
When the computer gets this warning, it acts right away. It looks for another path—meaning another port or SFP that is still healthy. If it finds one, it sends the input-output (IO) operation down the safer path. This all happens before the first path actually fails. Because of this, users do not see any delays or errors. The switch is smooth and fast.
This new way is different from older systems in several big ways:
1. Predictive, Not Reactive: Instead of waiting for a failure, the system looks ahead and acts before trouble starts.
2. Uses Real Health Data: The system pays attention to the real-time health numbers from the SFP, not just if a path is working or not.
3. Flexible Notifications: The warning can go to the main computer, or to all the virtual machines that share the same HBA. This is very helpful in cloud systems or big data centers where many users share hardware.
4. Fast, Seamless Failover: The system switches to a new path before users notice any problems. This means no waiting, no slowdowns, and no lost data.
Let’s look at the steps more closely:
Step 1: Registration
The computer tells the HBA which parameters to watch and what the limits are. This is done by sending an information element with the names of the parameters and their safe values.
Step 2: Monitoring
The HBA checks the SFP’s health at regular times. It looks at things like temperature, voltage, and signal strength. If everything is in the safe range, nothing happens.
Step 3: Notification
If any parameter goes past its safe value, the HBA sends a warning message back to the computer or virtual machines. This message says which path is at risk.
Step 4: Proactive Failover
The computer looks for another path. If there is another healthy SFP and port, it switches the IO operations to this new path. This happens before any real failure occurs.
Step 5: Continued Operation
The system keeps running smoothly. Users never see any problems. If there is no other path, the system can decide what to do next, but in most cases, there is another path ready.
This invention also works well in virtualized environments. If several virtual machines share the same HBA, the warning can be sent to all of them. This means all users stay protected, even if they’re running on shared hardware.
The technical side allows for easy setup. The information element used for registration can be set up for many parameters and threshold values. The HBA’s firmware does the monitoring, so it doesn’t slow down the main computer. Notifications are sent quickly when needed.
In summary, this invention makes computer systems smarter and faster in dealing with hardware problems. By watching for early warning signs and acting before trouble hits, it keeps data moving and users happy. It is easy to use, works in many different types of systems, and can be set up to protect both single computers and large groups of virtual machines sharing the same hardware.
Conclusion
As computers become more important in every part of life, keeping them running smoothly is a must. This new way of predicting and handling failures in optical transceiver modules inside host bus adapters is a big step forward. By watching real health data, acting before problems grow, and working well with both regular computers and virtual machines, this invention keeps systems fast, safe, and always available. It removes the long waits and slowdowns of older systems, helping businesses and users get the most from their computers. With this proactive approach, the future of computer uptime looks brighter and more secure than ever.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250363007.

