Invention for Machine Learning based extraction from electronic documents of partition objects
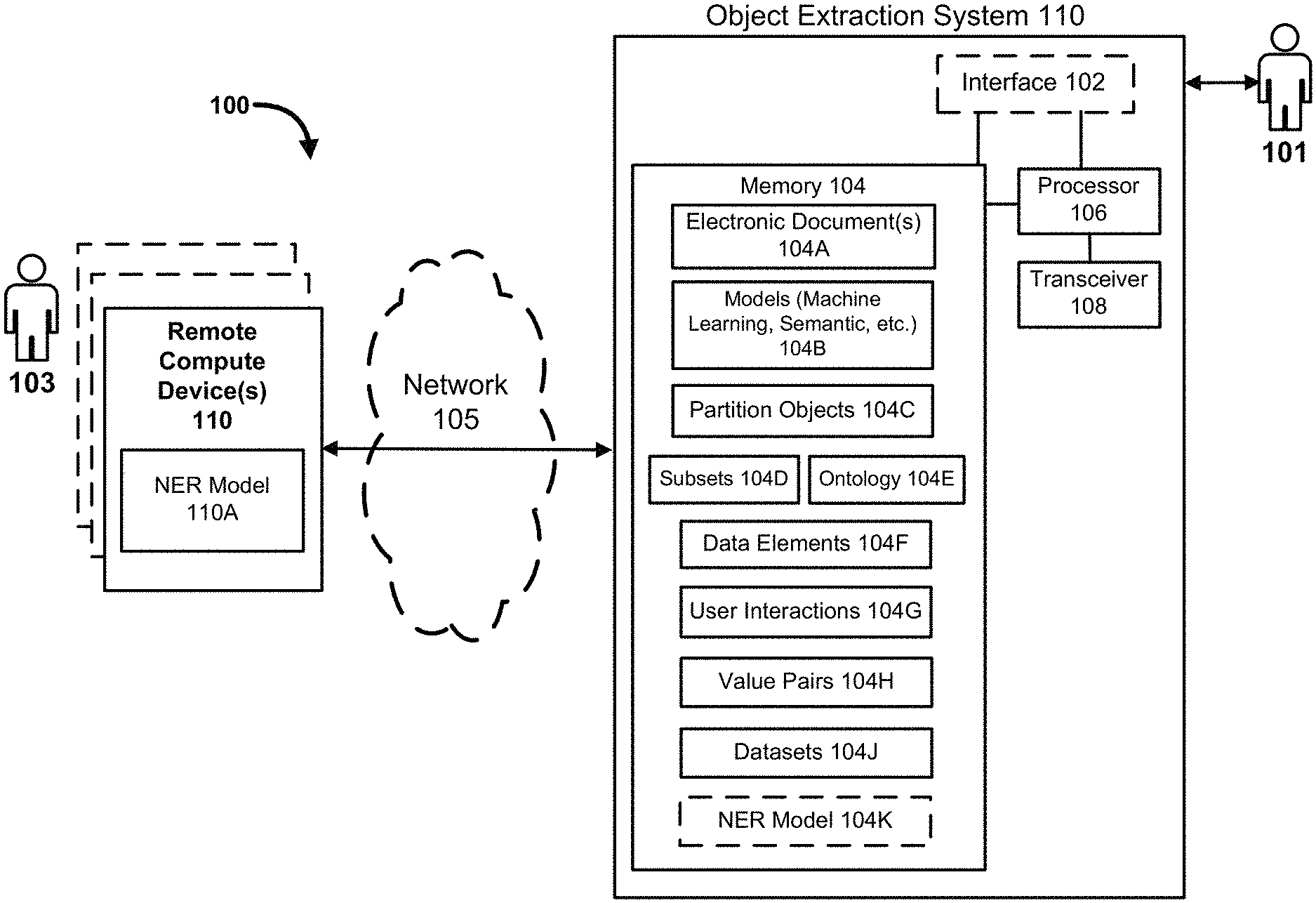
Invented by Dan G. Tecuci, Ravi Kiran Reddy Palla, Hamid Reza Motahari Nezhad, Vincent Poon, Nigel Paul Duffy, Joseph Nipko, Ernst and Young US LLP
Machine learning algorithms have the ability to analyze large volumes of electronic documents and accurately identify and extract partition objects. This technology leverages natural language processing, computer vision, and pattern recognition techniques to understand the structure and content of documents. By training on labeled data, machine learning models can learn to recognize different types of partition objects and extract the relevant information.
The market for machine learning-based extraction from electronic documents of partition objects is driven by several factors. Firstly, the exponential growth of electronic documents across industries has created a need for efficient data extraction solutions. Businesses deal with vast amounts of data stored in various formats, including PDFs, Word documents, and spreadsheets. Extracting valuable information from these documents manually is time-consuming and prone to errors. Machine learning-based extraction offers a scalable and accurate solution to this problem.
Secondly, the increasing adoption of artificial intelligence (AI) and machine learning technologies across industries is fueling the demand for automated data extraction. Machine learning-based extraction from electronic documents aligns with the broader trend of automating repetitive tasks and improving operational efficiency. By leveraging AI, businesses can streamline their data extraction processes, reduce costs, and free up resources for more strategic tasks.
Furthermore, machine learning-based extraction offers significant advantages over traditional rule-based approaches. Rule-based extraction relies on predefined templates or rules to extract data, which can be inflexible and require manual adjustments for each document type. In contrast, machine learning models can adapt and learn from new document types, making them more versatile and accurate. This flexibility is particularly valuable in industries where document formats vary widely, such as healthcare, finance, and legal sectors.
The market for machine learning-based extraction from electronic documents of partition objects is also driven by the increasing availability of labeled training data. As more businesses digitize their documents and invest in data annotation services, the quality and quantity of labeled data for training machine learning models improve. This, in turn, enhances the accuracy and reliability of the extraction process.
Several companies are already capitalizing on this growing market by offering machine learning-based extraction solutions. These companies develop and deploy advanced algorithms that can handle various document formats, extract partition objects accurately, and integrate seamlessly with existing data management systems. They provide businesses with customizable solutions that cater to their specific needs, ensuring a smooth transition from manual to automated data extraction.
In conclusion, the market for machine learning-based extraction from electronic documents of partition objects is expanding rapidly as businesses recognize the benefits of automating data extraction processes. This technology offers a scalable, accurate, and efficient solution to extract valuable information from electronic documents. With the increasing adoption of AI and the availability of labeled training data, the market is poised for further growth. Companies that embrace machine learning-based extraction solutions can gain a competitive edge by improving operational efficiency, reducing costs, and unlocking valuable insights from their data.

The Ernst and Young US LLP invention works as follows
An object extraction method” includes creating multiple partition objects from an electronic document and receiving the first user selection via a computer device’s user interface. A machine learning model is used to detect and display a subset of the multiple partitions objects in response to the user’s first selection. In response to a user interaction with one of partition objects via the user interface a weight in the machine learning is changed, producing a modified model. The user interface receives a second selection of the data item. In response, and using the modified model, a subset of partitions objects is determined and displayed on the user interface. This second subset is different from the previous subset.

Background for Machine Learning based extraction from electronic documents of partition objects
?Document review? Refers to sorting, analyzing and comparing documents and their data. “Electronic documents can be viewed electronically as native files created originally electronically or as electronic versions of documents originally created on hard copy.
In some embodiments, the method of extracting objects from an electronic document includes creating multiple partition objects or?units for analysis? Based on the electronic document and its associated data elements, a user selects a data element through a computer’s user interface. A machine learning model is used to detect a subset of partitions objects in response to the first signal that represents the user-selected element. The user interface displays a representation of each partition from the subset. The user interface detects a user interaction with a display of a first subset partition object. The machine learning algorithm is then modified by adjusting the weight of the model in response to the detection. The user interface of the computing device receives a second signal that represents the data element selected by the user. A second subset is determined from multiple partition objects using a modified machine learning model in response to the second signal. The second subset differs from the first. The user interface displays a representation of each partition from the second set of partition objects.
In certain embodiments, the method of correcting errors in an electronic document includes creating a dataset with multiple value pairs. Each value pair includes an error-free and an error containing value. The dataset is used to train a machine learning algorithm, resulting in a trained machine-learning model. An error in an electronically-stored file is detected, via the trained machine learning model, and in response to detecting the error, the electronically-stored file is converted, via the trained machine learning model, into a modified electronically-stored file that does not include the error.
In some embodiments, the method of correcting errors in an electronic document includes receiving a signal via a user’s interface on a computing device that represents a data element selected by a user for a document associated with a domain (e.g. document type). A first electronic document is found to have an error in response to the first signal that represents the user-selected element. A modified electronic document is created in response to the error being detected. This is done by identifying the value pair that contains an error-containing data element matching the error and replacing the first electronic document’s data segment with the value pair. In response to the modification of the electronic document, a set of objects is identified via a domain-specific (e.g. document type-specific) machine learning model for the domain. The user interface displays a representation of each object in the set. The domain-specific machine model is altered based on a user’s interaction with the representation of an item from the set. The user interface of the computing device receives a second signal that represents a data element selected by the user for a second document with the associated domain. The modified machine learning model is used to detect a set associated with a second electronic document in response to the second signal.
Knowledge workers spend a lot of time looking through electronic documents in order to find information and data of interest. When reviewing a contract in electronic format (e.g. scanned), a knowledge worker can manually search for data elements that are of interest. For example, a knowledge work may manually look up a “Start Date” or “Rent Amount.” Rent Amount? The presence or absence contractual clauses that are of interest such as “Termination Options” or “Rent Amount” or the existence or lack of contractual clauses. Knowledge workers who provide annotations to large volumes of training data in order to generate models are required to exert considerable effort when using known approaches for automating electronic document reviews. These known approaches usually involve the use specialized tools and training the models associated with them is often done outside of the normal workflow. In this way, the time and resources required to set up and maintain such systems are prohibitively high. The extraction of data, such as text, numeric values, etc., can also be time-consuming and resource-intensive. The extraction of data (e.g., numeric, text, etc.) from electronic documents may be inefficient because of errors introduced by automated processes such as optical character recognition processing and automated language translation. Known models such as named entity (NER) can detect a value of a series of characters. However, known NER (classical or learning-based models) cannot parse a set of characters containing an OCR error.
The present disclosure addresses the above issues by combining search and ranking, sequence labelling and error correction capabilities. This allows for object extraction to be performed with greater speed, accuracy, and efficiency than known systems. As additional data is captured during the use of the object extract system/tool, this additional data can also be used to retrain (e.g. of a machine-learning model of the system extraction tool), further optimizing the accuracy and/or efficiency.
Extraction of objects/partitions from electronic documents
In some embodiments, an object extraction method includes dividing up the task of training of a custom data element extraction module into multiple distinct, lower-complexity subtasks that can be independently and/or continuously solved and improved upon. The subtasks can include one or more of (are not limited to): semantic search (e.g., when there is little or no data), ranking (e.g., to identify a most relevant document chunk (also referred to herein as a ?partition?) for a given data element), sequence labeling (e.g., for extracting the actual value from the most relevant document chunk), and online learning (e.g., to continuously improve the object extraction system as the user uses the tool). In some embodiments, the subtasks are combined and/or implemented in an adaptive fashion, depending on the available data. As used herein, a unit of analysis refers to any subset of an electronic document, and is also referred to herein as a ?chunk,? a ?partition,? an ?object,? or a ?partition object.? A data element refers to a subpart of a unit of analysis that contains either a value of interest (e.g. ?Start Date? of a contract) or information from which a user can infer the value (e.g. the existence of a ?Termination Option?). Sequence labeling refers to a pattern recognition task in which labels (e.g., categorical labels) are assigned (e.g., according to an algorithm) to each member/value of a sequence of observed values.
In some embodiments, the method of extracting objects from documents electronic (implemented via an object extraction system), begins with the user defining one or more data elements (e.g. key words, data type, etc.). The definitions of the data elements may be automatically incorporated in a domain ontology, which can contain descriptions of common concepts within the domain. The object extraction system then receives a user’s indication of an interest data element (e.g. via a GUI of a computing device of the object extracting system) and, in response, retrieves, ranks, and highlights (e.g. graphically via GUI rendering) or otherwise “flags” document chunks/partitions within one or more electronic files. the most likely matching document chunk(s)/partition(s) and/or value(s) of the data element (e.g. By applying an appropriate model of sequence labeling. In some implementations, object extraction systems perform the ranking (at first) by performing a search using the domain-ontology or the definition of data elements.
Subsequently as a users uses the object extract system (e.g. when a user navigates an electronic document by viewing it and/or moving within the GUI), the user selections are captured and used to improve retrieval, ranking and highlighting in the object removal system. The machine learning model for the object extraction system, can be modified automatically or based on the user’s selections. In some implementations, the modified machine-learning model(s) is given greater weight in retrieval and ranking as the number of user interactions increases. Once a specified/predetermined threshold predictive accuracy and/or a specified/predetermined threshold number of user interactions has been reached, the semantic search may be turned off, removed or deactivated such that the modified machine learning model is exclusively used (i.e., without using the semantic search or any other type of search) for the retrieval and ranking. According to certain embodiments, there are a series of models which can be used in succession (or predefined times) for example as a response to predetermined events, according to one or several rules, such as for online learning (i.e. “learning on the Job”). A semantic model, similarity model and machine learning model (e.g. a neural net) are all included in a set of models that can be used sequentially or at predefined times, for example, to respond to events according one or more rules. In some implementations, the transitions between models can be based or triggered on accuracy and/or weights associated with models. A set of 25 examples, for example, can be divided up into a “test” and a “training? Data sets can be divided into a “test”DATASET and a “training”DATASET. Cross-validation based on the testDATASET and trainingDATASET data sets allows for the calculation or detection of accuracy in presently used models. Data set, and cross validation based on the training data and test data sets can be used to calculate or detect the accuracy of the model currently employed. If the accuracy calculated or detected is greater than predetermined threshold?X? Machine learning can be used (e.g. exclusively). However, if the accuracy of the detected/calculated data is below the threshold set?X?, then machine learning may be used (e.g., exclusively). If the calculated/detected accuracy is less than the predetermined threshold?X,?

The baseline model can be updated by the user during their use of the system. Baseline models can include a ranking model, for instance. With a small amount of information, ranking models can still be very effective. When a generic named entity recognition (NER), which identifies such entities as dates, money and organizations, is used, the object extraction system can be trained using a fraction of the data that would otherwise be needed to build a complex model. As the initial sequence-labeling model, an object extraction system is trained with a fraction the data needed to build complex models to accurately extract values in a large electronic file. The value and the context (document chunks or paragraphs) are saved when the user selects the value of a data field. The context helps improve the ranking model, and the value helps improve the sequence-labeling model. The object extraction system will continue to improve as user interaction continues. However, when the data is sufficient to further improve accuracy, both the sequence labeling and ranking models can be trained together.
Corrections of Errors
Optical Character Recognition (OCR)” is a method by which an image (whether typed or printed) of a text is converted electronically into machine-encoded text. For example, a first electronically-stored file (e.g., an ?electronic document?) Image data can be used to represent text. The first electronically-stored file is converted into a second, machine-readable electronically-stored file. The OCR conversion of an electronically-stored file can introduce errors that are difficult to detect and/or repair. If, however, a ?type? associated with one or more portions (e.g., data elements, strings, values) of the OCR-converted electronically-stored file (e.g., a data element type, a string type, or a value type) is detected or known, the speed, accuracy and/or effectiveness of remediation of such errors can be vastly improved, for example since the number of potentially identifiable candidate replacement data elements, strings, or values is considerably reduced.
In some embodiments, an object extraction system performs error correction/remediation for one or more error-containing data elements, strings, and/or values of an electronic document, based on an associated type of the data elements, strings, and/or values. The object extraction system can detect the type of one or several data elements or strings and/or value upon receipt or inspection of such data, or it can determine the type based on the type stored in the memory of the object extract system. In some implementations, OCR errors can be corrected by one or more users via the GUI of the object extract system.
In some embodiments, targeted information extraction from one or more electronic documents is performed using a type-aware (e.g., context-dependent), learning based approach for converting/correcting values extracted, for example, from text of the electronic documents) that contains character recognition errors (e.g., optical character recognition (OCR) errors). The correction of document values (e.g. text or numeric value) as described in this invention can be done automatically, for example, using a machine-learning model that learns to correct errors based on training data. The correction of document values (e.g., text or numeric values) as described herein can be performed in an automated manner. For example, a machine learning model that learns (e.g., based on training data) to correct errors for strings having a defined string type (e.g.?DATE? etc.). As an example, the string?Sept 5 200 1?” can be detected by the object extraction system (e.g. in response to receiving the string). The object extraction system may detect (e.g. in response to receiving a string) that it contains at least one error. The object extraction system can detect (e.g., in response to receiving the string) that there is at least one error. Between the?0,? The string ‘Sept 5 2001,? was replaced with a corrected version ‘Sept 5 2001? The string “Sept 5, 2001” was replaced by a correct string?Sept 5, 2001? The object extraction system
Hybrid Textual Correction and Object Extraction
The method of object extraction and textual correct can include the detection by the object extraction system of the data element type (string type), value type (e.g. the type associated with the error-containing string), as well as the training of a sequence-tosequence-model to enable it to translate the error-containing string into valid strings that have the same data type, value type or string type. The method of object extraction and textual correct can include detection by the object extract system of the data type, value type, and string type of the error-containing strings (e.g. when it is received or inspected by object extraction system), as well as matching the error-containing strings to one or more candidate replacements having the detected data type, value type, and string type.
In some embodiments, the object extracting system generates or acquires/receives a dataset consisting of pairs of values for each type of data element, string, or value (e.g. from a remote computing device connected to the object extracting system via a network). The object extraction can receive information about the data element type (string type) and/or the value type from a local NER model that is executed at the system or a remote computing device connected to the system over a network. Each pair of values may include an original value, e.g. pre-OCR, and a converted one, e.g. including/containing OCR-imparted error. The dataset can be used to ‘train’ a sequence-to sequence model so that it ‘learns. The dataset can be used to train a sequence-to-sequence model so that the model?learns? In some implementations the values of the dataset are based upon actual/observed data. In some implementations, in addition to or instead of actual/observed data, one or several artificial datasets may be generated. In other implementations, either in addition to the actual/observed dataset or instead of it, one or more artificial datasets can be generated (e.g. by introducing errors into an electronic document, for example by inserting errant spaces, changing?1? Change?0 to?0? Change?0?? values to?0?? values, etc. values, etc. (and used to train the Sequence-to-Sequence Model).
In some embodiments, the semantic model or “ontology” is used. “In some embodiments, a semantic model or?ontology? for an electronic document can be generated by capturing the concepts and relationships that are relevant to the ‘domain? This electronic document is referred to as the?domain’. If the electronic document is an agreement, then the domain can be the subject matter descriptor which refers to the specific sphere of knowledge or activity (e.g.?real estate? ?mortgage,? ?Non-Disclosure agreements,? etc.) Or a document type. An ontology may include a list of “attributes of interests”. For the electronic document (i.e. a single document, optionally only relevant to this electronic document or type of electronic document), the attributes are, for example: known or anticipated fields associated with this electronic document and/or expected or known fields associated with its domain. A profile can be predefined. A profile for a contract of sale, for example, can include the commencement date, end date, termination clause and sales price. The object extraction system can store the association between a profile and an electronic documents identifier in its memory. When a document type is not yet added to the object extract system, a blank template can be created and filled in by the user. During operation, an existing ontology can be used to initialize the object extraction system (i.e. a “reference ontology”). Optionally, the reference ontology can be associated with one domain. The reference ontology may include parameters, such as entity, date and time, etc. as well as concepts, relationships, and pre-trained model models. The ontologies disclosed herein can be updated dynamically, such as during use. “When the user defines a field.
As mentioned above, according to certain embodiments, an example of a series of specific models that can used in sequence (or predefined times), for example, in response to predetermined event according to one rule, is, according to some embodiments, online learning (i.e. ‘learning on the Job? The machine learning models include a neural net, multilayer perceptron model, or convolutional neural networks (CNN). In certain embodiments, the object extracting system can identify and score partition objects (or units for analysis) in an electronic document based on the model currently being used. In Table 1, we compare three types of models, including a similarity model and a semantic or MLP model.

Model Description UsenSimilarity cosine similarity for a term, and the partition objects that are to be updatednprediction should be done during initializationnonline learningnSemantic full semantic: Ontology driven classification. New and existing fields.nIdentifies the definitions, occurrences defined online when newnterms are added. Added fieldsnIdentifies entity (e.g. dates). Thenpartitionnobject is scored based on terms andnentities and thencosine similarity of the?description’. The description of a word is derived fromnontology, (synonyms and keywords),nand/or the description added by the user.nnMLP Multi-layer Perceptron. New and pre-trained field.

Click here to view the patent on Google Patents.

