POINT-IN-TIME BACKUP OF APPLICATION DATA STORED ON DISPARATE STORAGE SYSTEMS
Invented by Hooper; Robert C., Garcia-Arellano; Christian, Cheung; Alexander, Roumani; Hamdi, Kalmuk; David, Rampurkar; Ketan
Let’s explore how a new system for backing up application data works, especially when your data lives in different types of storage. This article will break down the background of the problem, how things were handled before, and what’s special about this new way to do point-in-time backups. You’ll see why it matters, how it works, and what makes it different from older solutions.
Background and Market Context
Today, most businesses and apps store data in more than one place. Some of your data might be in a traditional database, while other parts could be in object storage like the cloud. These storage systems don’t work the same way, but the data inside them is all important. If something goes wrong—like a server crash, cyber attack, or even a simple mistake—companies need to get all their data back to how it was at a certain time. This is called a point-in-time recovery.
For years, teams have used backup systems that make copies of data at regular intervals. These backups are vital, but as apps have grown and started using many different kinds of storage, keeping everything in sync has become much harder. Imagine trying to back up a busy shopping website. Some of the site’s information, like customer details, lives in a database you can change any time. Other bits, like receipts or pictures, are saved in object storage that can’t be changed once written—this is called immutable data. If you only back up one part and not the other at the same moment, you could end up with mismatched data when you try to restore it.
This mismatch can break apps, lose sales, or cause confusion. Companies need a way to grab all their important data from different storage types at the exact same time, so everything lines up if they have to restore it. Many cloud services offer tools for backups, but these tools often work best with just one kind of storage. They struggle when you want to back up both regular, changeable data and unchangeable, immutable files together.
As more apps move to the cloud and use a mix of storage options, the need for a single, smooth backup approach has grown. Businesses want less downtime and fewer headaches. They want to know that if there’s a problem, they can quickly get everything back to how it was—no matter where the data was stored.
This is why this new patent application matters. It’s about a way to back up both changeable and unchangeable data, even when those data live in completely different systems. It tries to solve the problem of keeping everything in step, so businesses can recover fast and correctly.
Scientific Rationale and Prior Art
Let’s look at how data backup and recovery have worked before, and why those older ways don’t always fit today’s needs.
First, in classic databases or file systems, you can make a snapshot—a copy of all the data at a certain moment. This is called a point-in-time snapshot. It’s like hitting pause and taking a photo of everything as it is. If you need to go back, you restore from the photo.
But object storage, which is where lots of files or blobs live, works differently. When you save something here, you usually can’t change it later. If you want to update a file, you add a new one and delete the old one. This is called immutable storage. Some cloud services offer versioning, which keeps all the different versions of a file, but this can get expensive and messy. If you want to back up only the files you care about, you might have to copy everything, which can take a long time and use a lot of space.
In the past, companies tried to use service-provider features like object versioning or on-demand incremental backups. Object versioning saves every change, but you end up storing lots of versions, even ones you don’t need. This eats up storage and costs money. On-demand incremental backups only copy changes, but these often take a long time and may not line up perfectly with your database snapshot. That means the database might show something different from what’s in your object storage after a restore.
People have tried to get around this by writing scripts or using extra software to coordinate backups between systems, but this is hard to get right. You might have to stop the app while copying, which can mean downtime and lost business. Or, you might risk missing changes that happen during the backup, leading to data gaps or errors.
Another problem is that immutable storage systems don’t let you just “freeze” data the way regular databases do. You can’t lock all the files at once, so it’s tough to make sure nothing gets deleted while you’re copying things. This means you could lose key files if they’re deleted during your backup process.
The new system described in the patent changes this. It introduces a way to pause delete operations in the immutable storage, so nothing can be lost during backup. It also lets you resume writing new data quickly, so your app isn’t down for long. The method uses a file list, or manifest, to keep track of what needs to be copied, making the process faster and less wasteful. By combining snapshots for regular data and background copies for immutable data, all coordinated by special software, you get a backup that covers everything at once, with less risk and less cost.
To sum up, older backup methods either didn’t work well across different storage types, took too long, cost too much, or risked losing important data. This new approach is designed to work smoothly with both mutable and immutable data, even if they live in very different places.
Invention Description and Key Innovations
Let’s break down how the invention works and what makes it special.
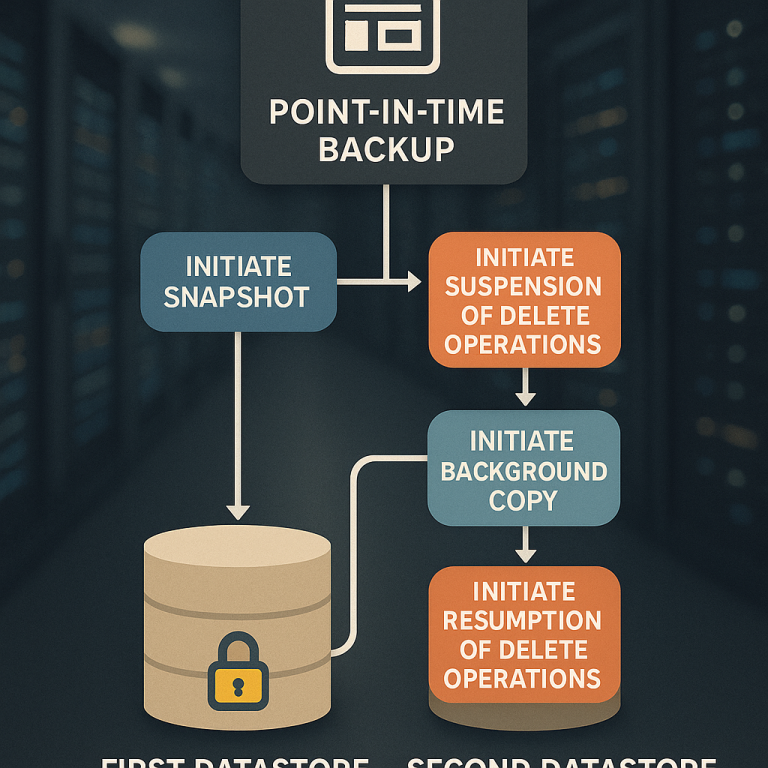
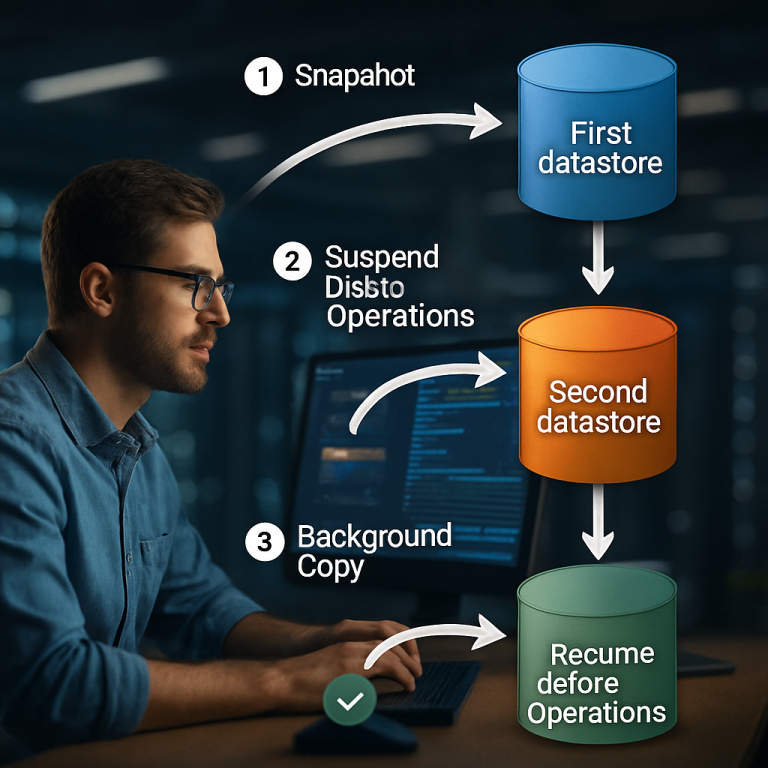
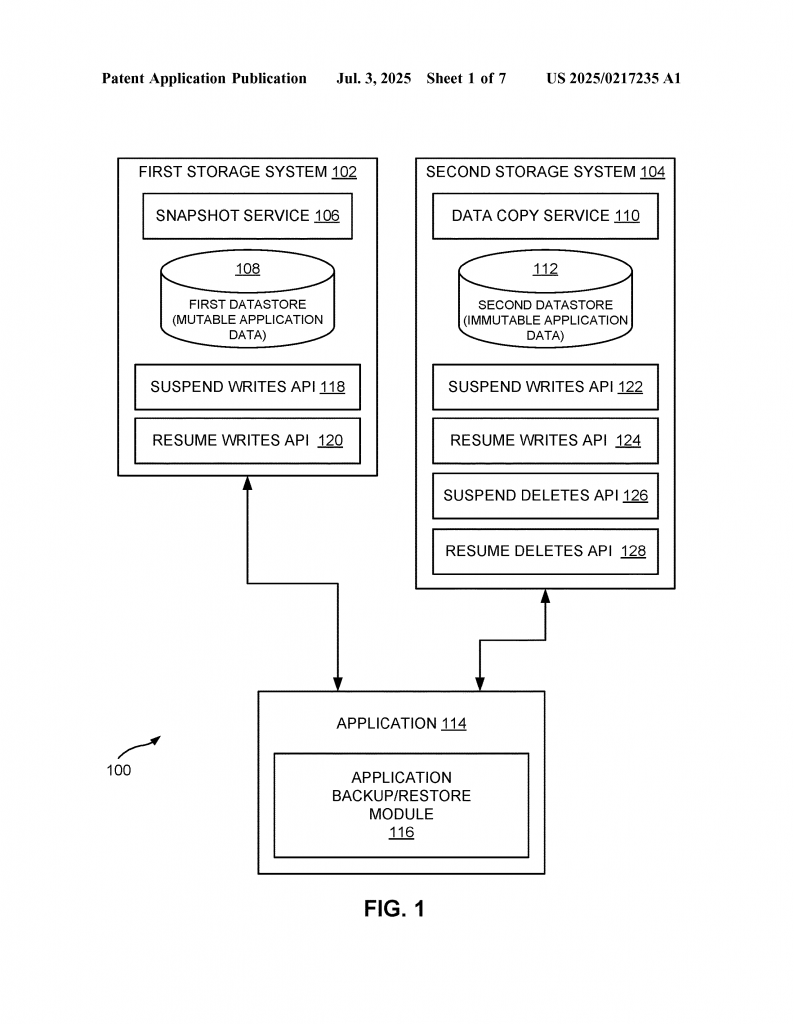
The system uses computers running special software. This software knows how to talk to both traditional storage (like databases) and immutable object storage (like cloud blobs). When it’s time to back up, here’s what happens:
First, the software tells both systems to stop any writing. This ensures the data will not change mid-backup. In the object storage, it also tells the system to pause any deletes. This keeps all the immutable files safe—none can be removed while the backup is happening.
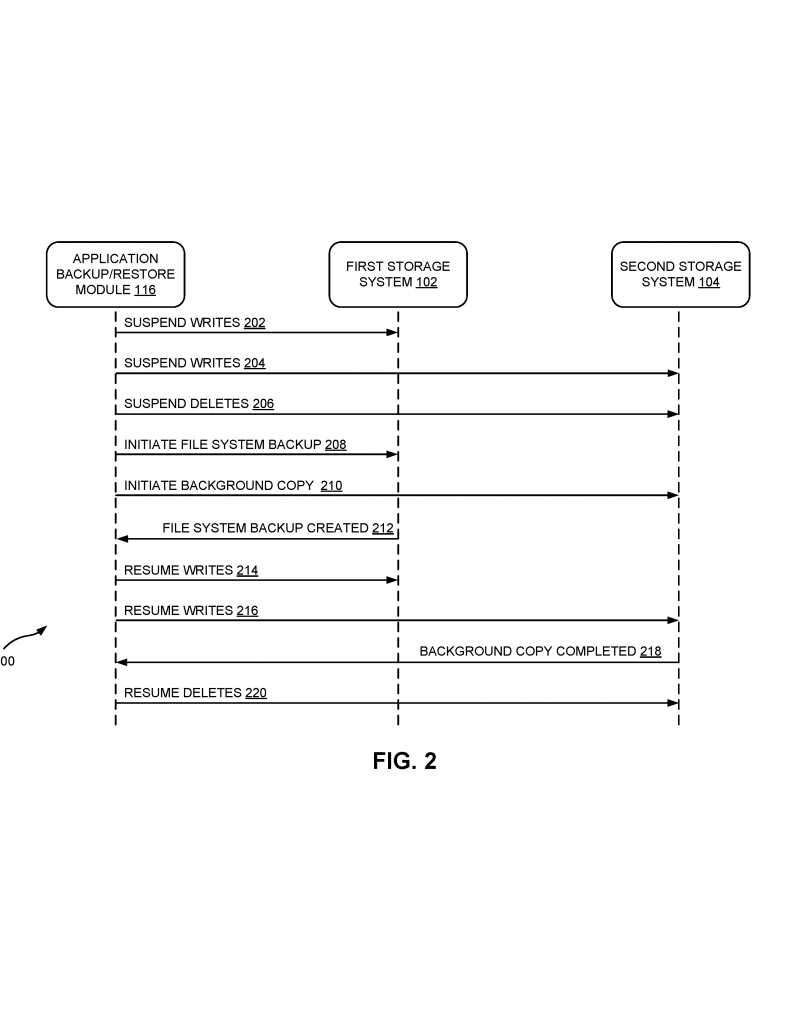
Next, the system quickly creates a snapshot of the regular, changeable data (the database or file system). This happens fast, often in just a few seconds. Once that’s done, the regular storage can go back to normal—users can start making changes again.
At the same time, the software starts making a background copy of the immutable data in the object store. This copy uses a special list, called a manifest, that tells it exactly which files to back up. By using this list, the system only copies what’s needed, saving time and storage.
While the background copy is happening, new files can be added to the object store, but the files that existed at the start (and are in the manifest) are protected from deletion. This means your app can keep working without waiting for a long backup to finish.
When the background copy is done, the system lifts the pause on deletes in the object storage. Now, any files that have been replaced or are no longer needed can be removed, freeing up space. The software can also run a “catchup” process to delete old versions that are safe to remove.
If you ever need to restore your app to the point of the backup, the system puts the regular data back from the snapshot and restores the immutable data using the background copy and the manifest. Because both were taken at the same time, everything matches up.
What’s clever about this system is that it doesn’t need to stop the whole app for long. The only real pause is while the regular storage snapshot is taken—usually just seconds. The object storage backup happens in the background, and the app can keep running. The use of the manifest also makes things faster and more efficient, since only the right files are copied. By pausing deletes (not writes), the system keeps your important data safe without stopping new work.
This system is also flexible. The manifest can live in either the regular storage or the object storage. If it’s in the regular storage, it gets captured with the snapshot. If it’s in the object store, the system makes sure it isn’t deleted during backup. Either way, you always have a map of what needs to be restored.
The invention works with all kinds of apps, whether they run in the cloud or on your own servers. It can handle different types of storage systems and works using standard APIs. This makes it easy to add to existing apps or to use as a service.
To sum up, the key innovations in this patent are:
– The ability to coordinate backups across both changeable and unchangeable data stores, keeping everything in sync.
– Pausing deletes (but not writes) in the immutable store to protect data during backup, allowing the app to keep running.
– Using a manifest to track exactly what needs to be copied, making backups faster and more efficient.
– Running the object storage backup in the background, so there’s almost no downtime.
– A “catchup” process that cleans up old, no-longer-needed data after backup, saving storage space.
These features together make backups safer, faster, and more reliable, especially for modern apps that use a mix of storage types.
Conclusion
Backing up data across different storage types is a big challenge for today’s apps. Older methods can be slow, costly, or risky. The system described in this patent brings a new way to handle backups so that all your data, no matter where it lives, can be saved at the same time. It protects important files, cuts downtime, and makes restoring your app much simpler and safer. With this method, businesses can worry less about data loss and focus more on running smoothly, knowing they can recover fast if something goes wrong. This approach sets a new standard for backup and recovery in a world where data can be anywhere.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217235.

