Invention for Methods for evaluating the training objects using a machine-learning algorithm
Invented by Pavel Aleksandrovich BURANGULOV, Yandex Europe AG
Machine learning algorithms rely on large amounts of training data to learn patterns and make accurate predictions. However, the quality of the training data plays a significant role in the performance of these algorithms. Therefore, it is essential to have robust methods for evaluating the training objects to ensure the reliability and effectiveness of machine learning models.
One of the primary challenges in evaluating training objects is the presence of bias or noise in the data. Biased or noisy training data can lead to inaccurate predictions and poor model performance. To address this challenge, various methods have been developed that use machine learning algorithms to evaluate the quality of training objects.
One such method is the use of anomaly detection techniques. Anomaly detection algorithms can identify unusual or outlier training objects that may negatively impact the model’s performance. By removing or correcting these anomalies, the overall quality of the training data can be improved, leading to better model performance.
Another method for evaluating training objects is through the use of cross-validation. Cross-validation involves dividing the training data into multiple subsets and training the model on different combinations of these subsets. By evaluating the model’s performance on each subset, it is possible to assess the generalizability and robustness of the training objects.
Furthermore, ensemble methods have gained popularity in evaluating training objects. Ensemble methods combine multiple machine learning models to make predictions, and they can also be used to evaluate the quality of training objects. By comparing the predictions of different models, it is possible to identify training objects that may be problematic or unreliable.
The market for methods for evaluating training objects using machine learning algorithms is driven by the increasing demand for accurate and reliable machine learning models. Industries such as healthcare, finance, and e-commerce heavily rely on machine learning for decision-making and predictions. Therefore, ensuring the quality of training data is of utmost importance.
Additionally, the market is also driven by advancements in machine learning algorithms and techniques. As new algorithms are developed, there is a need for corresponding evaluation methods to assess their performance and effectiveness. This creates opportunities for companies and researchers to develop innovative methods for evaluating training objects.
In conclusion, the market for methods for evaluating training objects using machine learning algorithms is experiencing significant growth. The demand for accurate and reliable machine learning models has driven the need for robust evaluation methods. Companies and researchers are continuously developing new techniques to assess the quality of training data and improve the performance of machine learning models. As machine learning continues to advance, the market for evaluation methods is expected to expand further.

The Yandex Europe AG invention works as follows
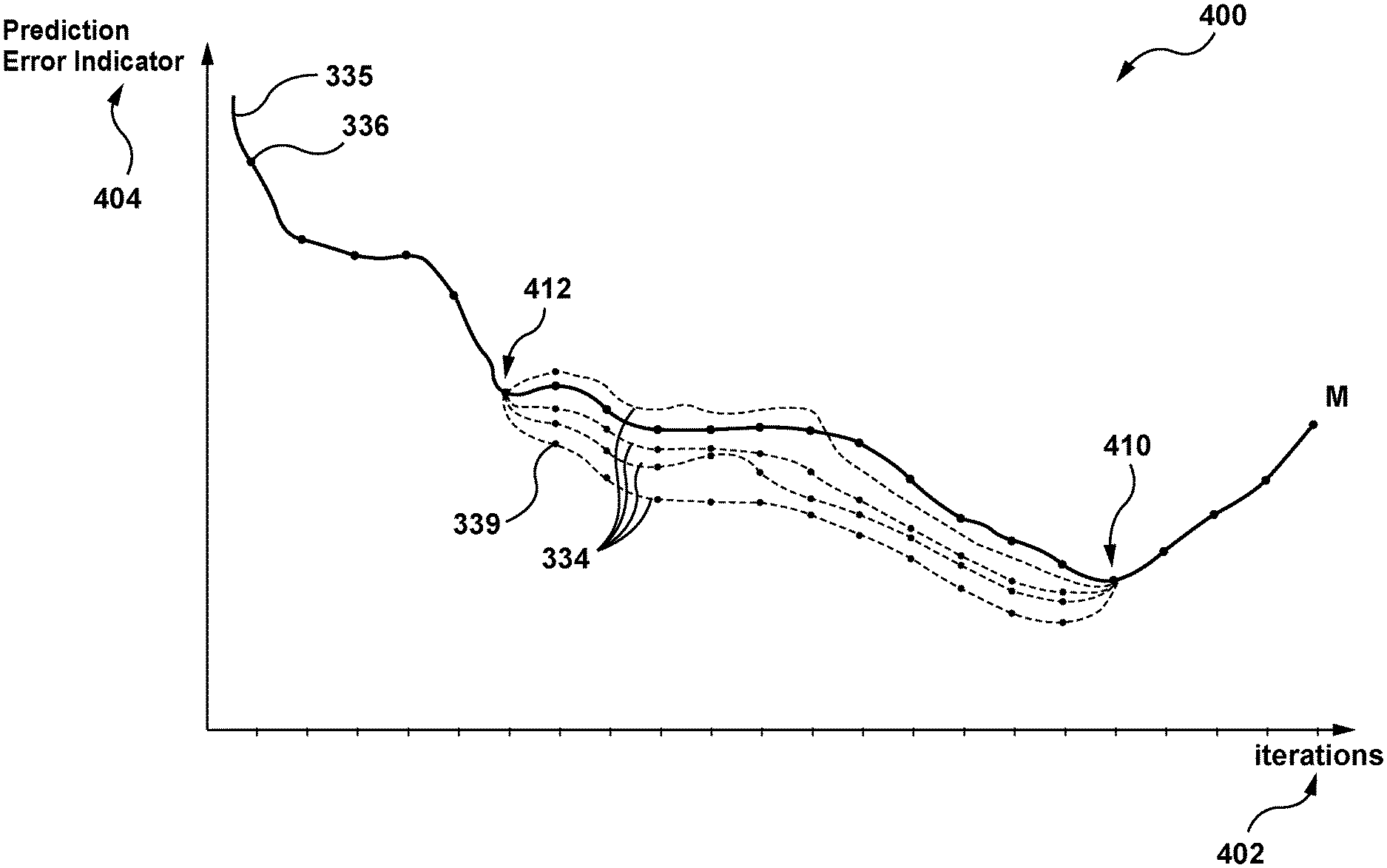
Methods for training machine learning algorithms (MLA), comprising: acquiring first sets of training samples with a plurality features; iteratively constructing a predictive model using the plurality features; and generating respective first error indicators. The analysis of the first prediction error indicators for each iteration is used to determine the overfitting point and at least one evaluation start point. Obtaining an indication of the new set of training samples, iteratively retraining with at least 1 training object using the at least evaluation starting point in order to obtain a plurality retrained models of the first predictive model and generating each retrained error indicator. A plurality retrained error indicators and associated first error indicators are used to select one of the training objects and the first set.

Background for Methods for evaluating the training objects using a machine-learning algorithm
Machine learning is a field that has been created by the convergence of computer hardware, technology, and the proliferation of mobile electronic devices. This interest was sparked by the need to develop solutions for automating tasks, making predictions, classifying information, and learning through experience. Machine learning is closely related to data analytics, optimization and computational statistics. It explores the construction and study of algorithms that make predictions and learn from data.
Machine learning has developed rapidly in the past decade. It is now used to create self-driving vehicles, speech recognition software, image recognition software, personalized services, and even the understanding of the human DNA. Machine learning also enhances information retrieval, including document searching, collaborative filters, sentiment analysis and more.
Machine Learning Algorithms (MLAs), can be divided into three broad categories: supervised learning, reinforcement learning and unsupervised learning. Supervised learning involves presenting machine learning algorithms with inputs and out puts that have been labelled by assessors. The goal is to train a machine-learning algorithm to learn a general rule of mapping inputs to outcomes. Unsupervised learning involves presenting unlabeled data to the machine-learning algorithm, with the goal of the algorithm finding hidden patterns or structures in the data. Reinforcement Learning is the process of an algorithm learning in a dynamic environment, without being provided with data or corrections.
The challenge of using machine learning algorithms to build flexible and reliable models that describe real world data is choosing the features to be considered by the model and the training data to use to train it. Building a predictive modeling can be time-consuming and expensive. A trade-off is often made between computing resources and accuracy.
Overfitting is another risk that can occur once a model has been built. The model may work well with a data set for training, but not be able to make accurate predictions when faced with new data.
U.S. Patent Publication No. “Resource Allocation for Machine Learning” is 2014/0172753. by Nowozin et al. This book teaches how to allocate resources for machine learning. It explains how to select between multiple options as part of a random decision tree training. In different examples, samples of information regarding uncertain options are used in order to score options. In different examples, confidence intervals for scores are calculated and used to choose one or more options. In some examples, the scores for the options are bounded differences statistics that change little when any sample is removed from the calculation. For example, random tree training can be made more efficient while maintaining accuracy. This is not limited to applications such as human body pose detection using depth images.
U.S. Patent Publication No. “Estimation on predictive accuracy gains by added features” (2015/0095272) Bilenko et. al. This teaches how to estimate the predictive accuracy gain when a new feature is added to an existing set of features. An existing predictor will be trained using this set of features. The outputs of an existing predictor can be retrieved by a datastore. A predictive accuracy gain estimate for a potential feature that is added to a set of features, can also be calculated as a function the outputs from the existing predictor. The prediction accuracy gain estimate can also be calculated without having to train a new predictor using the set of enhanced features.
U.S. Patent Publication No. “U.S. Patent Publication No. by Caplan et al. This method teaches an automated inductive bias selection using a computer. The computer receives a number of examples with each example containing a variety of feature-value pair. The computer creates an inductive dataset that correlates numerical indicators of training quality with each example. By creating multiple models, each of which corresponds to a different set of inductive biases, numerical indicators of training quality are generated for each example. Each model’s training quality is evaluated by applying it to the example. The computer uses an inductive bias dataset in order to select multiple inductive biases to be applied to new datasets.
Embodiments for the present technology were developed by developers who recognized at least one problem with prior art solutions.
Embodiments for the present technology were developed by developers who recognized that, while prior art solutions had been developed to evaluate and/or train new features or data, noise and overfitting can sometimes lead to unreliable results.

The study found that evaluating the quality or predictive ability of a model trained with a new feature, or a new training sample, at a single point of overfitting may not be indicative of its general predictive ability, due to factors such as noise, prediction errors or labeling errors among others.
Developers have therefore devised methods and systems to evaluate training objects using a machine-learning algorithm.
The present technology could allow for a more sensitive evaluation of the impact of new features or new training samples, or by using fewer computational resources. This would improve the performance of the machine learning algorithm and save computational resources.
The present invention provides a computer
In some implementations, a set of new training objects can be a set of new features or a set of new training samples.
In some implementations, training and retraining of the first predictive model are performed by using a gradient-boosting technique.
In some implementations, comparing the plurality retrained prediction error indicator of the first predictive model with the plurality associated first prediction errors indicators is performed by the MLA when selecting the at least training object from the new set.
In some implementations, a first prediction error and its retrained first model are measured by a mean squared or mean absolute error.
In some implementations the statistical hypothesis is a Wilcoxon-signed-rank test.
In some implementations, there are multiple evaluation starting points.

In some implementations, every one of the multiple evaluation starting points are associated with their respective multiplicity of first predictive models that have been retrained.

Click here to view the patent on Google Patents.

