Effortlessly Track and Update Data Sets Across Cloud Networks With Automated Lineage Management
Invented by Rao; Karthik Ravindra, Puligilla; Raghu Chaitanya, Sartorello; Enrico, Marshall; Michal, AYOUB; AMEER NIZARSAMI, Sutaria; Kalpesh N., Kohan; Paul Matthew, Bhadauria; Vivek, Pokkunuri; Rama Krishna Sandeep, Mirza; Hammad Latif, Agarwal; Kshitiz Mohan, Yuan; Yong, Amazon Technologies, Inc.
Managing data in the cloud is getting more complex every day. With so much data being used in machine learning and analytics, it’s easy to get lost in all the versions and changes. Today, we’re going to look at a new system for handling data sets, using something called “data set lineage metadata.” We’ll take you through what’s happening in the market, why this is needed, and how this new invention works. By the end, you’ll see how this approach changes the way we manage big data in the cloud.
Background and Market Context
Let’s start by understanding the world we’re living in. Data is everywhere. Every company, big or small, wants to use data to improve their products and services. Machine learning, artificial intelligence, and analytics need lots of high-quality data to work well. But gathering, storing, and updating all this information is not easy.
Imagine you’re a company with millions of customer records. Every day, new data comes in. Old data gets updated. Some data needs to be deleted. Now add in rules about data privacy, like GDPR. If someone wants their data removed, you have to make sure it’s gone from everywhere, not just one place. This is called “compliance.”
For machine learning, data scientists often create many versions of a data set. They might take the main data and filter it down to just certain types of events, like only restaurant visits or only customers from a certain country. Each filtered set might be used to train a different model. But when the main data changes, all the child data sets need to be updated too. If you do this by hand, it’s slow and mistakes can happen.
Cloud providers like AWS, Azure, and Google Cloud have made it easier to store and process data, but managing many related data sets is still a headache. Companies want to automate as much as possible, so they can spend less time fixing data and more time building products. The market is asking for smarter data management systems that can track data changes and update all related data sets automatically. That’s where this new invention comes in.
Scientific Rationale and Prior Art
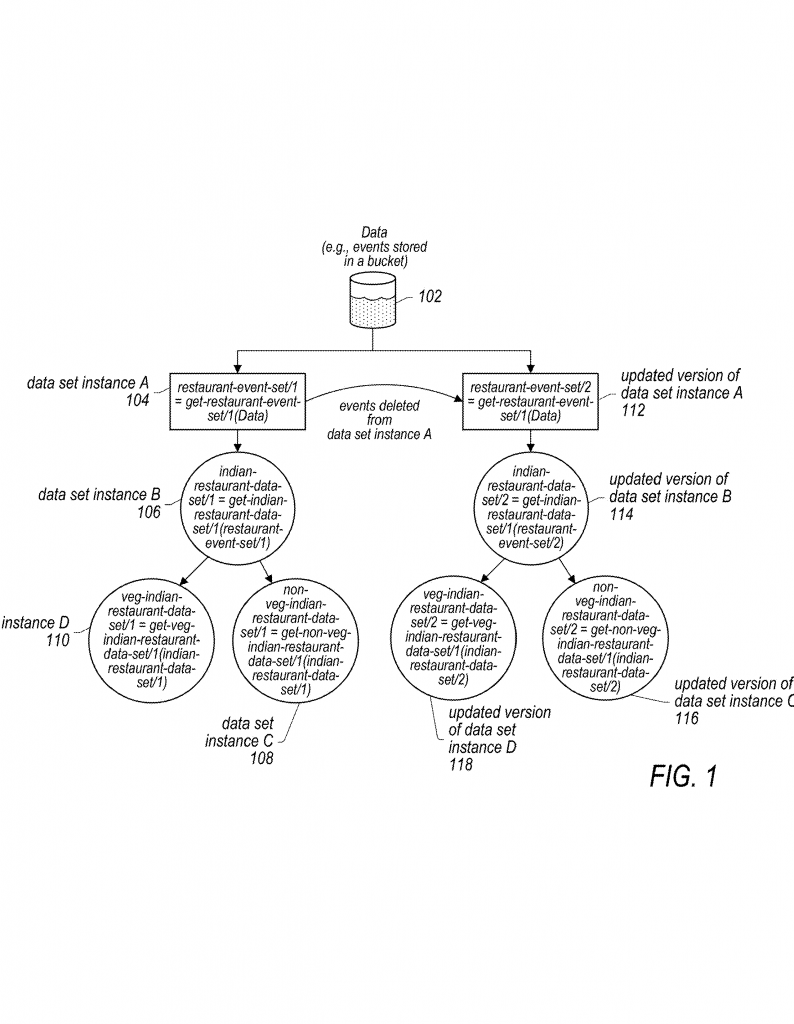
To see why this invention matters, we need to look at what’s already out there. Traditionally, companies use scripts and tools to transform data. For example, they might write a SQL query to pull out all restaurant events from a big table of events, then save that as a new data set. If they need to go further, they might filter that restaurant data to just Indian restaurants, and then filter again to just vegetarian places. Each step creates a new data set.
But here’s the problem: these steps are often done one at a time, by hand, and the connection between each data set is not always clear. If you delete some records in the main table, you have to remember to update every child data set, or your data becomes out of sync. If you forget a step, you might end up with old or wrong data in your models. This can lead to bad business decisions or even legal trouble if you’re not following data privacy laws.
Some tools have tried to help with this by offering “data pipelines” or “ETL” (Extract, Transform, Load) workflows. These let you define a series of steps, but they don’t always track the full history, or “lineage,” of each data set. They might not make it easy to update just the parts that changed, or to know exactly which child data sets need to be refreshed when the parent data changes.
Another problem is scheduling. Machine learning workflows might need new data sets every day or every week. If you’re doing this manually, it’s easy to miss a run or use the wrong version of a transformation. There’s also the issue of access control. Not every user should have permission to change every data set or transformation. Managing all these permissions is hard in big organizations.
So, the prior art is a patchwork of manual scripts, ETL tools, and workflow systems that don’t always work together. They’re good for simple jobs, but they fall short when data management gets complicated. What’s missing is a system that tracks every step, knows how data sets are related, and can automatically update everything when something changes. That’s the scientific reason for this new invention.
Invention Description and Key Innovations
This invention introduces a system for data set management using “data set lineage metadata.” Here’s how it works, in simple words.
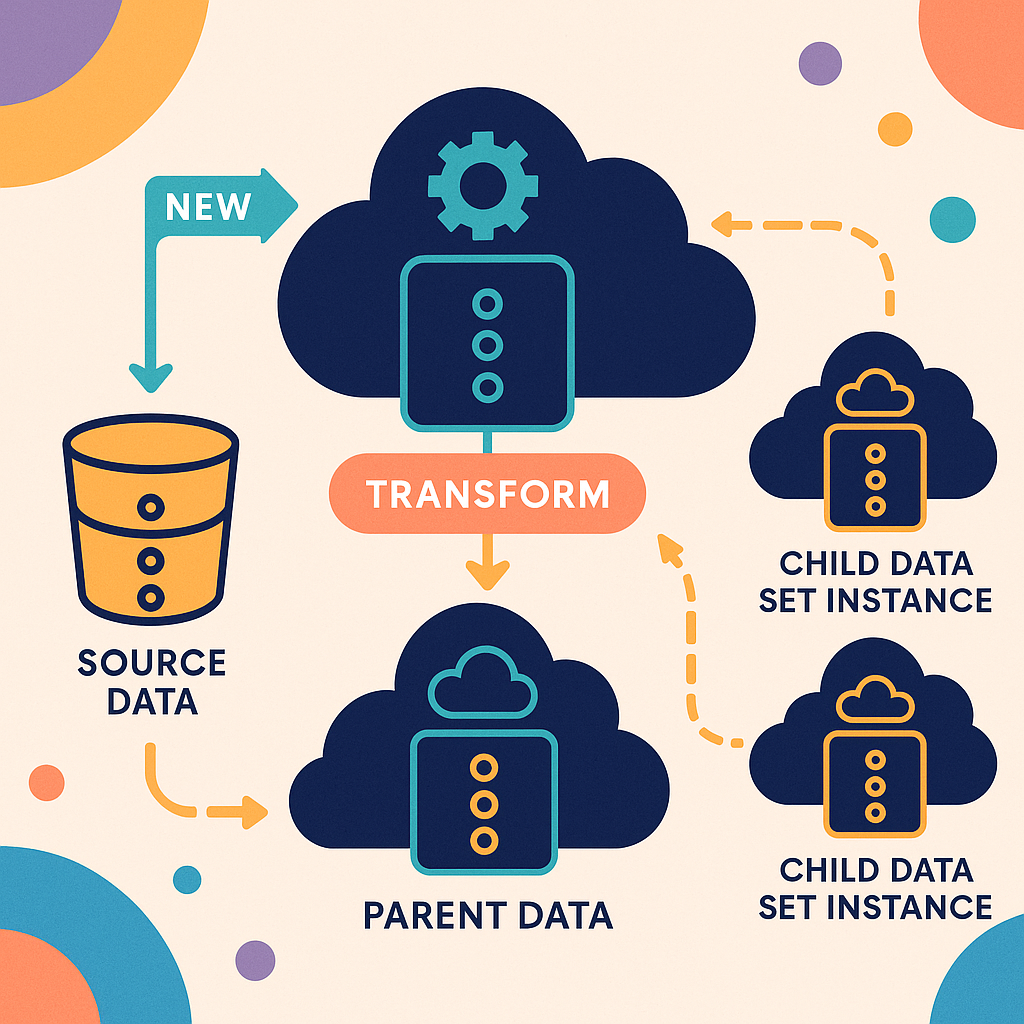
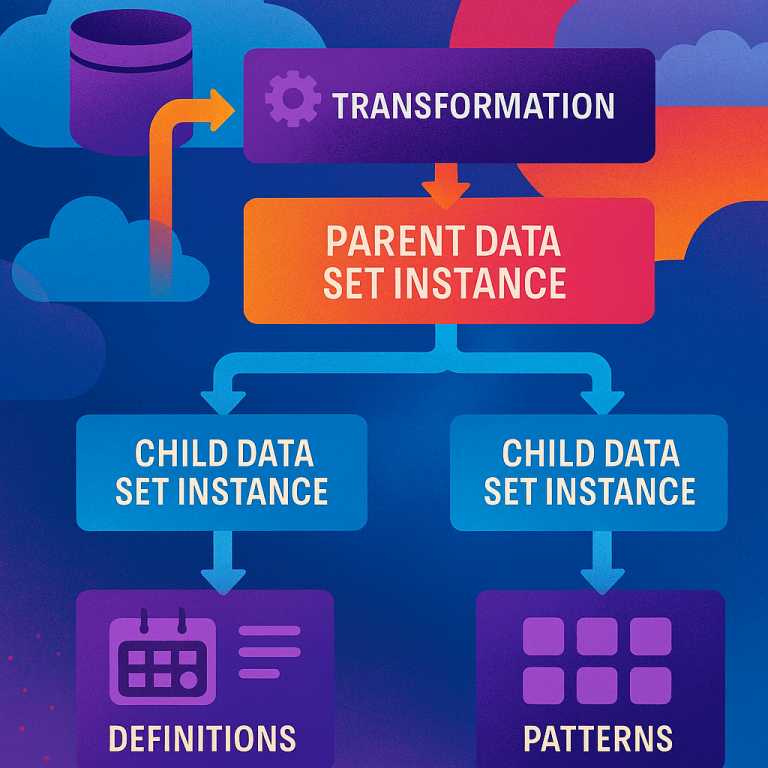
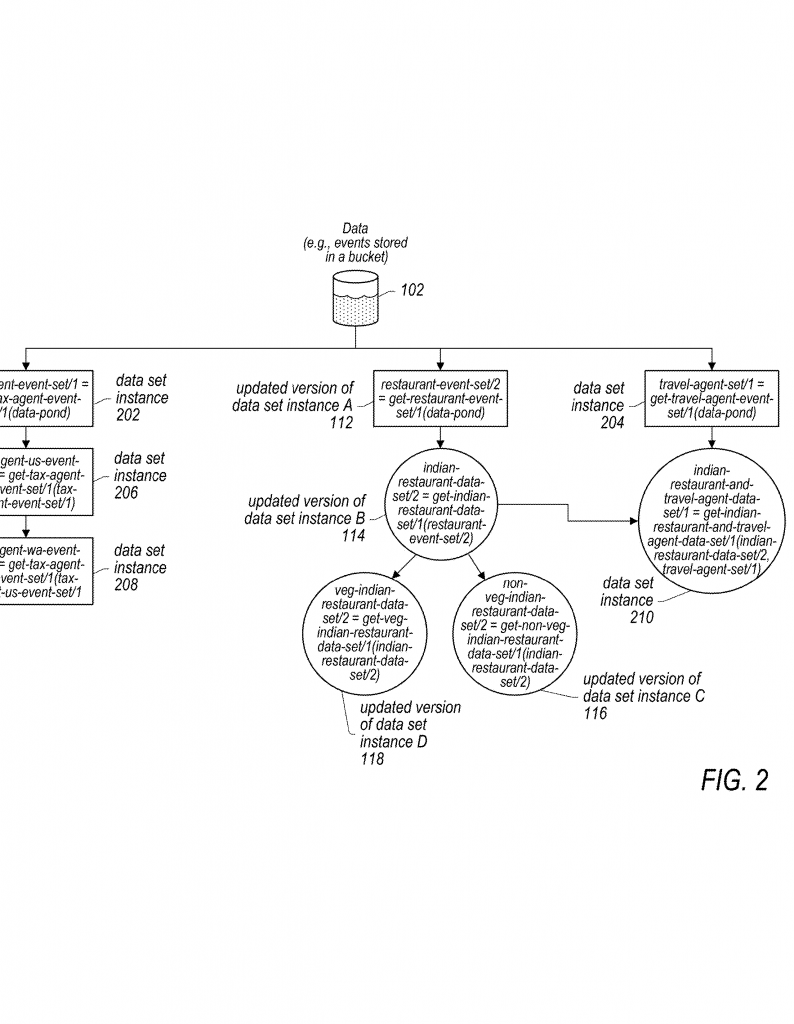
First, imagine every data set as a “node” in a tree. The main data is at the root. When you create a filtered data set, like “restaurant events,” that’s a child node. If you filter that to “Indian restaurant events,” that’s another child, and so on. Each step, or transformation, is recorded as metadata. This metadata keeps track of what was done, when, and to which data set.
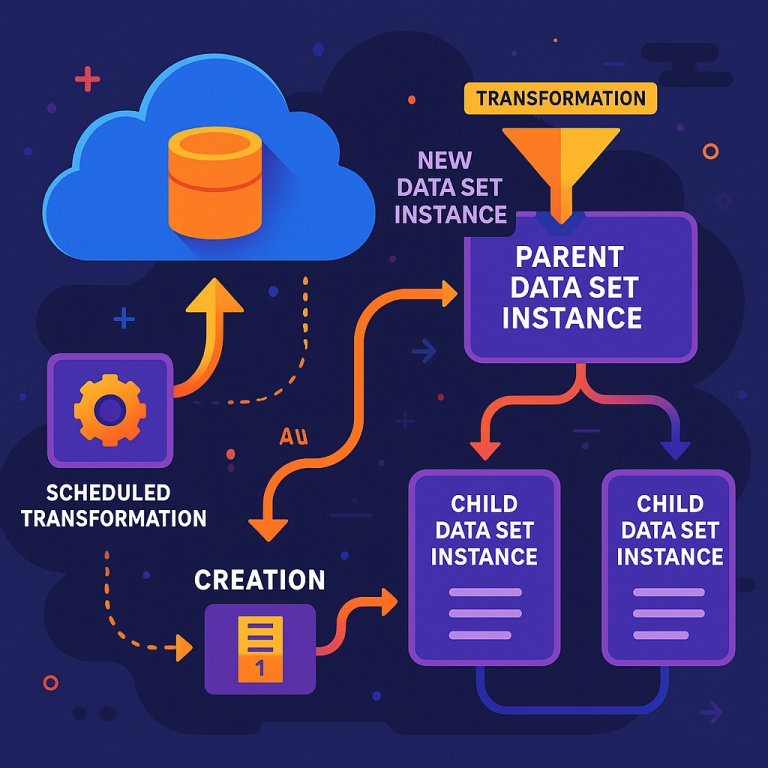
Now, if the main data changes—maybe you add, delete, or update records—the system automatically checks the lineage metadata to see which child data sets are affected. It then runs the right transformations to update each child. This is done automatically, so you don’t have to remember each step or write new scripts every time. The system also supports scheduling, so you can tell it to run certain transformations every day, week, or whenever you want.
The key innovations are:
1. Automatic Propagation of Changes: When the source data changes, the system uses the lineage metadata to update all related data sets. This ensures that every child data set is always in sync with its parents. You don’t have to worry about old or wrong data sneaking into your models or reports.
2. Clear Data Set Lineage: By recording each transformation and the relationships between data sets, you can always see where any piece of data came from. If you need to delete data for privacy reasons, the system knows exactly which data sets need to be updated to remove it everywhere.
3. Flexible Transformation Engine Selection: The system can pick the best transformation engine for each job. If you have different engines that are better for different types of queries, the system chooses the right one automatically. This makes things faster and more reliable.
4. Labeling and Discovery: You can assign labels to data sets, like “veg,” “Indian,” or “restaurant.” This makes it easy to find the data sets you need later, even as the number of data sets grows.
5. Scheduled Transformation Patterns: You can define a series of transformations as a pattern and run them on new data sources as needed. This is great for machine learning workflows that need regular updates.
6. Fine-Grained Access Control: The system lets you control who can do what, at every level. Some users can only read data, others can create new data sets or transformations, and so on. This is managed using the same metadata system, so it’s always clear who has access to what.
7. API-Driven Automation: All actions can be done using an API, which means other systems or users can automate data management tasks without manual intervention. You can create, update, label, or delete data sets and transformations using simple API calls.
Let’s walk through a practical example. Imagine you run a chatbot that collects user utterances. You want to create training data sets for different types of restaurants. Using this system, you create a top-level “restaurant event” data set from all your raw data, then filter it down to “Indian restaurant events,” then to “vegetarian Indian restaurant events.” The system records each step. Later, if you need to delete all events from a certain user for GDPR compliance, you delete those events from the main data set. The system automatically updates every child data set, removing those events everywhere. You don’t have to check each one by hand.
This approach saves time, reduces errors, and keeps data clean and compliant. It also makes it easy to experiment with new data sets, knowing they’ll always be up to date when the source data changes.
Conclusion
Managing data is getting harder as companies use more and more data sets for analytics and machine learning. The old ways of doing things—manual scripts and simple ETL tools—can’t keep up. This invention solves the problem by recording every transformation in metadata, tracking how data sets are related, and automatically updating everything when changes happen. It brings automation, reliability, and transparency to data management in the cloud. For any business dealing with lots of data, this system offers a smarter, safer, and faster way to keep your data sets in sync and your business moving forward.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250335395.

