METHODS AND SYSTEMS FOR GENERATING A LIST OF DIGITAL TASKS
Invented by BIRYUKOV; Valentin Andreevich, KUZNETSOV; Dmitriy Sergeevich

Crowdsourcing platforms have changed how we solve problems online, letting people from all over the world do quick tasks for pay. But as these platforms grow, it’s getting harder to match the right person with the right task. A recent patent application lays out a smart new way to do this using machine learning. In this article, we’ll break down the ideas behind this invention, look at how the technology fits into the market, discuss how it is different from what came before, and explain what makes it special.
Background and Market Context
Crowdsourcing is everywhere today. Platforms like Amazon Mechanical Turk, Yandex Toloka, and others have millions of people doing many small online jobs—things like labeling pictures, answering surveys, or checking website content. Companies, called requesters, post these jobs. Workers, or assessors, pick which jobs to do and get paid for each one.
This setup works well when there are lots of jobs and lots of people. But it also creates challenges. For example, some jobs are very popular, while others are ignored. Some workers only pick jobs they already know how to do, leaving new or unusual jobs unfinished. When new types of tasks appear, it can be hard to find people willing to try them. This leads to slower results for requesters and less variety for workers.
There’s also another problem: quality. Some workers do jobs quickly but make mistakes. If these mistakes end up in the data companies use to train their machine learning models, the models might not work well. So, the platform needs to make sure the right people are doing the right jobs—and that they do them correctly.
Previous attempts to fix these problems have helped, but not solved them. Some platforms track how well a worker does and use that to decide which jobs to show them. Others let requesters set rules to pick who can do their jobs. Some systems use “honeypot” tasks—where the correct answer is known—to check if workers are paying attention. But these methods often focus only on one side: keeping workers happy or making sure requesters get good results, but not both at the same time.
This is where the new invention comes in. It tries to balance the needs of both sides: giving workers a list of jobs they are likely to want, but also making sure the requesters’ jobs are getting done by people who can do them well, even if those jobs are new or less popular.

Scientific Rationale and Prior Art
To better understand this invention, it helps to look at how task assignment has worked in the past. In early crowdsourcing platforms, jobs were shown to everyone, and workers picked what they wanted. There was little control over who did what, leading to uneven quality and slow completion for less attractive tasks.
Over time, platforms added features to guide task selection. Requesters could set qualifications—like only letting workers with a high approval rating or certain skills do their tasks. Some systems would recommend jobs to workers based on their past activity. Others used control tasks (honeypots) to measure if workers were paying attention, and would block or warn those who made too many mistakes.
A few patents tried to formalize these ideas. For example, US Patent Application 2015/254593 from Microsoft described a way to generate “reference” tasks and use trusted workers to create a gold standard for answers. If trusted workers agreed, their answer would be used as correct, and then the platform could use these answers to test other workers.
Another patent, US Patent Application 2009/0204470 from Clearshift, talked about using worker qualifications and reputation to assign tasks, and provided tools for requesters to track job progress. But both these approaches mostly focused on making sure the answers were correct, not on balancing worker satisfaction and requester needs together.
What makes the new approach different is that it uses machine learning in a more advanced way. It tries to predict not just whether a worker will do a job, but also how likely they are to do it correctly—even for jobs they have never done before. Then, it uses another machine learning model to create a ranked list of tasks for each worker, weighing both the worker’s likely interest (so they are happy) and the requesters’ need for good results (so jobs get done right).
This balancing act is tricky. If you only show workers jobs they like, new or tricky jobs never get done. If you only care about getting every job finished, workers get frustrated, do worse work, or leave the platform. The new invention tries to find a sweet spot, using data from both sides and letting the platform adjust the balance as needed.

Invention Description and Key Innovations
The heart of the invention is a system that uses several machine learning models to decide which jobs to show to each worker, and in what order. Here’s how it works, step by step, in simple terms:
1. When a worker logs in or asks for new jobs, the platform collects information about them. This might include their past performance, what types of jobs they have done, how well they did, how fast they work, and details from their user profile (like education or languages spoken).
2. The system then makes a “vector”—a kind of summary—for this worker. It also creates a similar summary for each available job. These summaries are just long lists of numbers that capture important information about the worker or the job.
3. The platform looks at all the available jobs and calculates which ones are most similar to the worker’s skills or interests, using these vectors. It picks a smaller set of jobs that are a good match.
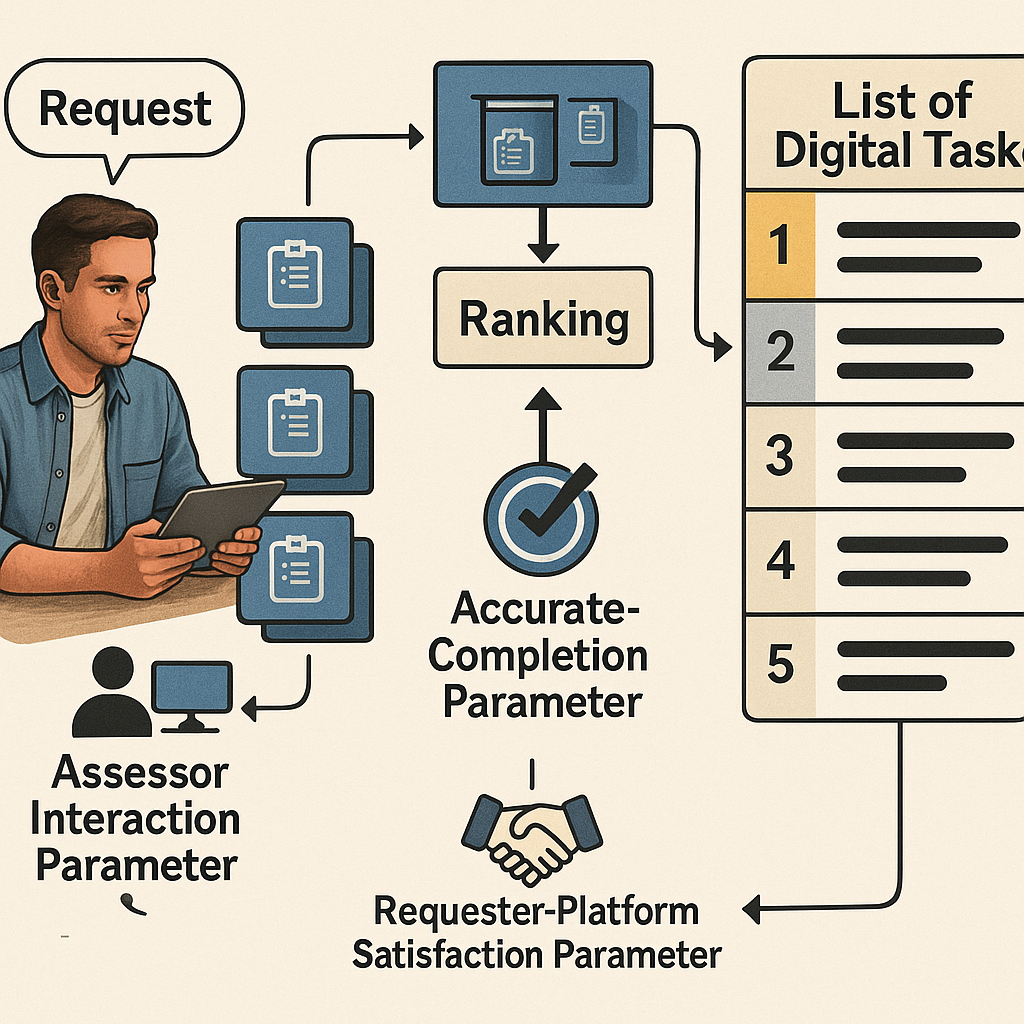
4. For each job in this smaller set, the system uses one machine learning model to predict how likely the worker is to click on the job—that is, does it look interesting to them? This is called the “assessor interaction parameter.”
5. Next, it uses a different machine learning model to predict how likely the worker is to do the job correctly if they pick it. This is called the “accurate-completion parameter.” This prediction uses not just the worker’s past results, but also things like how consistent their answers are with other workers, and how well they did on similar jobs.

6. Now comes the clever part. The platform needs to make a ranked list of jobs for the worker, putting the best ones at the top. But what does “best” mean? Here, it means jobs that the worker is likely to pick (so they don’t get frustrated and leave), but also jobs that the worker is likely to finish correctly (so requesters are happy). The system combines both predictions—the “assessor interaction parameter” and the “accurate-completion parameter”—into a single score for each job.
7. The platform uses a third machine learning model to rank the jobs. This model is trained to balance the two goals: maximize the chance that the jobs are completed correctly, but keep the worker’s satisfaction above a certain level. This way, if there’s a new kind of job that the worker hasn’t seen before but the system thinks they could do well, it might move that job higher up the list, but not so high that the worker gets annoyed seeing too many unfamiliar jobs.
8. The system picks the top N jobs (maybe 10 or 20) from this ranked list and shows them to the worker. The worker then chooses which one(s) to do.
This process repeats every time the worker asks for more jobs.
To make these predictions, the invention suggests using proven machine learning techniques. For example, it can use decision tree models (like CatBoost, which is good for handling lots of different features) and ranking algorithms (like Stochastic Rank or Yeti Rank) to fine-tune the lists. The models are trained on past data—looking at what workers picked, how they performed, and how happy requesters were with the results.
There are extra features too. The system can use “control” tasks with known answers to check how reliable a worker is. It can also measure how consistent a worker’s answers are with others doing the same task. And it can adjust the balance between worker happiness and requester satisfaction by changing the “target” satisfaction level in the ranking algorithm.
What does this mean in practice? Suppose a platform has a bunch of new image labeling tasks that no one is picking. The system looks for workers who have done similar tasks well in the past and predicts which of them are most likely to do these new jobs correctly, even if they haven’t done that exact kind before. It then moves these jobs up in their lists so they see them sooner, but doesn’t push so many new jobs that the worker gets frustrated. At the same time, it makes sure the worker still sees plenty of jobs they know and like, keeping them engaged and happy.
This approach helps both sides. Requesters get their jobs done faster and with better quality. Workers see a mix of familiar and new jobs, so they stay interested and can build new skills. The platform itself becomes more efficient, with fewer jobs left undone and fewer workers dropping out.
In summary, the key innovations are:
– Using machine learning to predict both worker interest and likely quality for each job, not just one or the other.
– Ranking jobs for each worker by combining these predictions, balancing worker and requester needs.
– Letting the platform adjust the balance point to suit its business goals or respond to changing conditions.
– Using advanced ranking techniques to make the lists smarter and more effective over time.
Conclusion
Crowdsourcing platforms face a tough challenge: keeping workers happy and engaged while also making sure jobs get done quickly and correctly. This new invention offers a smart, machine learning-based way to solve this problem by ranking tasks for each worker in a way that balances both sides’ needs. It learns from past data and adapts to new tasks and new workers, making the whole platform work better for everyone. As crowdsourcing continues to grow, this kind of technology will be key to delivering high-quality results at scale—and keeping both workers and requesters coming back for more.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217732.

