DISTRIBUTED IN-DATABASE VECTORIZED OPERATIONS USING USER DEFINED TABLE FUNCTIONS
Invented by Dorairaj; Pradeep, Frere; Garrett
Welcome! Today, we’re going to take a deep dive into a new and powerful way to process data inside cloud databases. This method lets us quickly and efficiently find connections—called “correlations”—between lots of columns in big tables. The secret sauce here is something called a “user defined table function” (UDTF), which allows the work to be shared across many computers at once. This makes even the hardest data problems much easier to solve. Let’s break down what this means, why it matters, and how it works.
Background and Market Context
Imagine you’re working with a giant table of data in the cloud. This table could have millions of rows and hundreds or even thousands of columns. Maybe it’s information about users, products, or transactions. Companies need to find patterns and relationships in this data to make good decisions. For example, a business might want to know which features in their data help predict customer choices, or which products are often bought together. To do that, they often use a measure called “correlation.”
Correlation tells you if two things move together. If sales go up when advertising goes up, those two things are correlated. If the weather gets colder and coat sales increase, that’s another example. Finding these relationships helps businesses plan, predict, and improve.
But there’s a catch. With today’s cloud tools, datasets are growing bigger and wider all the time. It’s easy to store all that data, but much harder to analyze it quickly. If you want to check the correlation between every pair of columns in a table with, say, 10,000 columns, that’s almost 50 million pairs! Doing this on one computer or with regular database tools is slow and expensive. It can even be impossible if the data doesn’t fit into the computer’s memory.
That’s where the new distributed system comes in. Instead of one computer doing all the work, the system splits the job across many “execution nodes.” Each node works on a slice of the data, and then the results are combined. This is like giving a huge pile of homework to a class and letting everyone do a small part. When everyone finishes, you put the answers together and you’re done much faster. This approach is called “distributed computing,” and it’s perfect for the cloud, where you can add or remove computers as you need.
But splitting up the problem isn’t always simple. Data is often stored in rows and columns, but the math needed for correlation works best when the data can be treated as vectors. That means we need a way to turn parts of our tables into these “vectors” and process them quickly. The system we’re talking about uses user defined table functions (UDTFs) to make this possible. UDTFs are like special helpers that know how to take a chunk of data, do some math, and return the result. By sending different UDTFs to different nodes, the system can crunch through huge jobs in parallel.
This setup helps not just with speed, but also with flexibility. You can scale up for big jobs, scale down when you’re done, and handle failures more easily. If one node goes down, another can take over. The end result: businesses can get answers from their data much faster and at a lower cost, making it practical to use these techniques even for huge tables.
In short, as cloud databases become more central to business, the need for fast, in-place analysis grows. This new distributed approach is the next step in making sure insights keep up with the data.
Scientific Rationale and Prior Art
Let’s talk about why this new method is special, and what came before it.
The main goal is to calculate the Pearson correlation. This is a standard way to measure if two columns in a table are related. If the value is close to 1, they’re strongly linked; if it’s close to 0, they’re not.
Traditionally, people used tools like Python’s Pandas or R for this job. These tools are great, but they have limits. They usually work on a single computer. If your table is too big to fit into memory, you’re stuck. Even if it fits, checking all pairs in a wide table takes a lot of time, because the number of pairs grows very fast as you add more columns.
Old-style databases could do some math, but they weren’t built for heavy vector math like this. They could scan rows or columns, but not easily turn groups of them into vectors for quick calculation. Plus, they didn’t let you split the work across many nodes automatically.
The idea of breaking a job into “shards” isn’t new. In the past, some data systems used “sharding” to spread data across servers. But this was mainly for storing and finding data, not for running complex math jobs like correlation. Also, earlier systems often copied data out of the database for analysis, which is slow and risky.
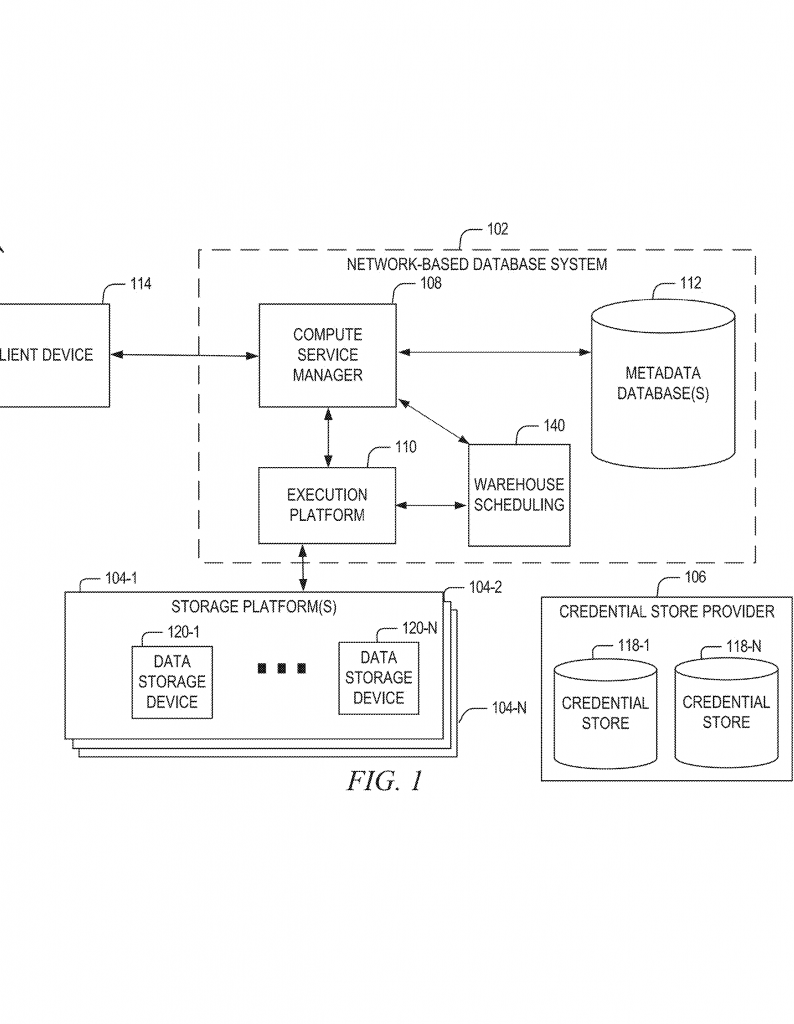
This patent’s big step forward is to keep everything inside the database, and let the database itself do the heavy math, using its own distributed resources.
The scientific trick here is to turn the normal, slow summing of values into fast “dot products.” A dot product is a math operation that works well with vectors and can be done very fast on modern hardware, especially when you can process many at once. The patent takes the normal formula for correlation, breaks it down into these dot products, and uses “vector chaining” so that many calculations can be done together. This means you can get all your answers with much less work.
Another useful idea is using UDTFs to run these vector operations. Most databases let you write user defined functions (UDFs), but UDTFs are designed to work on whole tables or slices at once. This fits perfectly with the idea of sharding and parallel processing.
Earlier systems either couldn’t do this at all, or did it much less efficiently. They might work for one pair of columns, but not for all pairs in a big table. They couldn’t take advantage of the full power of distributed, in-database computing, often leading to slow speeds and high costs.
In summary, the science behind this invention is a clever mix of math (dot products, vectorization), computing (sharding, parallelization), and database design (UDTFs, distributed processing). It lets you turn a very hard problem into one that’s fast and practical, even for huge datasets.
Invention Description and Key Innovations
Now, let’s walk through exactly how this new system works, step by step.
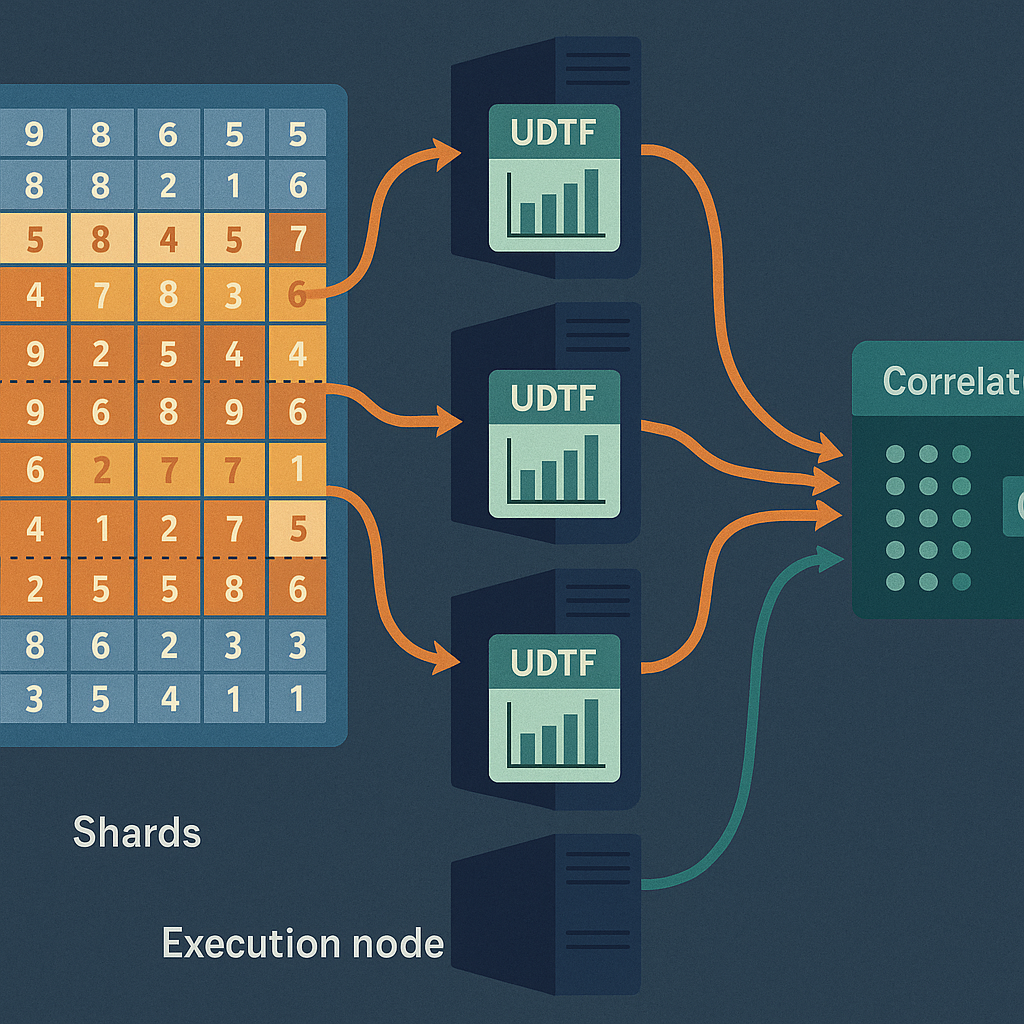
First, when you want to find correlations in your data, you send a request to the database. The system looks at the data set: how many rows are there? How many columns? And how many execution nodes (computers) are available to help?
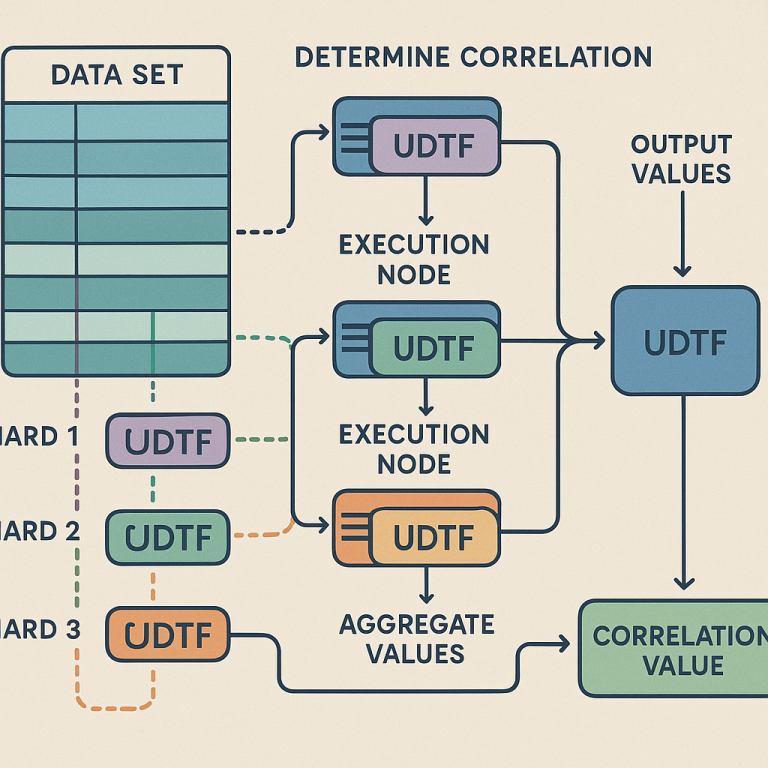
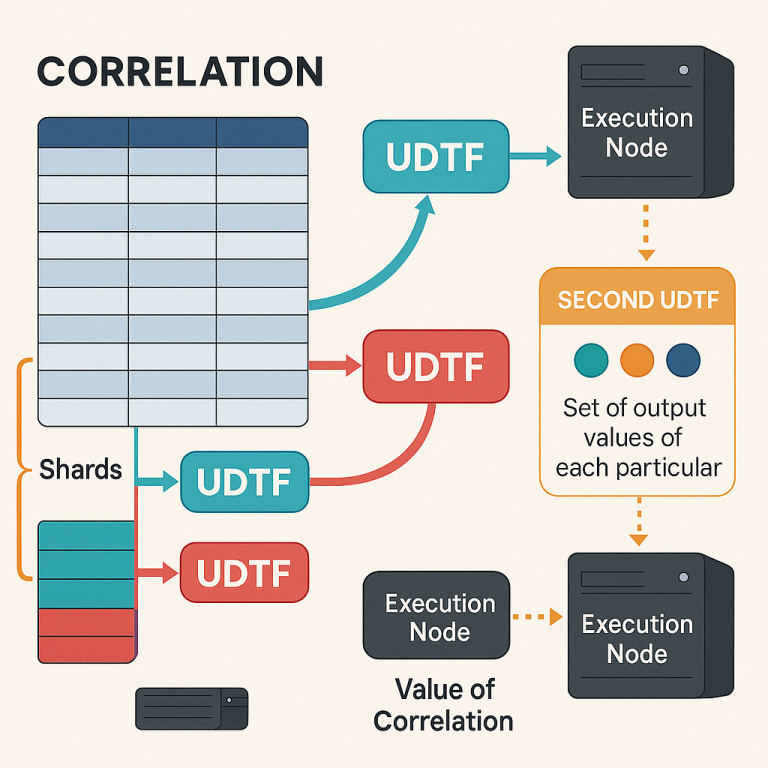
Next, the system breaks the data into “shards.” Each shard is just a chunk of rows from the table. The number of shards matches the number of execution nodes available, so the work can be spread out evenly.
For each shard, the system creates a user defined table function (UDTF). This UDTF is programmed to take its chunk of data, turn it into vectors, and run the needed dot products and sums for the correlation formula. Each UDTF is sent to a different execution node, where it works in parallel with the others.
As each node finishes, it sends back its results. The system then uses a second UDTF to gather all these results together and do the final math. This step is called “aggregation.” The final answer—the correlation matrix or values—is then returned to you.
What’s special here is how the system:
– Figures out the best way to split the work (sharding) based on the size of the data and the number of nodes.
– Uses UDTFs to run vector math right inside the database, not outside it.
– Runs everything in parallel, making it much faster.
– Handles all combinations of columns, so you can get a full correlation matrix, not just one pair at a time.
– Stores the results so you can use them later for feature selection or other analysis.
The system also uses advanced tricks to avoid problems like memory overload or slowdowns. For example, it can count how many rows are in the table with a simple query, and it can adjust the number of nodes based on what’s available.
If a job gets too big for one node, it automatically spreads it out more. If a node fails, another picks up the slack, since nodes don’t keep special state information. This makes the whole system very robust and flexible.
Under the hood, the math is also optimized. The system uses a style called “Einstein notation,” which makes writing out and running the vector math much simpler and less error-prone. By chaining dot products together, it reduces the total number of calculations needed. For a table with n columns, instead of needing n squared steps, it brings it down to just n steps for most of the work. That’s a huge speedup.
Let’s look at a simple example. Suppose you have a table with 1,000 rows and want to use 10 execution nodes. The system splits the table into 10 shards of 100 rows each. Each node gets a UDTF with its shard, computes its vector math, and returns the result. Then the second UDTF gathers everything and gives you the final answer.
The system can also handle more advanced needs. If you want to remove features (columns) that are highly correlated, it can store the correlation results and use them later to guide feature selection.
Because all this happens inside the database, you don’t need to move data around or write many custom scripts. This saves time, money, and reduces errors.
Other tools can’t do this as well. They might be limited to single computers, slow for big jobs, or require you to copy data out of the database. The new approach is more scalable, efficient, and practical for today’s cloud data world.
Conclusion
The invention described here is a leap forward for cloud data analysis. By using distributed in-database vectorized operations with user defined table functions, it lets you quickly find connections in even the biggest, widest tables. You don’t need extra tools or big memory machines. You don’t have to worry about slow jobs or data movement. The secret is splitting the job into shards, running parallel vector math with UDTFs, and smartly gathering the results. This method is flexible, robust, and ready for the future of data. If you work with large datasets and need fast, accurate correlation analysis, this is a game changer.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217343.

