Boosting Cloud Storage Speed: Faster File Access Without Extra Caching for Enterprise Data Systems
Invented by Madan; Nitin, Lewis; Donna Barry, Bhanjois; Bhimsen
Backing up and restoring data is a part of daily life for businesses. But as data grows, the need to store more while spending less gets stronger. Deduplication storage helps by removing extra copies. But when it comes to reading back only parts of files, things can get slow. This article takes you through a new way to make those reads faster, especially when only reading selected parts of files, by creating something called “synthesized sequential extent files.” We’ll explain the background, the science behind it, and how this invention changes the game.
Background and Market Context
Storing data safely is important for every company. Most businesses use backup systems to copy their data to another place. This way, if something goes wrong—like a computer crash or a virus—there’s a copy to restore from. But copying everything over and over eats up storage space and costs money. To solve this, many backup systems use deduplication. Deduplication means the system does not save the same chunk of data twice. If two files are the same, or parts of them are the same, the system saves it only once and keeps a pointer to it for the next time. This saves a lot of space.
But there’s a catch. While deduplication is great for saving space, it can make certain types of data restores slower. In the real world, applications often need to restore just a part of a file, not the whole thing. Think of a giant database where you only need a few rows, or a virtual disk where only small areas have changed. These parts are called extents. Reading just the extents means the backup system has to jump all over the disk to find them. This is slower than reading one big chunk in order.
Most backup systems have something called a “prefetch” or “read-ahead” mechanism. When you start reading a file, the system tries to guess what you will read next and loads it into memory. This way, when you ask for it, it’s already waiting and things go faster. This works well when reading a whole file from start to finish. But when jumping between extents, the prefetch system gets confused. It may load parts you never read, or miss loading the next extent you need. This leads to wasted work and slower restores.
In today’s world, data is growing, and backup windows are shrinking. Businesses want to get their data back quickly, even if they only need small pieces. Cloud systems, virtual machines, and large databases all depend on fast, efficient restores. That’s why there’s a strong need for a better way to handle extent-based reads in deduplication systems.
This new invention steps in to solve this problem. It gives backup systems a way to bundle together the needed extents into one new file—arranged in order—so the prefetch system works its magic, making restores much faster even when only parts of files are needed. This is especially useful for companies using deduplication storage systems like Data Domain, and for clients like DDBoost that interact with them.
Scientific Rationale and Prior Art
The science behind data deduplication is well-known. When data is saved, it’s split into small segments, each with its own unique fingerprint (like a digital label). If a segment has been saved before, the system just points to it instead of saving it again. These fingerprints and their arrangements are stored in something called a Merkle tree. Merkle trees help the system track which pieces make up each file, and let it quickly find or verify data.
When it’s time to restore data, the system looks up the needed fingerprints, finds where they live, and puts the pieces back together. If restoring a whole file, this is mostly a straight line—reading the data in order. Prefetch systems help here by loading data ahead of time. But for extent-based reads, the system has to jump from spot to spot, with no clear order. Prefetching gets less useful, because it can’t predict where you’ll go next.
Older solutions tried to fix this by making the prefetch system smarter. Some tried to keep a bigger cache, hoping that needed data would already be loaded. Others tried to guess which extents would be read next. But these tricks either cost more memory, slowed down the whole system, or just didn’t work well for random access patterns.
Synthetic backups became another tool. Instead of copying all data for each backup, systems created new full backups by combining previous full backups and only the changed pieces (the “deltas”). This made backups faster and used less space. But when restoring, especially for extents, the system still had to jump around to stitch together the needed parts.
In deduplication storage systems like Data Domain’s DDFS, files are represented by Merkle trees, and the smallest data pieces (segments) are shared across files. The DDBoost protocol helps clients talk to these systems efficiently, handling deduplication on the client side and reducing network traffic. But even with DDBoost, extent-based restores were not as fast as they could be, because of the random read pattern and the limits of traditional prefetching.
Existing patents and systems focused on improving prefetching for sequential reads, or on optimizing deduplication and synthetic backups. None directly tackled the unique issue of making extent-based reads in deduplication systems as fast as sequential reads. There was a gap: a way to gather selected extents into one place, so the prefetch system could work smoothly, without changing the underlying data or overloading the system with extra files.
Invention Description and Key Innovations
This invention brings a fresh approach to the problem. Instead of jumping from extent to extent and suffering slow performance, it creates a new, temporary file that contains just the needed extents, arranged in order. This file can be read from start to finish, making the prefetch system happy and giving a big boost to restore speed.
Here’s how it works in simple terms:
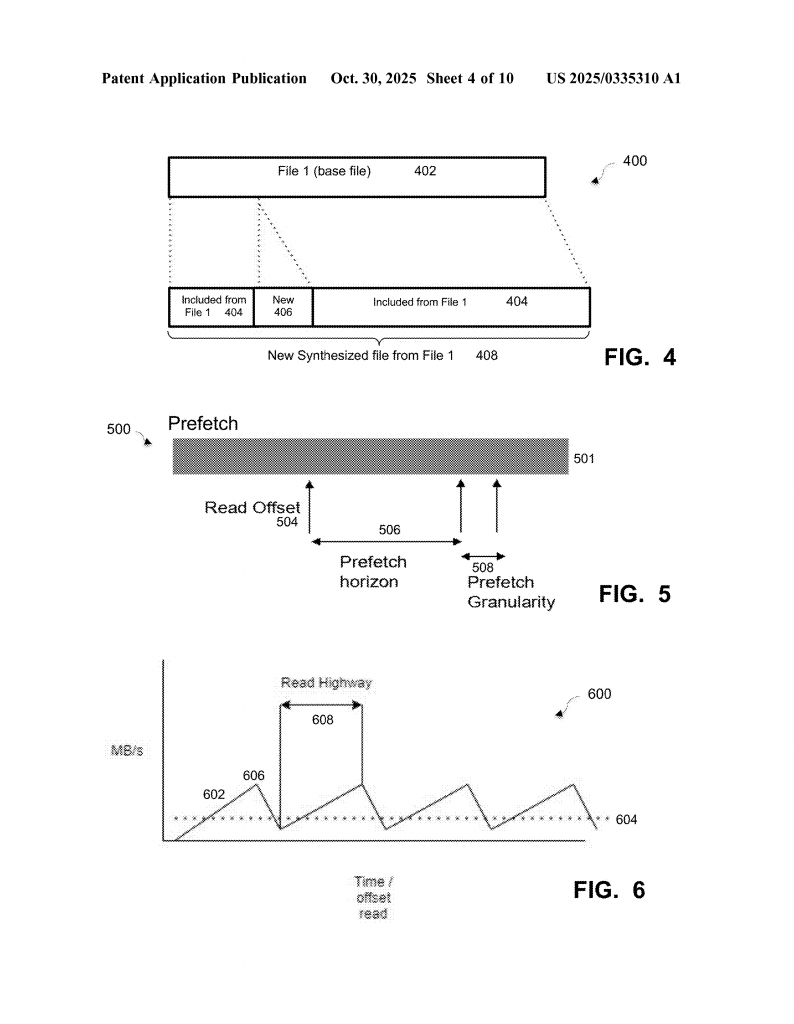
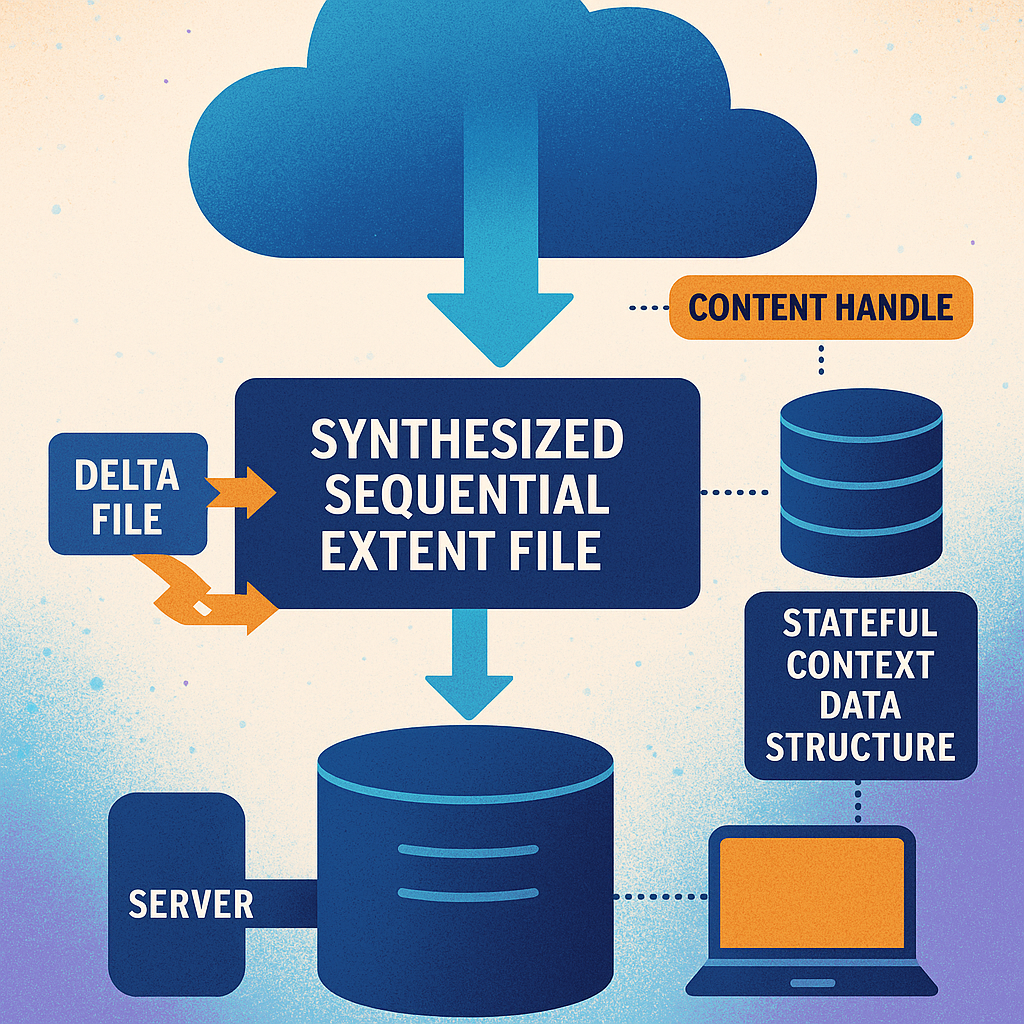
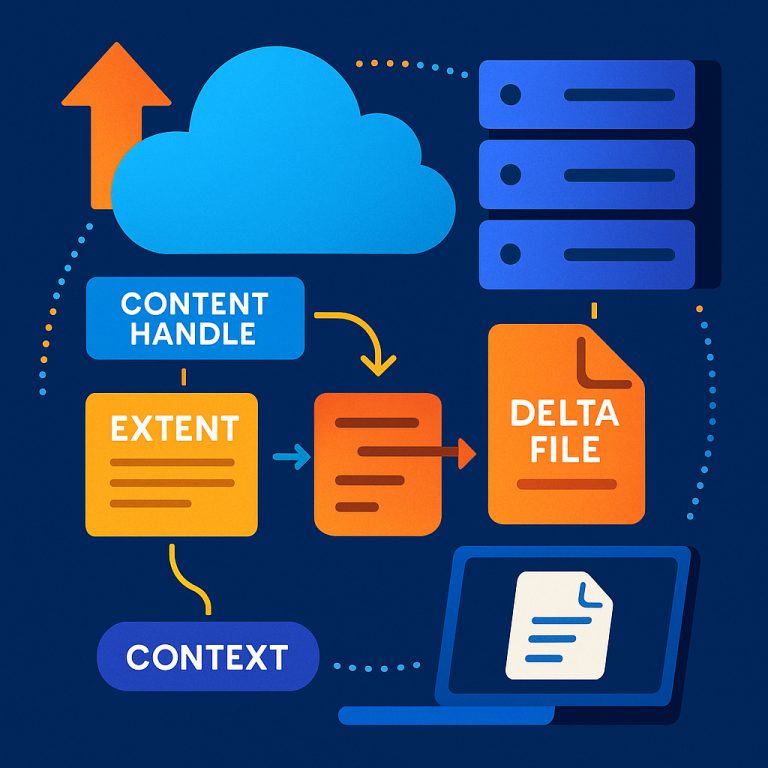
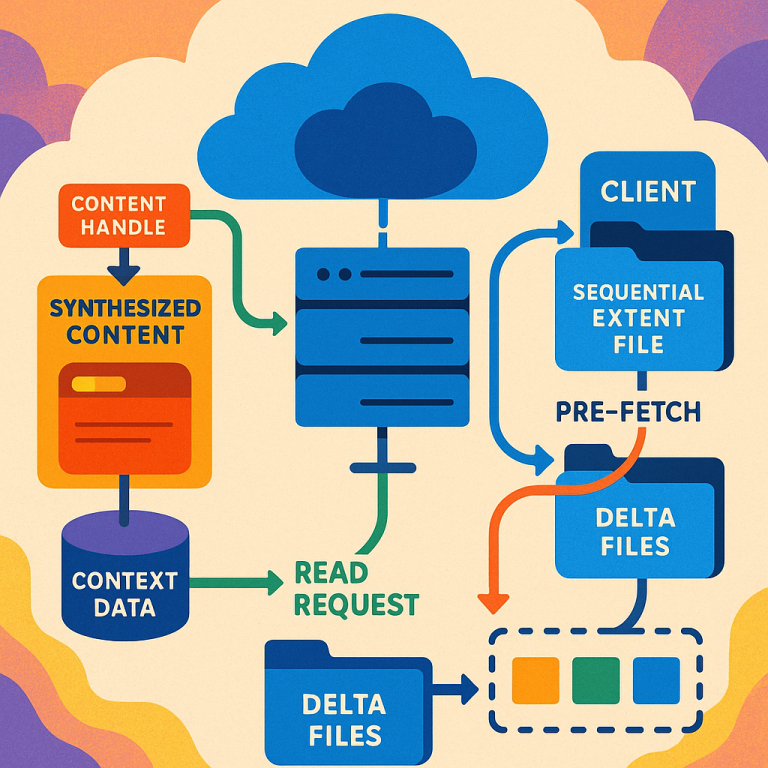
When a client (like a backup software using DDBoost) needs to read certain extents—maybe only the changed parts between two backups—it tells the server (the deduplication storage system) about these extents. The server gathers the data for those extents and creates a new file, called a synthesized sequential extent file. This file is not a regular file; it doesn’t appear in the usual file list, so it doesn’t mess up the storage system’s organization. Instead, it’s managed with a temporary “content handle” and stored in a special context that only the client can see while it’s reading.
The big win is that the extents are now lined up, one after another. When the client reads the new file, it’s just like reading a regular file from start to end. The prefetch system can load data ahead without guessing, and there’s no wasted work. As the client reads, the server sends the data straight from the synthesized file. When done, the temporary handle is destroyed, and there’s nothing left to clean up.
This method brings several key innovations:
1. Synthesized Extent File Creation
The server builds a new file from the needed extents, based on changes (deltas) between different versions of a backup or based on user requests. This file is made up only of the requested data, lined up for easy reading.
2. Inode-less Content Handle
The synthesized file does not use a regular file entry (inode) in the file system. Instead, it’s referenced by a special content handle that lives only for the duration of the operation. This avoids cluttering the file system and keeps everything tidy.
3. Stateful Context for Client Lookup
The server keeps track of the synthesized file in a stateful context, so the client can find and read it during the restore. Once the operation is finished, the context and content handle are destroyed, freeing up resources.
4. Enhanced Prefetch Efficiency
Because the synthesized file is laid out sequentially, the prefetch system can load data ahead efficiently. There are no wasted reads (no prefetches beyond the end of needed data) and no missed reads (the start of each extent is always prefetched). This results in much faster restores for extent-based reads.
5. Application and Use Cases
This approach is especially useful for deduplication storage systems (like Data Domain), clients using DDBoost, virtual disk restores, sparse file restores, and applications that only need to read embedded metadata. It can also be used for patching files on different storage devices, or for pulling together only the changed parts of a backup for fast recovery.
Technically, this solution is flexible. It works by letting the client send a list of offsets and lengths (the extents), and the server gathers the data to create the synthesized file. The client then reads it using a special handle, and when finished, the server cleans everything up. There’s no impact on the file system’s namespace, and no need for extra caching or complicated prefetch logic.
This method can be built into existing backup and restore software, and works well with popular deduplication systems and protocols. It helps businesses restore data faster, save time and money, and keep their systems running smoothly, even as data grows bigger and more complex.
Conclusion
Backing up and restoring only the parts of files you need is a growing challenge as data explodes. Traditional deduplication storage solves the space problem, but can slow down restores for just the parts you want. This new method solves that by gathering the needed extents into a temporary, easy-to-read file, making restores much faster and smoother. It keeps the file system clean, saves resources, and fits right in with modern systems like Data Domain and DDBoost. For businesses, this means faster recoveries, less waiting, and more confidence in their backup systems. As data continues to grow, smart inventions like synthesized sequential extent files will keep everyone moving forward.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250335310.

