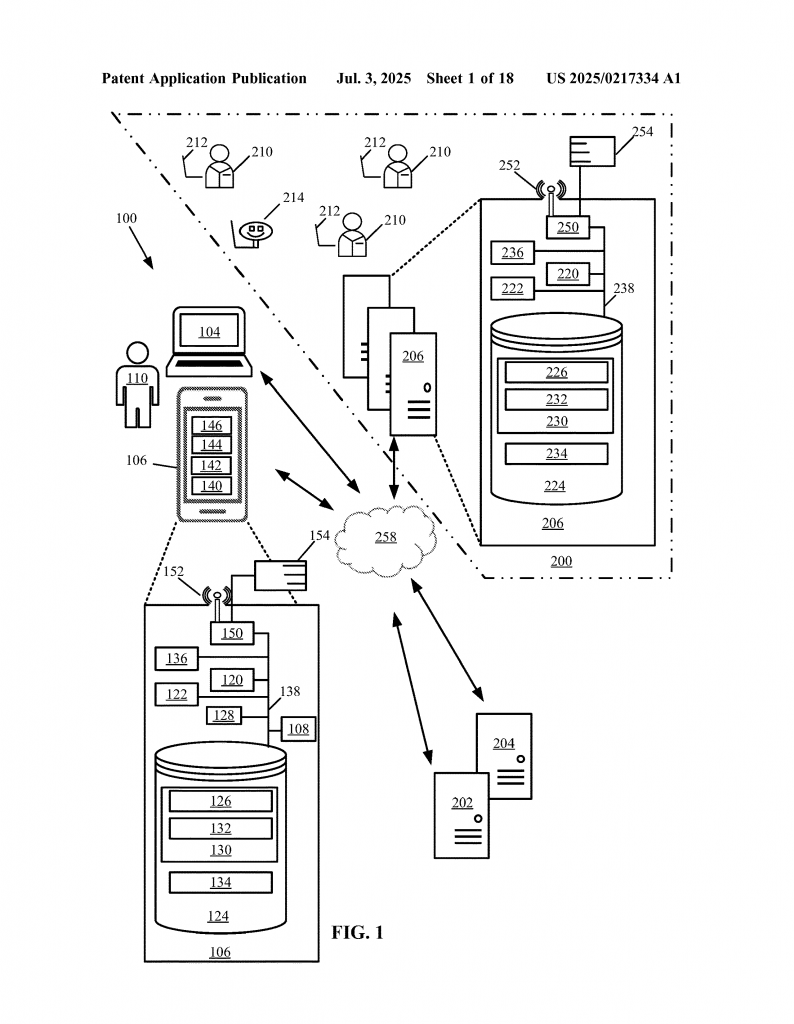
DATABASE AND DATA STRUCTURE MANAGEMENT SYSTEMS

Invented by Khan; Tufail Ahmed, Goswami; Pranjal, Hu; Di, Wei; Changyong, Truist Bank
Today, keeping data clean and organized is more important than ever. Let’s look closely at a new patent application that shows how computers can help people take care of their data, making it more reliable and easier to use. We will walk through the market need, the science behind the technology, and what makes this invention stand out.

Background and Market Context
Data is everywhere. Your school, the doctor’s office, banks, and even your favorite games all use data to keep things running. But as organizations grow and collect more information, problems start to pop up. The same data might be saved in many places, which wastes money and can cause mistakes. Imagine if your school kept three different lists of students, all slightly different—some with missing names, others with extra information, or just plain wrong. This makes it hard to know what’s true.
For businesses, these problems get even bigger. Companies spend a lot of money to store data. If data is not correct, it can lead to bad decisions, lost money, or even broken laws if private information gets out. And with more data coming in every day, it’s almost impossible for people to check everything by hand. That’s why there’s a big push to use computers to help manage data better. Computers can work quickly, spot patterns people might miss, and help keep everything neat and tidy.
But it’s not just about storing data. Companies need to be sure their data is clean (no mistakes), safe (private stuff is protected), and up to date. Sometimes, rules and laws require this. For example, banks and hospitals have strict requirements to keep data private and accurate. If they mess up, they can get in trouble or lose trust from their customers. This is why tools that help with data quality are in high demand.
Because of these needs, the market for data management and quality tools is growing fast. Companies want systems that can find and fix problems before they cause trouble. They also want these systems to be smart, learning from past mistakes, and able to handle lots of different types of information—like lists, tables, numbers, and even words. That’s where the invention in this patent application comes in. It’s designed to help businesses keep their data organized, clean, and safe, all while saving time and money.

Scientific Rationale and Prior Art
To understand why this invention matters, let’s look at how people have tried to solve these problems before. Usually, data quality has been managed by setting simple rules. For example, a rule might say, “No empty boxes allowed in the list of emails,” or “Each person must have a unique ID.” These rules are helpful, but setting them up and checking them takes a lot of work—especially as the amount of data grows.
Older systems often require someone to write down all the rules, check each piece of data, and fix any problems by hand. This is slow and easy to mess up. Plus, if new types of data come in, the rules might not fit anymore. For example, maybe a new kind of phone number is added, or a new field is required. The old system won’t know what to do unless someone updates it.
Some newer tools use simple computer programs to help. They can look for obvious problems—like empty spots, wrong types of information (letters where numbers should be), or duplicates. Basic artificial intelligence (AI) has also been used, but these systems are usually limited. They might learn what looks “normal” in a list, but they don’t always know the rules for different types of data. They might also miss new problems or fail to spot tricky mistakes.
Another big challenge with older systems is that they don’t always understand the meaning, or “semantics,” of the data. For example, if a column in a table is called “SSN,” the system might not know that stands for “Social Security Number,” which is private and needs special protection. Or, if a column is called “ID” in one table and “Identifier” in another, the system might not realize they mean the same thing. This can lead to errors or even data leaks.
To fix this, some systems have tried using machine learning—letting computers look for patterns and guess what the data means. These systems use models like neural networks, which work a bit like the human brain. They look at lots of examples and try to spot similarities and differences. Over time, they can get good at guessing what kind of data they are looking at, or spotting when something looks odd.
But even with these advances, most tools still need a lot of help from humans. Someone has to set up the rules, check the computer’s work, and fix mistakes. If the system gets it wrong, it might throw away good data, or keep bad data. And because data comes in many shapes and sizes, it’s hard for one system to handle everything.
The invention in this patent application builds on these earlier ideas but goes much further. It brings together rule-based checks, machine learning, and real-time feedback in a single system. It learns from the data itself, spots common patterns, recommends new rules, and even asks for feedback when it’s not sure. This is a big step beyond what older systems can do.
Invention Description and Key Innovations
Now, let’s see what makes this new system so special. Picture a super-smart helper that watches over your data, checking it as new pieces come in and making sure everything stays clean and safe. Here’s how it works, in simple terms:
First, the system looks at your data, searching for patterns and common problems. It checks for things like:
- Timeliness: Is the data up to date?
- Accuracy: Does the information look right?
- Uniqueness: Are there any repeats?
- Completeness: Are any blanks or missing spots?
- Validity: Does the data fit the rules (like numbers in number fields)?
- Consistency: Are things the same across different places?
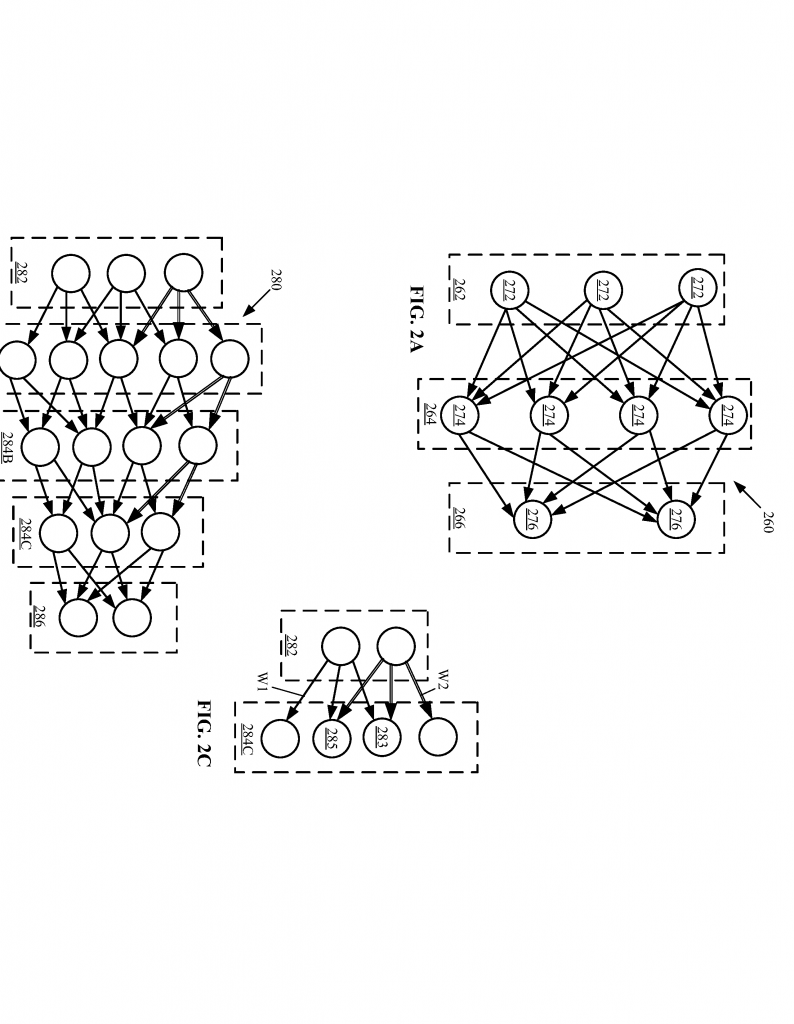
Instead of needing a person to set all the rules, the system uses machine learning to spot common patterns. For example, if a column always has email addresses, the system learns to expect that—and will notice if something doesn’t fit. If it sees a pattern, it creates a “rule.” For example, “This field should always be filled in,” or “No duplicates allowed here.”
But the system doesn’t stop there. It gives each rule a confidence score—a number that shows how sure it is that the rule is correct. If the score is high, the system can ask a person to approve the rule. If the person agrees, the system will start using that rule to check new data. If the score is low, it waits and does not use the rule unless it gets more evidence.
When new data comes in, the system automatically checks it against the rules. If the data matches, it gets added to the main list. If not, it is set aside or flagged for review. This keeps mistakes out before they can cause problems.
The system is also smart about different types of data. It can tell if a column is for emails, addresses, phone numbers, or special numbers like Social Security Numbers. It uses regular expressions (simple patterns) and machine learning models to figure out what kind of data is in each column and field. If it finds something that doesn’t fit—like a phone number in an email column—it can flag the problem right away.
Another cool feature is the way the system checks for duplicates and data types. If it finds two “John Smiths” with the same ID, it can warn you. If it finds a number in a column that should only have words, it can suggest a fix or create a new rule. It can also spot relationships between different pieces of data, making sure everything lines up the way it should.
The system uses statistics too. For example, it can look at the average and standard deviation (a measure of how spread out the data is) to spot values that don’t fit. This helps catch mistakes that might not be obvious, like an age of “300” in a list of people.
One big advantage of this invention is its interactive portal—a simple, easy-to-use screen where people can see what rules the system has found, check its suggestions, and give feedback. This means people stay in control, but don’t have to do all the heavy lifting themselves.
When the system is not sure about a rule, it asks for help. For example, if it thinks a column should never be blank, but isn’t completely sure, it will ask a person to confirm before it starts blocking new data. This makes the system safer and more flexible than older tools.
Finally, the system keeps learning as more data comes in. It remembers user choices and gets better over time. If a company often deals with certain types of data, the system learns to spot problems faster and suggest better rules. This saves time, reduces mistakes, and helps keep data clean and reliable.
Conclusion
This patent application shows a big step forward in how we manage and protect data. By combining smart computer models with easy-to-use tools, it helps people keep their information clean, safe, and useful with less effort. Companies can save money, avoid mistakes, and build trust by using systems like this one. As more data comes in every day, tools like these will become even more important for everyone—from small businesses to giant organizations. Clean data means better decisions, and that’s good for all of us.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217334.

