DETERMINISTICALLY DEFINED, DIFFERENTIABLE, NEUROMORPHICALLY-INFORMED I/O-MAPPED NEURAL NETWORK
Invented by Denis; Andrew, Wills, JR.; Harry Howard, Seer Global, Inc.
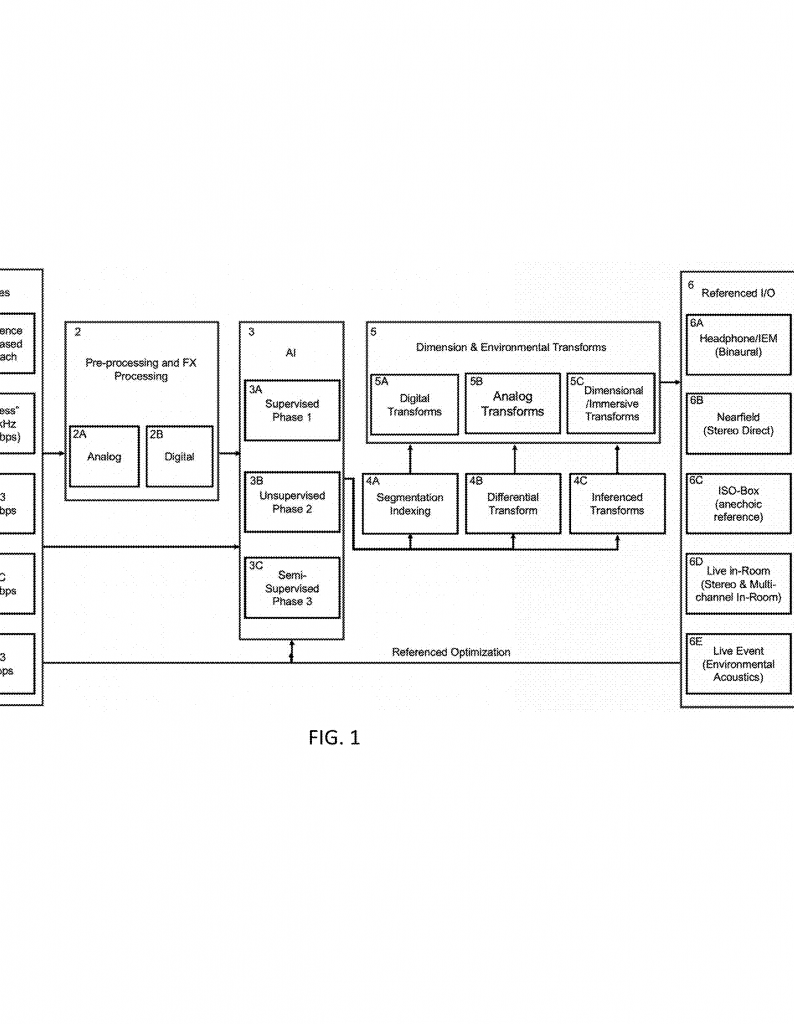
Technology moves fast, but every so often, a new idea comes along that feels like a leap, not a step. The neuromorphic field-defined neural network, as described in the patent application above, is one of those leaps. Let’s break down what this system is, why it matters, and how it could reshape not just artificial intelligence, but also how we hear and experience sound. We’ll keep things simple and clear, so anyone curious about the future of AI and audio can follow along.
Background and Market Context
For as long as we’ve had digital audio, engineers and musicians have tried to reach for one thing: sound that’s as close to real as possible. At the same time, computer scientists have been working on smarter, faster, and more efficient neural networks. These two worlds—audio and AI—are coming together in ways that are changing everything from music production and film to healthcare and smart devices.
Until now, digital sound and machine learning have both been shaped by the limits of old ideas. Audio was often cut down or squashed into formats that fit past technology, like CDs or MP3s. These formats left out much of the detail and life that’s in real music or speech. Neural networks, too, have used layer upon layer of hidden connections—think of them like tangled webs—that take a lot of power and time to train, and are tough to understand or adapt.
Why does this matter today? Because people expect more. We want music that sounds just like the live show, calls that are crystal clear, and AI that can learn new things quickly without burning through huge amounts of energy. Streaming services, smart speakers, hearing aids, and even cars now depend on both high-quality sound and fast, reliable AI. The market is hungry for solutions that go beyond the old limits.
This is where the neuromorphic field-defined neural network comes in. By blending ideas from brain science, physics, and AI, this new system aims to deliver sound that is not only richer and more lifelike, but also easier and cheaper to process. It’s a shift from the old ways, offering a path to smarter machines and better experiences for everyone who listens.
Scientific Rationale and Prior Art
To really understand what makes this invention special, it helps to know what came before. Neural networks—those computer systems inspired by the brain—have been around for decades. They usually work by passing information through layers of “neurons,” each adjusting its settings (or “weights”) as it learns. But all those layers can make things slow, hard to train, and opaque—meaning it’s tough to see what’s happening inside.
Researchers have tried many ways to improve this, like special types of networks for images (CNNs), sound (RNNs), or even graphs (GNNs). Some recent work used ideas from physics, especially partial differential equations (PDEs), to model how data flows and changes over time and space. For example, reaction-diffusion equations from nature have been used to smooth out images or help networks learn patterns that change with time, like weather or speech.
There have also been big efforts in audio enhancement and restoration. Traditional systems used filters or simple rules to clean up sound, but more recent tools rely on AI—like GANs (Generative Adversarial Networks) and transformers—to boost clarity, remove noise, or even fill in missing pieces. Some patents and papers have focused on making these systems faster or more precise, but many still run into the same problems: they need lots of training, lots of data, and lots of power.
What sets the new system apart is how it puts PDEs at the heart of the neural network—not just as a way to process data, but as the main structure connecting inputs and outputs. It also borrows from biology, using different types of nodes (like excitatory, inhibitory, and modulatory) to mimic the complexity and adaptability of real brains. Instead of building ever-deeper networks, this approach uses a single, continuous “field”—imagine a flexible, living map—where signals ripple and interact, shaped by carefully chosen equations and boundaries.
This means the system can handle both simple and complex data, adapt to new tasks, and deliver results much faster and more efficiently than old-school deep learning. It also opens the door to more interpretable AI, since the equations and parameters are easier to understand and tweak. Prior art laid the groundwork, but none combined all these elements into a unified, field-driven neural network that can learn, adapt, and create audio (and other data) at this level.
Invention Description and Key Innovations
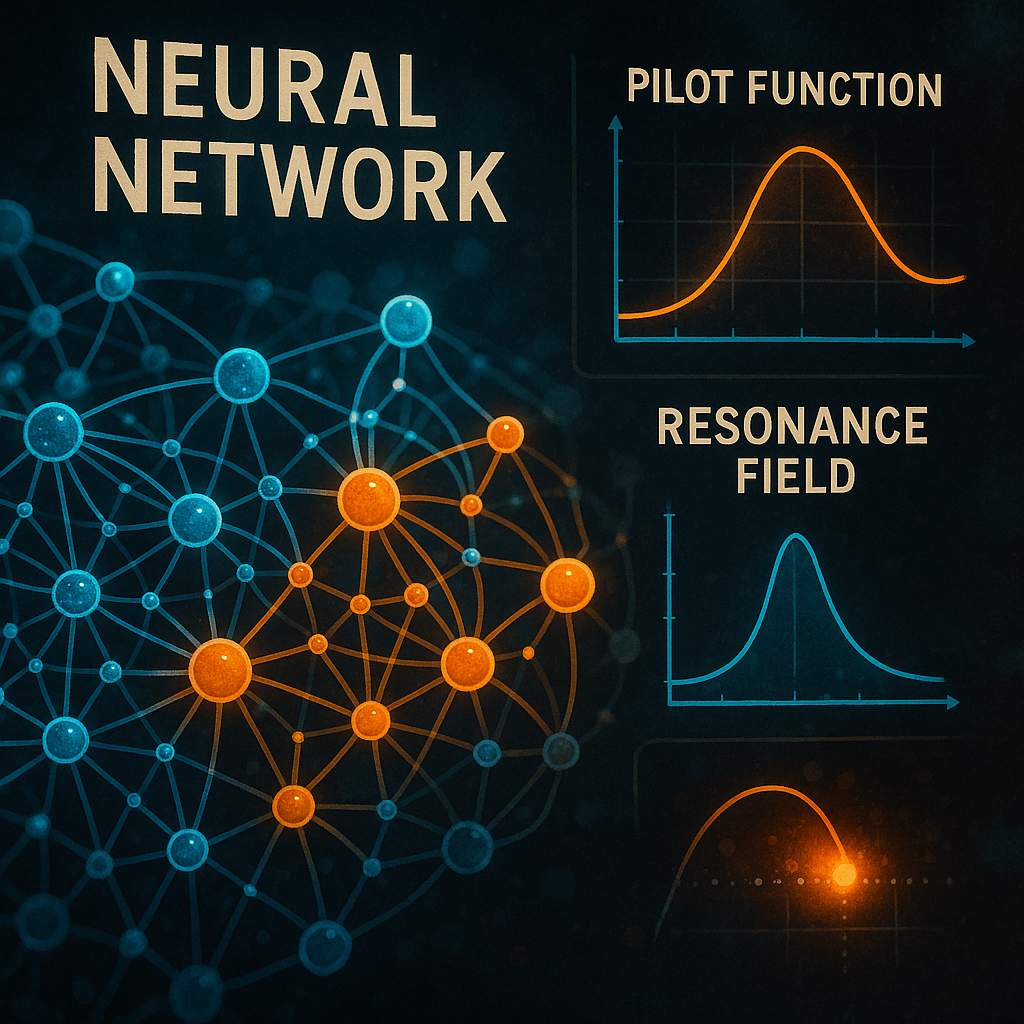
The core of this invention is a new kind of neural network architecture, built around what’s called a neuromorphic field. Let’s break that down in plain English.
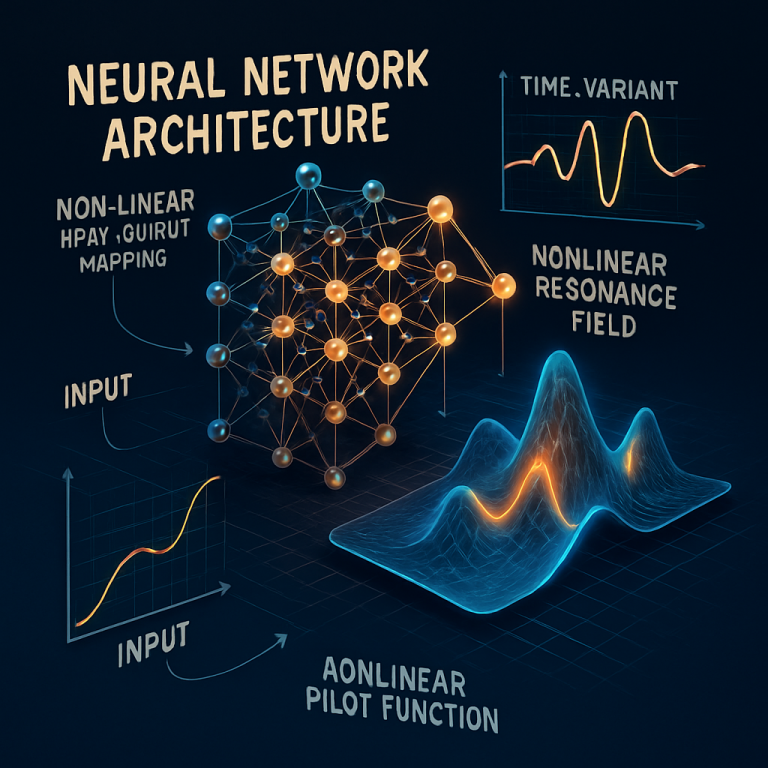
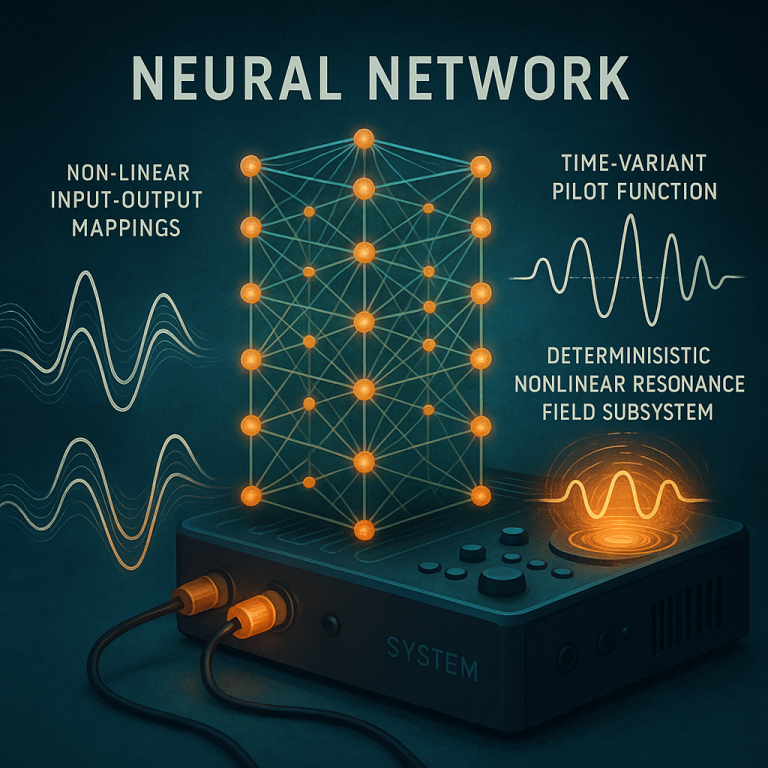
Think of the neuromorphic field as a big, flexible sheet stretched across a space—like a drum skin or a pond. When you drop something (an input signal) onto it, ripples spread out, interact, and eventually settle down. In this system, the “ripples” are patterns of artificial neurons, each governed by partial differential equations (PDEs) that describe how signals move, change, and combine over time and space.
Instead of stacking up many layers, the system uses this field to connect the input layer (where raw data comes in) to the output layer (where results come out). The field itself is made up of many types of nodes:
- Excitatory Nodes: These amplify signals, helping patterns spread.
- Inhibitory Nodes: These dampen or filter signals, preventing chaos.
- Modulatory Nodes: These adjust how strong or weak connections are, much like learning in the brain.
- Oscillatory and Adaptive Nodes: These create rhythms or adapt to changes over time.
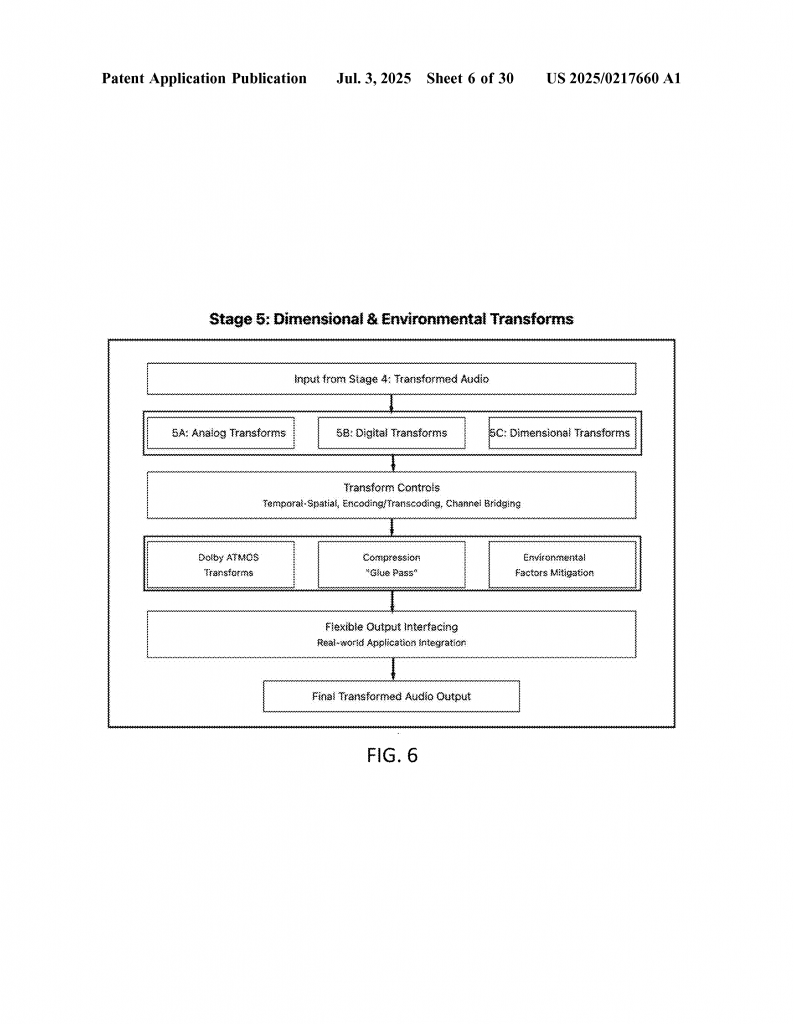
What’s really clever is how the system uses PDEs—especially reaction-diffusion equations—to make sure the field evolves in a stable, predictable way. The field has boundaries (like the edge of a pond), which can be set to different styles: wrapping around, reflecting waves, or letting signals fade away. This keeps everything under control, so the network doesn’t spin out of control or get stuck.
The magic happens in the mapping function that connects input to output. This function is adjustable, with hyperparameters that can be tuned for complexity, time scale, or pattern weight. Training the network works by injecting input signals, letting the field evolve (solving the PDEs over time), sampling the field at key points, and then adjusting the mapping function to minimize error—all while keeping the field itself stable and efficient.
This setup brings huge benefits:
- Efficiency: No need for endless hidden layers; most of the heavy lifting is done by the field and the mapping function, which are much easier to train.
- Adaptability: The field can handle just about any kind of input—audio, images, time sequences, even signals from the body or light.
- Interpretability: The use of explicit equations and boundaries makes it easier to see what’s happening inside, and to fix or improve things if needed.
- Scalability: Because the field is continuous and flexible, it can grow to handle big, complex problems without a big hit to speed or power use.
In audio applications, this means the system can record, restore, and enhance sound with detail and clarity beyond what current systems can achieve—even reaching or exceeding what’s on the original master tapes. It can clean up noise, fix phase and timing issues, and adapt to any output format or device, from headphones and cars to theaters and smart speakers.
The invention also supports new kinds of AI training, where the “ground truth” is not just what’s easy to measure, but the full range of what humans can hear or perceive—including subtle details often lost in the past. This opens up new possibilities for personalized sound, immersive experiences, and smarter, more energy-efficient AI across many fields.
Under the hood, the system uses a PDE Solver to keep the field evolving smoothly, and a Training Module that uses smart regularization, dot-product attenuation, and gating to avoid instability. It can be built in software, but also supports analog, photonic, or even hybrid hardware—making it future-proof for whatever comes next in AI and audio tech.
Conclusion
The neuromorphic field-defined neural network marks a new chapter in both artificial intelligence and audio technology. By replacing slow, tangled layers with a living, adaptable field shaped by the same kinds of math that describe real-world waves and patterns, this system promises faster, smarter, and more lifelike results. It doesn’t just tweak the old models—it changes the game, opening the door to sound and AI that are more real, more personal, and more in tune with how we experience the world.
For anyone building the next generation of audio products, smart devices, or AI-driven systems, this is a development worth watching closely. The future of listening, learning, and interacting may well be shaped by the ripples of this field-driven approach.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217660.

