DATABASE AND DATA STRUCTURE MANAGEMENT SYSTEMS

Invented by Khan; Tufail Ahmed, Goswami; Pranjal, Hu; Di, Wei; Changyong, Truist Bank

Data is everywhere. But not all data is good data. In many businesses, simply having a lot of information is not enough—you need to trust it. In this article, we’ll break down a new patent-pending system that uses smart computers to help companies keep their data clean, correct, and ready to use. If you want to understand how modern technology can help manage big piles of information, this guide is for you.
Background and Market Context
Today, businesses and groups store huge amounts of data. This can be customer details, sales numbers, addresses, or even social security numbers. All this information is used to make choices, run reports, and keep things running smoothly. Some businesses store their data on their own computers, while others use cloud services. But no matter where the data lives, there are big challenges.
First, storing lots of data costs money. Every gigabyte you save in a database or with a cloud company is another expense. It’s even more expensive when the same data is kept in more than one place. This happens all the time in big companies, where different teams make their own copies of the same files. Not only does this waste money, but it also makes it hard to know which copy is right or up to date.
When information is copied or changed in different ways, it can become messy. People may work with old records or incomplete lists. If team A updates a file, but team B uses an older copy, their reports will not match. Sometimes, mistakes or duplicates in the data can lead to wrong decisions that cost the company money or even lead to legal problems.
There are also rules about how certain kinds of information must be handled. For example, if a company keeps personal details like social security numbers or credit card info, the law says they must protect it. If a business does not spot and fix problems in this kind of data, it can be fined or lose the trust of its customers.
Because of these issues, many companies are looking for better ways to keep their data correct, complete, and safe. But checking every file by hand takes too long. That’s why businesses are turning to smart computer systems—using artificial intelligence (AI) and machine learning—to help them keep an eye on their data and fix problems automatically.
This new patent application introduces a system that does just that. It not only checks the data for problems, but it also learns from past mistakes and helps users set rules to keep everything clean and useful. It’s like having a smart helper that watches over your data every day and makes sure it is ready to use.
Scientific Rationale and Prior Art
Let’s talk about how computers have tried to keep data clean before, and what makes this new invention stand out.
In the past, most data checking was done by hand. People would look at spreadsheets or run simple scripts to find missing values, odd formats, or duplicates. For example, if a column was supposed to have phone numbers, a program might check if all the entries looked like phone numbers. If not, that row would be flagged.

Later, some software tools started using more advanced methods. These tools could run checks for things like:
- Missing values (nulls)
- Duplicate entries
- Inconsistent formats (like dates in different styles)
- Out-of-range numbers
But these tools had big limits. They usually needed someone to write the rules ahead of time, and they didn’t learn from the data itself. If the data changed, or if new types of mistakes showed up, the rules wouldn’t catch them. They also didn’t handle new data well—if a new file with a different format was added, the system might miss problems.
More recently, AI and machine learning have been used to spot patterns in data. These systems can look at lots of examples and figure out what “good” data looks like. For example, a machine learning model might learn that most emails end with “.com” or “.org,” so if it sees “.cmo” it might flag it as a mistake. They can also spot outliers—values that don’t fit with the rest of the data.
However, even with machine learning, there are challenges. Some systems need lots of labeled training data (where a person has already said what is right and what is wrong). Others are “black boxes” that make decisions but don’t explain why. Users might not trust a system unless they understand how it works.
The new system described in this patent brings together both the old and new ways. It uses smart analysis to look for problems, but it also learns from the patterns in the data itself. It can suggest rules to users, who can approve or reject them. As more data is checked, the system gets better at finding mistakes and suggesting the best way to fix them. It also uses “confidence scores” to tell users how sure it is about each rule.
This approach is different from past systems because:
– It can look at many “dimensions” of data quality, like timeliness (is the data recent?), uniqueness (are there duplicates?), accuracy (is it correct?), completeness (are all fields filled in?), validity (do values match their expected types?), and consistency (do values match across the dataset?).
– It does not need all the rules to be written ahead of time. It can learn from the data and from what users do.
– It helps users with an easy interface, showing them what problems exist and letting them choose which rules to use.
– It can handle new data as it comes in, using the rules it has learned to keep things clean.
– It even tracks which rules work best, over time, and updates its suggestions.
In short, this system is not just a set of static checks. It is a living, learning helper that works with people to keep data in top shape.
Invention Description and Key Innovations
Let’s walk through how this system works, step by step, and see what makes it special.
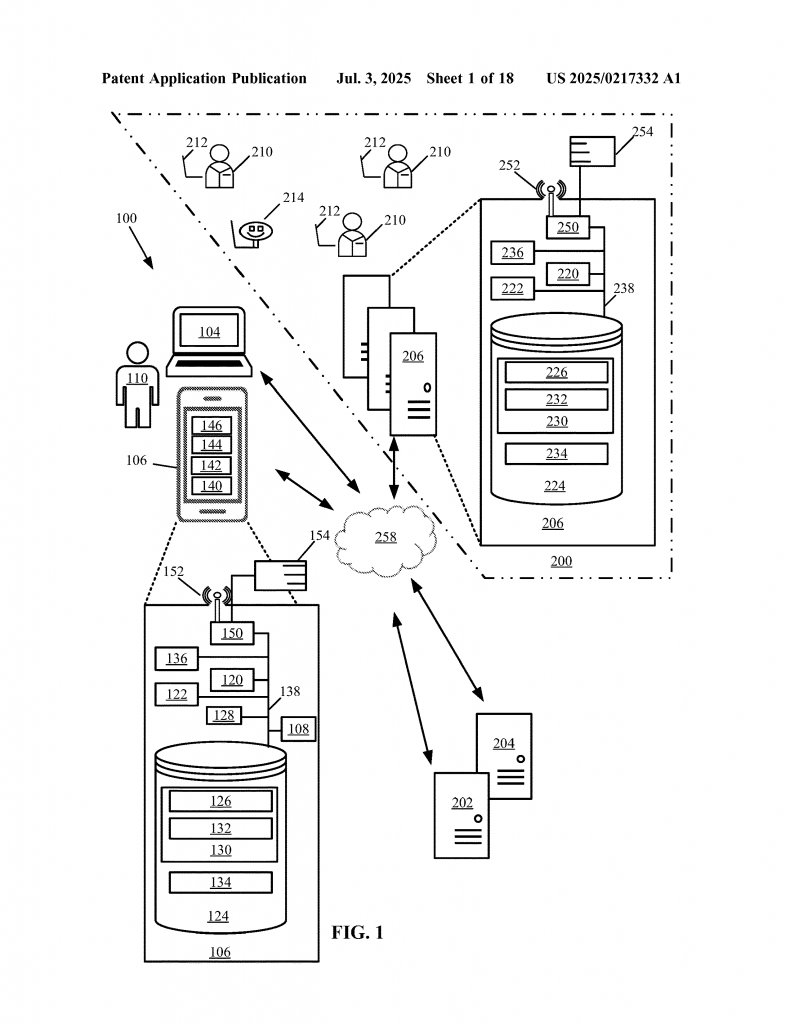
At its core, the system is a smart computer program that connects to your data. It can talk to different storage locations—databases, folders, or cloud storage. Here’s what it does:
1. Accessing the Data
The system starts by getting the dataset. This could be anything from a file with customer names and addresses to a big table with sales numbers.
2. Analyzing for Data Quality
Once it has the data, the system looks at several key features, known as “data quality dimensions.” These include:
- Timeliness: Is the data up to date?
- Uniqueness: Are there repeated entries that shouldn’t be?
- Accuracy: Does the data match known facts or formats?
- Completeness: Are any fields empty or missing?
- Validity: Are values in the right format or type?
- Consistency: Do related fields agree with each other?
It checks each column and field. For example, it will see if a “Date of Birth” field has real dates, if a “Phone Number” field matches expected patterns, or if a “Social Security Number” shows up more than once.
3. Finding Patterns and Problems
The system doesn’t just look for mistakes. It looks for patterns—things that show up often or in a certain way. For instance, it might notice that in most records, the “Email” field is never empty. So, it could suggest a rule that this field should never be left blank.
It also checks if some columns allow “null” (empty) values, and how often that happens. For numbers, it checks if the values are within expected ranges. For text fields, it might use regular expressions to see if the format matches what it should (like ZIP codes or phone numbers).
4. Generating Data Quality Rules
After checking the data, the system generates suggested rules. These might be things like:
- “No empty values allowed in the ‘Email’ column.”
- “No duplicate Social Security Numbers.”
- “All phone numbers must match the pattern (XXX) XXX-XXXX.”
The system does not just make one rule per problem. It can find many possible rules and show them to the user.
5. Rule Confidence Scoring
For each suggested rule, the system gives a “confidence score.” This number tells how likely it is that the rule is a good fit for the data. For example, if 99% of emails are filled in, it might give a high score to the rule “No empty emails.” If only 60% are filled in, the score will be lower.
This score is compared to a “threshold”—a number set by the user or by default. If the score is high enough, the rule can be applied automatically. If not, the user can review it.
6. User Interaction and Approval
The system isn’t bossy. It shows its suggestions to the user in a clear interface—like a dashboard or pop-up. The user can pick which rules to use, make changes, or ignore some rules. This keeps control in human hands.
Once rules are chosen, the system sets them up. From now on, any new data added to the dataset will be checked against these rules. If the new row breaks a rule (like missing an email), it can be rejected or flagged.
7. Handling New Data Automatically
When new data comes in, the system applies the chosen rules. If the rules say “No duplicates,” and a new entry matches an old one, it will not be added. If a value is outside the allowed range, it can be flagged or fixed.
8. Learning and Improving Over Time
As users make choices—accepting or rejecting rules—the system tracks what works. It learns from this feedback. If users always approve a certain rule for a given type of column (like “No nulls” for social security numbers), it will suggest that rule more quickly in the future.
9. Advanced Features
The system does more than basic checks. It can:
– Use machine learning to spot patterns that humans might miss.
– Handle semantic types—understanding that “Customer ID,” “Client Number,” and “Account Number” might all mean the same thing.
– Check relationships between columns, like matching “State” codes with “ZIP” codes for consistency.
– Use statistical rules, like flagging numbers that are far outside the normal range (using mean and standard deviation).
10. Security and Compliance
When the system finds sensitive data (like social security numbers), it can suggest or enforce extra protections—like masking or limiting who can see it. This helps companies follow laws and keep customer trust.
11. Easy Integration
The system can work with many storage types and data formats. It has a user-friendly interface, so even people who are not tech experts can review and manage data quality.
12. Actionable Alerts and Reporting
If the system finds big problems—like lots of missing values or possible duplicates—it can alert users right away, by email or dashboard notification. This helps companies fix issues before they cause harm.
13. Saving Money and Time
By keeping data clean, the system reduces storage costs (no more useless copies) and helps users make better decisions with correct data. It also saves time, since people don’t have to check everything by hand.
14. Scale and Speed
As companies grow and their data gets bigger, this system keeps up. It can handle huge datasets and work in real time, flagging issues as soon as new data arrives.
In summary, this invention is a smart, flexible, and user-friendly way to keep data clean and ready to use. It brings together the best of human judgment and machine intelligence, making sure that data is always reliable, safe, and useful.
Conclusion
Clean data is the foundation of good business. The data quality rule recommendation system described here is a powerful new tool for any company that wants to trust its data. It uses smart analysis and machine learning to spot problems, suggest fixes, and learn over time. It keeps users in control, but takes away the hard and boring parts of data checking. Whether your business is small or large, this kind of system can save money, reduce mistakes, and help you make the best decisions with your information. As data keeps growing in size and importance, tools like this will become the standard for companies that want to lead in their fields.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217332.

