ERROR RESOLUTION AND AUTO-CORRECTION FOR UNPROCESSED DATA RECORDS

Invented by SOM; Indranil, MUKHERJEE; Partha, BHATTACHARYYA; Surajit, DAS; Sabyasachi, BHATTACHARJEE; Rupa

Today, we look at a patent application that could change the way computer systems handle errors during data processing. This invention gives computers a way to spot errors, fix them, and keep things moving without needing a person to step in every time something goes wrong. Let’s break down what this means for the tech world, why it matters, how it builds on what people have tried before, and what makes this invention new and useful.
Background and Market Context
Every day, computer systems around the world process huge amounts of data. This data could be anything from sales records and medical information to financial transactions or customer details. Companies depend on these systems to work smoothly. But sometimes, something goes wrong. Maybe the computer runs out of memory, or two programs try to use the same thing at the same time, or there’s a mistake in the code. When this happens, some of the data does not get processed. These are called “skipped records.” Skipped records are a big problem. They can slow down business, make people wait, or even lead to lost money.
For example, think about a hospital. Every time a patient gets a treatment, the hospital’s system records it. Later, the system uses this record to create a bill and send it to the insurance company. If an error happens during this process and some records are skipped, the hospital might not get paid for those treatments. The same thing can happen in banks, stores, or any place that uses data to run its business.
In many companies, when errors happen, the system just skips the record and moves on. The error gets logged somewhere, but nobody notices right away. Later, someone has to read through the error logs and try to figure out what went wrong. This can take a long time. Sometimes, nobody catches the problem until it causes even bigger issues — like missed payments, unhappy customers, or more errors down the road. Fixing these mistakes often requires a lot of manual work from IT teams. This is slow, expensive, and not always effective.
Because of this, many organizations have been searching for better ways to find, fix, and re-process skipped records. The goal is to keep the business running smoothly, save money, and avoid delays. In fast-moving industries like healthcare, finance, and retail, the need for quick, automatic error handling is especially urgent. As data grows and systems get more complex, the risks of manual error handling get bigger too.
This is where the invention in this patent application comes in. It offers a way for computer systems to notice errors right away, understand why they happened, and fix them without waiting for someone to help. The system uses a mix of smart software, historical knowledge about errors, and user-friendly screens to make everything work together. With this, businesses can save time, avoid losing money, and make sure their data gets processed right the first time, or as soon as possible after an error.

Scientific Rationale and Prior Art
Let’s talk about the science and old ways of handling problems in data processing. Computers process data using programs that follow certain rules. When a program hits a problem — like bad data, missing information, or a system resource that isn’t available — it writes an error message in a special file called an error log. These logs are like diaries for the computer, telling what went wrong, when, and sometimes why.
Traditionally, fixing skipped records has not been easy. The normal process looks like this: a job fails, the system logs the error, and the person responsible for the system has to read the logs, figure out what type of error happened, and decide how to fix it. Sometimes, the fix is easy: just run the job again. Other times, a human has to dig deeper, change some data, or even change the code. In big systems, there can be thousands of error messages a day. Manually sorting them takes too long and mistakes happen.
Some older systems have tools to help. For example, they may group similar errors together, or let users search logs for certain words. But they don’t actually fix the errors. At best, they make the error logs a little easier to read. Other tools let users replay or re-run failed jobs, but they don’t try to understand the reason for the error, or fix the root problem.
In some industries, there are special programs that check for certain known errors and can apply a fix. For example, if a database gets out of sync, a script might be run to fix it. But these solutions are often built for one problem at a time, and they don’t learn from new errors or adapt to different systems. They also need to be updated often by skilled people, which makes them hard to manage.
There are also systems that use machine learning to look at lots of error logs and try to spot trends. These can help predict when errors might happen, or group similar errors together. But again, these systems usually stop at showing patterns — they don’t actually fix errors by themselves.
Finally, most computer systems are not set up to show the business impact of skipped records. For example, in a hospital, there may be no easy way to see how much money is “stuck” because of skipped billing records. This means that the real cost of errors is often hidden.
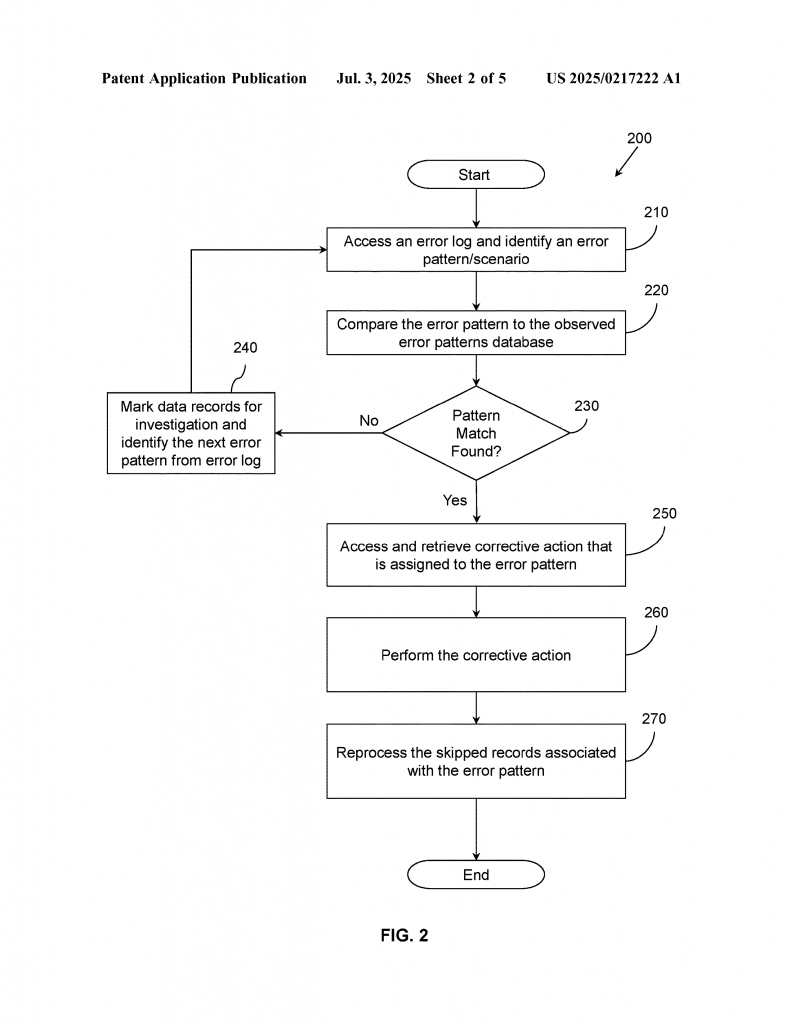
This patent builds on these ideas but takes them a step further. It combines error detection, pattern recognition, historical error knowledge, and auto-correction into one system. It also builds an easy-to-use screen where people can see what errors happened, what they mean, and what is being done to fix them. Most importantly, it lets the system fix itself, whenever possible, and shows the results right away.
Invention Description and Key Innovations
Now, let’s look at how this invention works and what makes it new. The main idea is to create a computer system that can find, understand, and fix errors in data processing — all on its own, or with a little help from a user, using a graphical interface.
Here’s how the invention works, step by step:
First, after a computer job runs, the system checks the error log. It looks for error messages that show some records were skipped. Each error message usually includes details like what job was running, what kind of error happened, the data or tables involved, and a short description of what went wrong.
The system then tries to make sense of these errors. It does this by picking out key parts of each error message — like the error type, the names of the data tables, and the job name. It uses these parts to create an “error pattern.” The system compares this error pattern to a database of past error patterns it has seen before. Each pattern in the database has a fix, or “corrective action,” attached to it.
If the system finds a match, it knows what to do next. It applies the corrective action to the skipped records. For example, if the error was a resource deadlock (where two jobs are waiting for each other), it might just re-run the job, hoping that the problem was temporary. If the error was a data mismatch (like two tables that are supposed to match but don’t), the system could fix the bad data based on rules from the database.
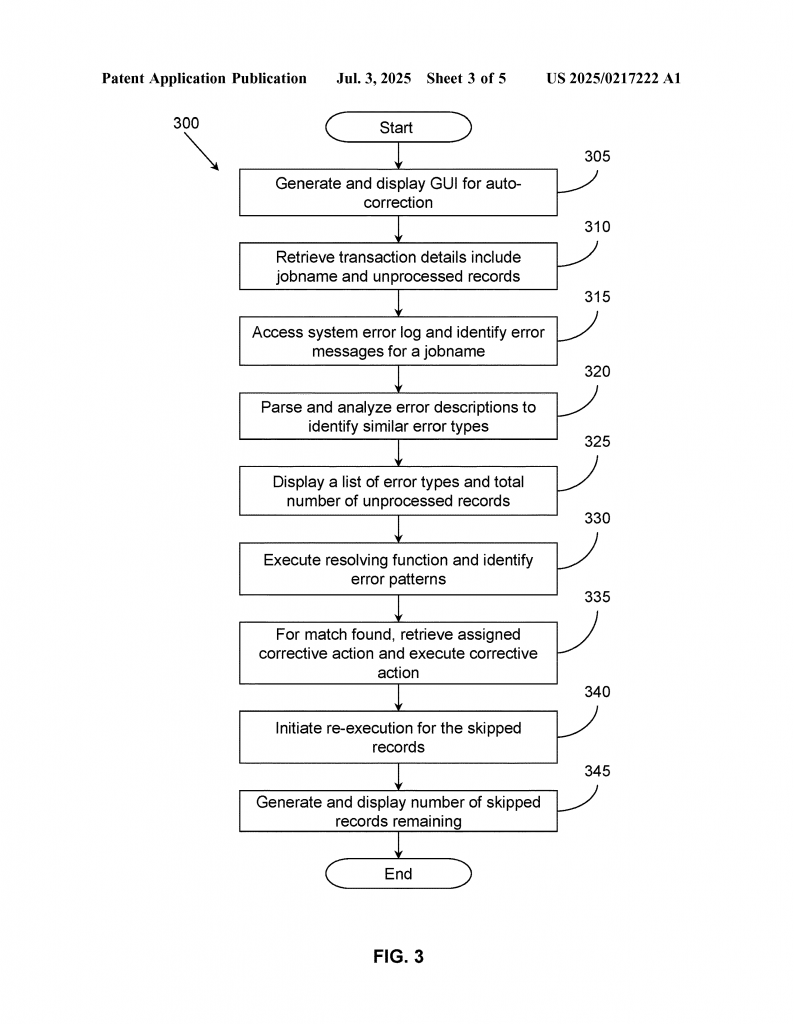
After the fix, the system tries processing the skipped records again. It checks to see if the errors are gone. If so, it shows that the problem is fixed and how many records are still skipped (if any). If not, or if the error is new, it marks the problem for a person to look at later.
One key part of the invention is the graphical user interface (GUI). This is a set of screens that show the user a summary of jobs, skipped records, error types, and the amount of money (or other resources) affected by the errors. The user can pick a job, see what errors happened, and, if needed, trigger the system to try to fix them. The screens make it easy to see what’s going on, without digging through raw error logs.
Another important part is the system’s use of history. The more errors the system sees, the better it gets at recognizing patterns and knowing what fixes work. Over time, the error pattern database grows, and the system can handle more types of problems without needing help. If it sees a new error, it can flag it for someone to investigate and add a fix, so it can be handled automatically next time.
Some examples of how this works in practice:
– In a hospital billing system, the invention can spot skipped billing records, figure out if the problem was a calculation error, and fix the data so the bills go out and the hospital gets paid.
– In a retail system, the invention can find sales records that didn’t process, fix problems with inventory tables, and make sure the sales are counted.
– In a banking system, it can catch failed transactions, check for matching past errors, apply fixes, and re-run the transactions.
The invention also tracks the impact of skipped records. For example, in healthcare, it can show the total dollar amount of bills that are stuck because of errors. This helps the business know where to focus, and how much is at stake.
What makes this invention stand out is that it brings together several things that used to be separate:
– It finds errors in real time, not days or weeks later.
– It groups similar errors so they’re easy to understand.
– It remembers past errors and how to fix them.
– It lets the system fix itself, wherever possible, and shows the results right away.
– It gives users a clear, simple screen to see what’s happening and, if needed, step in.
– It works across many kinds of systems and data types, making it flexible for different companies.
The technical details in the patent show how the invention handles error logs, extracts and processes error patterns, matches them to known problems, applies fixes, and keeps track of everything in a way that is safe and transparent.
From a business perspective, this means less downtime, fewer lost records, faster reaction to problems, and, for industries like healthcare, faster payments. From a technical perspective, it means fewer manual interventions, a system that learns and adapts, and a better way to manage the growing complexity of modern data processing.
Conclusion
This patent application introduces a new way for computer systems to handle errors during data processing. Instead of leaving problems for people to find and fix, it gives the system the tools to notice, understand, and often fix errors on its own. By combining error pattern recognition, historical knowledge, corrective actions, and easy-to-use screens, it offers a smarter, faster, and more reliable solution for businesses that depend on accurate, complete data processing. As data grows and business speeds up, tools like this will become even more important for keeping systems running smoothly and for protecting the bottom line.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217222.

