MANAGING NETWORK LAYERS
Invented by POLAGANGA; Roopesh Kumar, NUSETTY; Madhav Ram, PACHALLA; Satish Subramanya
Today, our world runs on fast and reliable networks. When you make a video call, stream a movie, or just send a message, you expect it to work smoothly. But behind the scenes, making sure networks work well for every device is a big challenge. This article explores a new way for managing network layers—one that adapts to how each device acts, learns from the past, and keeps you connected better than ever.
Background and Market Context
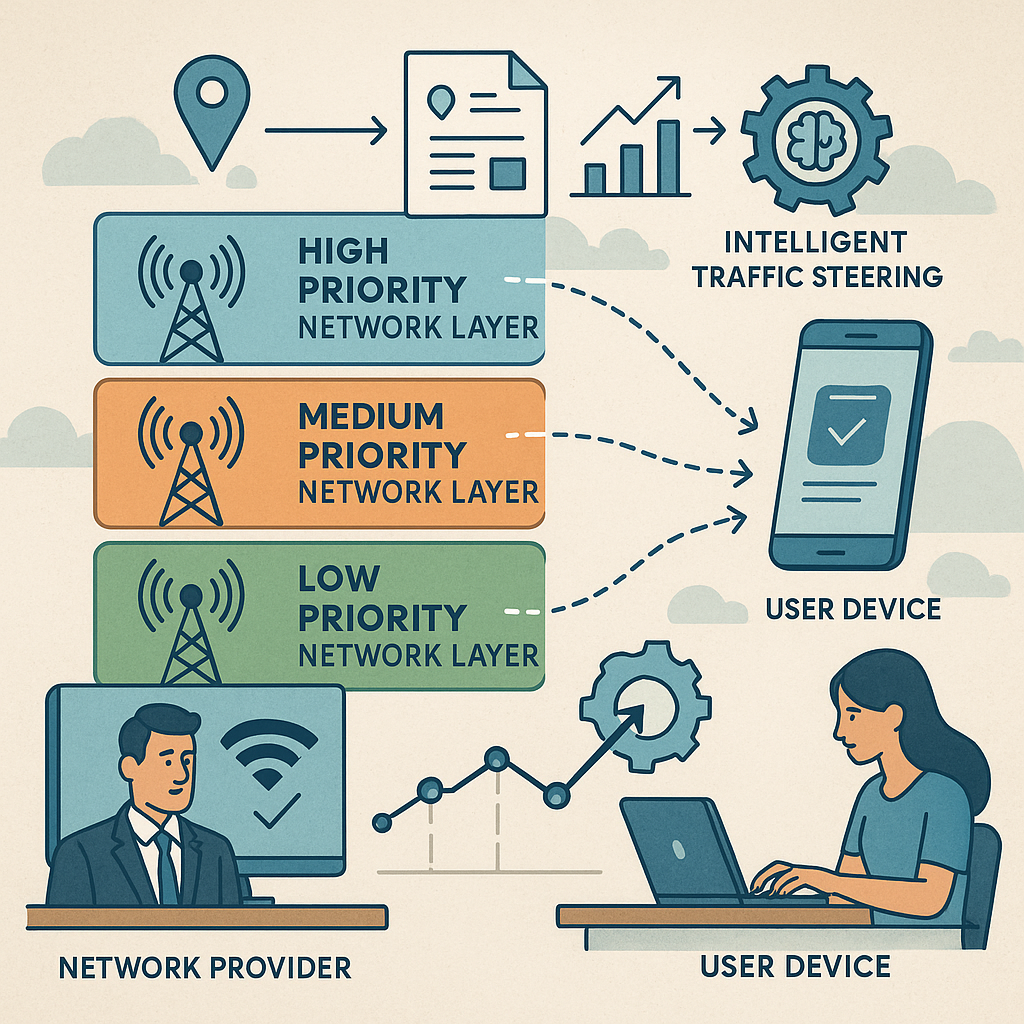
Modern networks, like 4G and 5G, are built to handle lots of people using their phones, tablets, and computers all at once. As more people use these devices, and as apps demand more data, keeping everything running fast and smooth is harder than ever. Network companies use different “layers” to manage all this traffic. Think of these layers as different roads cars can take. Some are wider and faster, and some are better for certain cars.
In the past, network companies picked which “road” a device should use based mostly on what the device could do and how much space was on each road. For example, a brand-new smartphone might get to use the newest, fastest road, while an older phone might be put on a slower road. This worked for a while, but as devices and apps got more complex, this simple way started to show problems.
Sometimes, a device that should be fast slows down or drops calls. Maybe it is using a road that is busy or not a good fit. Other times, a group of similar devices all start having trouble at once, maybe after a software update. Network companies needed a better way to see these problems and fix them quickly, so users stay happy.
This is where the new system comes in. It looks at how each device is really doing, not just what it “should” do. It learns from past problems—like dropped calls, slow data, or failed connections—and changes the “road map” in real time. If one road is causing problems for a certain device or group of devices, the system can move them to a better road automatically. This makes the network smarter and more helpful for everyone.
Why is this so important right now? Because networks are getting more crowded, and users expect perfect service. With so many types of devices, from smartwatches to high-end phones, and with software updates rolling out all the time, it’s hard to plan ahead with just simple rules. A system that watches, learns, and adapts gives network companies an edge. It helps keep users connected, reduces battery drain, and even makes the network last longer by spreading the work around.
So, in this fast-changing world, making networks more “aware” of what’s really happening on each device is not just nice—it’s becoming necessary. This is the market context for this new patent: a smarter way to keep everyone online and happy, no matter what device they use or what’s happening on the network.
Scientific Rationale and Prior Art
To understand why this invention matters, let’s look at how networks have handled these problems before and why that isn’t enough today.
In older systems, networks used fixed rules. Each device was assigned a network layer based on what type of device it was, how new it was, or how much data it could handle. These rules were set up ahead of time, often by engineers who guessed what would work best. If a device had trouble, like a dropped call or slow data, the network might not even notice right away. If lots of devices had trouble, it could take hours or days for engineers to spot the trend and make changes.
Some systems tried to do better by looking at the load on each network layer. If one layer was too busy, the network could move some devices to a less busy layer. But this still didn’t look at how each device was performing. Maybe a certain brand of phone or a certain software version just didn’t work well on one layer, even if that layer was not busy. The system wouldn’t know, and users would still have a bad experience.
A few networks started using basic performance data, like the number of dropped calls, but they used this data at a very broad level. They might see that a whole tower was having problems, but not spot that only one group of devices was struggling. This meant that fixes were slow and not very targeted.
Another problem was timing. Some issues only happen during certain times of day. For example, a network layer might work fine at night, but every morning during rush hour, it slows down. Old systems didn’t learn from these patterns. They treated every moment the same.
The new invention steps in where these old ways fall short. It watches each device, sees how it is doing, and uses history to predict when and where problems will happen. It can spot patterns, like a certain device model having trouble during a certain time or after a software update. Then, it acts right away, moving devices to better network layers and stopping problems before they spread.
The science behind this is simple but powerful. By collecting data—like dropped sessions, failed connections, and slow speeds—for each device, and comparing it to what is “normal” for that device, the system knows when something is wrong. It links these problems to the current network layer, figures out if it’s a one-time blip or a real pattern, and then updates the device’s “road map” to avoid trouble.
No earlier system has done all this, at this level of detail, speed, and intelligence. By focusing on the device’s real experience—and not just the rules or the overall traffic—the invention gives networks a new level of control. It can handle many types of devices, software versions, and network layers, and it keeps learning and adapting as things change.
This is the scientific jump: from fixed, slow, and general rules, to live, smart, and device-specific management. The invention fills a gap that has become more and more important as networks get denser, devices get more varied, and users expect perfection.
Invention Description and Key Innovations
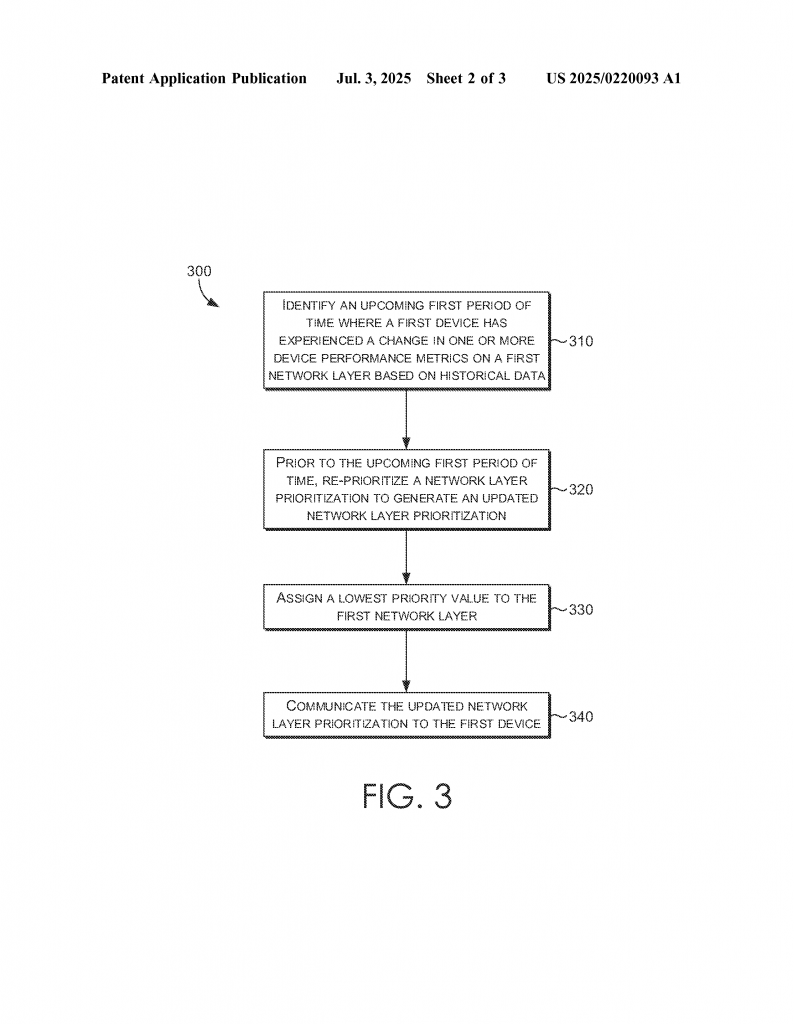
Let’s break down how this new system works and what makes it special.
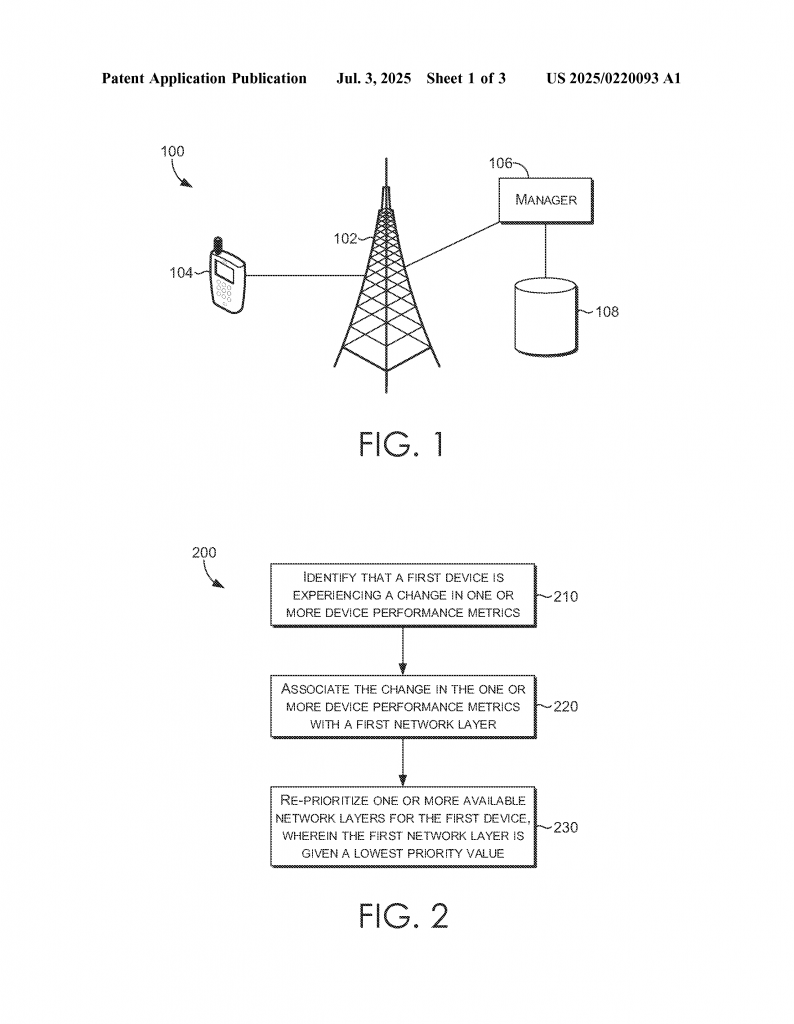
The invention is both a system and a set of methods for managing network layers. It uses one or more processors and smart instructions stored in memory to watch how each device performs on each network layer. Here’s how it works in practice:
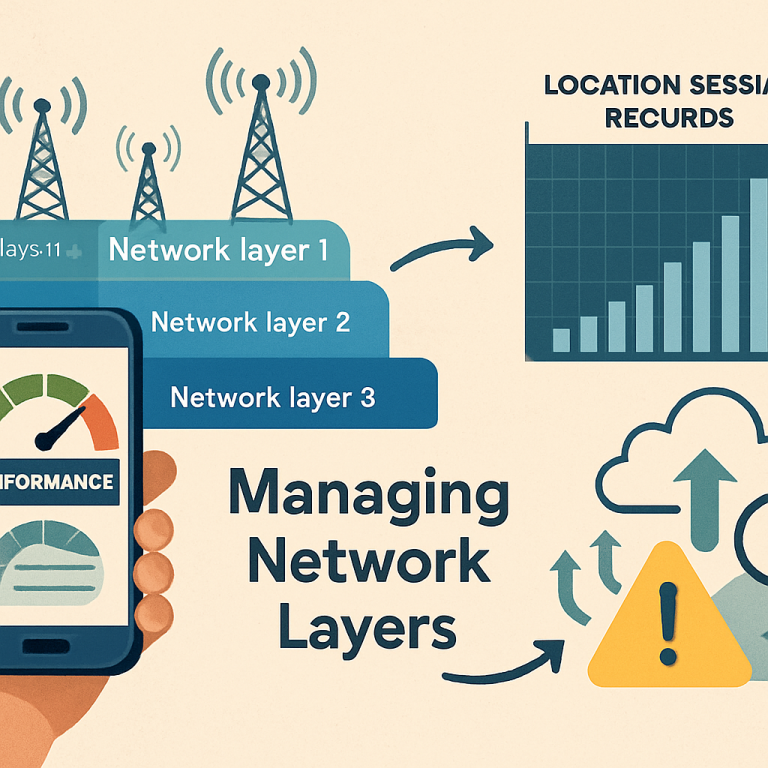
First, the system keeps an eye on the “performance metrics” of every device. These metrics include things like dropped calls, failed attempts to connect, and the speed of data (called throughput). For every device, the system has a “normal” baseline—what is expected when things are going well. If the device suddenly starts having more dropped calls, more failures to connect, or slower data speeds, the system sees this as a “change.”
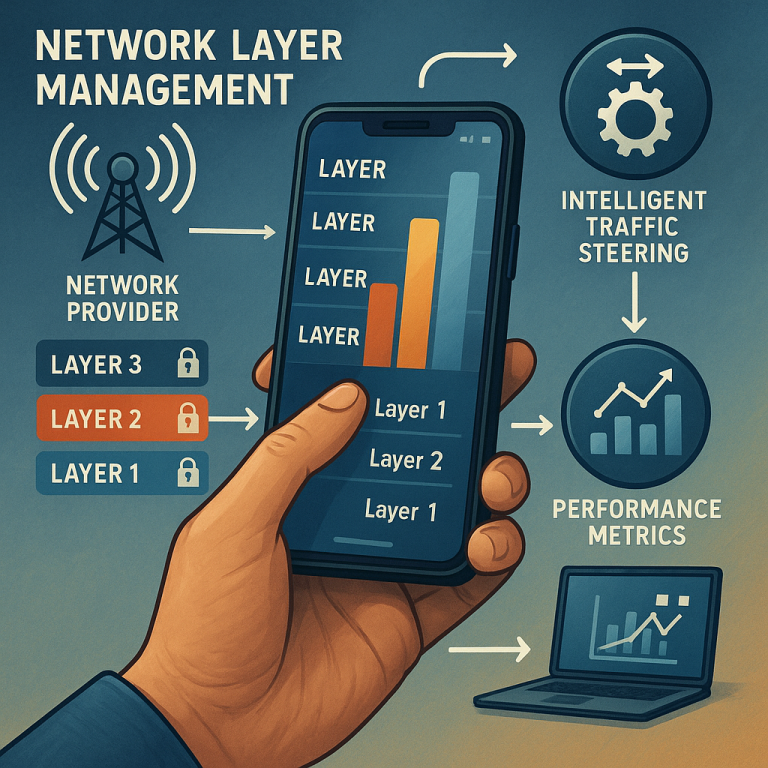
The system links this change to the network layer the device is using at that moment. For example, if a certain phone starts dropping calls only when it is on Layer N25, the system marks Layer N25 as a trouble spot for that phone. The key here is that it can do this for one device, a group of devices, or even devices with a certain software version.
As soon as a problem is found, the system updates the “priority list” for that device. The troubled network layer is moved to the bottom of the list, so the device will avoid it if possible. This update can be sent right away to the device. If the device is already online, it may be told to “handover” to a better network layer. If the device is idle, the new priority list will guide it when it next connects.
The system also keeps track of patterns over time. If it sees that every morning a device has trouble on a certain network layer, it can act ahead of time. Before the trouble period starts, it updates the priority list so the device avoids the bad layer during that time. This way, problems can be prevented before they even start.
To keep things running smoothly, the system can use timers for these priority changes. After a set time, the system checks if the problem is still there. If not, it can go back to the original settings. If the problem remains, it keeps the new setup or makes more changes.
Another smart feature is that the system can look at groups of devices. If it sees that all phones of a certain type, or with a certain software version, are having trouble on one network layer at one cell site, it can update the priority for all of them at once. This is great for dealing with problems caused by software updates or changes in the network.
The system also keeps an eye on the “load” of each network layer. If too many devices are moved to one layer, the system can spread them out to keep things balanced. This avoids having one network layer get too crowded while others are empty.
What’s new and clever about this invention is how it connects the dots. It doesn’t just watch the whole network or just react to big problems. It looks at the real-life experience of each device, learns from history, and acts fast to make things better. It is like having a smart traffic cop for every phone, tablet, or computer, making sure each one gets the best possible route through the network.
There are big benefits for users and network companies. Users get fewer dropped calls, faster data, and better battery life. Network companies get fewer complaints, fewer wasted resources, and a network that can adapt to new problems on its own. Even as devices and apps keep changing, the system keeps learning and improving.
In short, the invention takes live data, learns from it, and adapts the network in real time—making sure every device gets the best connection possible.
Conclusion
Networks are the backbone of our digital lives. As they get more crowded and complex, keeping every device running well is a huge challenge. This new invention steps up to meet it. By watching how each device is really doing, learning from patterns, and changing the network “road map” in real time, it brings a new level of intelligence and care to network management. The result is a smoother, faster, and more reliable experience for everyone, every time they connect.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250220093.

