BAYESIAN GRAPH-BASED RETRIEVAL-AUGMENTED GENERATION WITH SYNTHETIC FEEDBACK LOOP (BG-RAG-SFL)
Invented by Denis; Andrew, Wills, JR.; Harry Howard, Seer Global, Inc.
Artificial intelligence and machine learning have changed the way we work, communicate, and enjoy media. But as impressive as modern systems are, there is always room for improvement—especially when it comes to making AI smarter, more accurate, and more useful for everyone. Today, let’s dive into a groundbreaking invention that reimagines how AI can be made even better. We’ll explore how combining new retrieval methods, smarter evaluation, and a system for constant self-improvement can set a new standard for AI—especially in how we create, restore, and enjoy audio.
Background and Market Context
Over the past decade, artificial intelligence (AI) has become a staple in our daily lives. From voice assistants to music recommendations and chatbots, AI systems are everywhere. The brains behind many of these systems are Large Language Models (LLMs)—complex programs trained to understand and generate language, answer questions, and even write stories or code. But as useful as these models are, they sometimes make mistakes, give odd answers, or miss important details, especially when dealing with tricky questions or noisy data.
At the same time, how we experience sound—music, podcasts, movies, and even calls—has changed. We now expect crystal clear audio, even when streaming over the internet or listening on tiny devices. But perfect audio isn’t easy to achieve. Every recording, every stream, and even every playback device adds its own noise, distortion, or loss of detail. For years, audio engineers have relied on fixed rules and best guesses to try and fix these problems. But those rules only go so far, and often, something gets lost along the way.
In tech and media, the push is always for higher quality, smarter systems, and more personalized experiences. The market is full of solutions—some focus on making audio sound better, some on making AI answer questions more accurately. But most work in silos, fixing only part of the problem. As AI becomes more central to both communication and media, there is a growing need for systems that can not only answer questions reliably but also enhance the quality of media like audio, adapting in real time and constantly learning from feedback.
This is where the new invention stands out. It brings together innovative methods for retrieving and checking information, a clever way to evaluate and improve answers, and a feedback loop that helps the system learn and get better over time. It also goes beyond just text, applying these tools to audio enhancement—setting a new standard for both digital assistants and media quality.
Scientific Rationale and Prior Art
To understand what makes this invention unique, let’s take a step back and look at how things have worked up until now.
Most modern AI systems use what’s called Retrieval-Augmented Generation (RAG). In simple terms, when you ask a question, the system searches through its memory, finds some relevant information, and then puts that together into an answer. Usually, this search happens in two steps: first, the system grabs chunks of text from a big database, then it asks the language model to use those chunks to write a good answer. This approach is smart, but it has flaws. Sometimes, the system grabs the wrong bits, misses key details, or gets confused when the data is messy or contradictory.
Several solutions have been proposed to fix these problems:
Some systems try to do smarter searches, using fancy ways to measure how close the information is to your question. Others use multiple models—each with its own strengths—to compare answers and pick the best one. There’s even research into using Bayesian methods—a way to update beliefs based on evidence—to judge whether a piece of information is likely to be correct or useful.
But even these advanced systems have their limits. They often depend on the quality of the database, they may not handle conflicting or missing information well, and they rarely check their own answers after the fact. Most don’t have a way to keep learning and improving once they’re deployed.
In the world of audio, past solutions have also relied on rules and assumptions. Engineers build tools to remove noise or boost quality, but these tools are based on fixed ideas about what good audio sounds like. They don’t adapt to new types of audio, new playback devices, or new user preferences. And they certainly don’t learn from feedback in real time.
The prior art includes many patents and papers that have pushed the field forward. Some combine AI with logic engines or run multiple models in parallel. Others generate synthetic data to train better models or use multiple agents to check answers. But none have seamlessly combined graph-based retrieval, Bayesian evaluation, multi-agent feedback, and synthetic learning into a single, constantly improving system. And none have applied these tools in such a tightly integrated way to both text and audio, enabling not just smarter answers but also higher quality media experiences.
Invention Description and Key Innovations
Now, let’s break down what makes this invention truly special—and how it works, in simple terms.
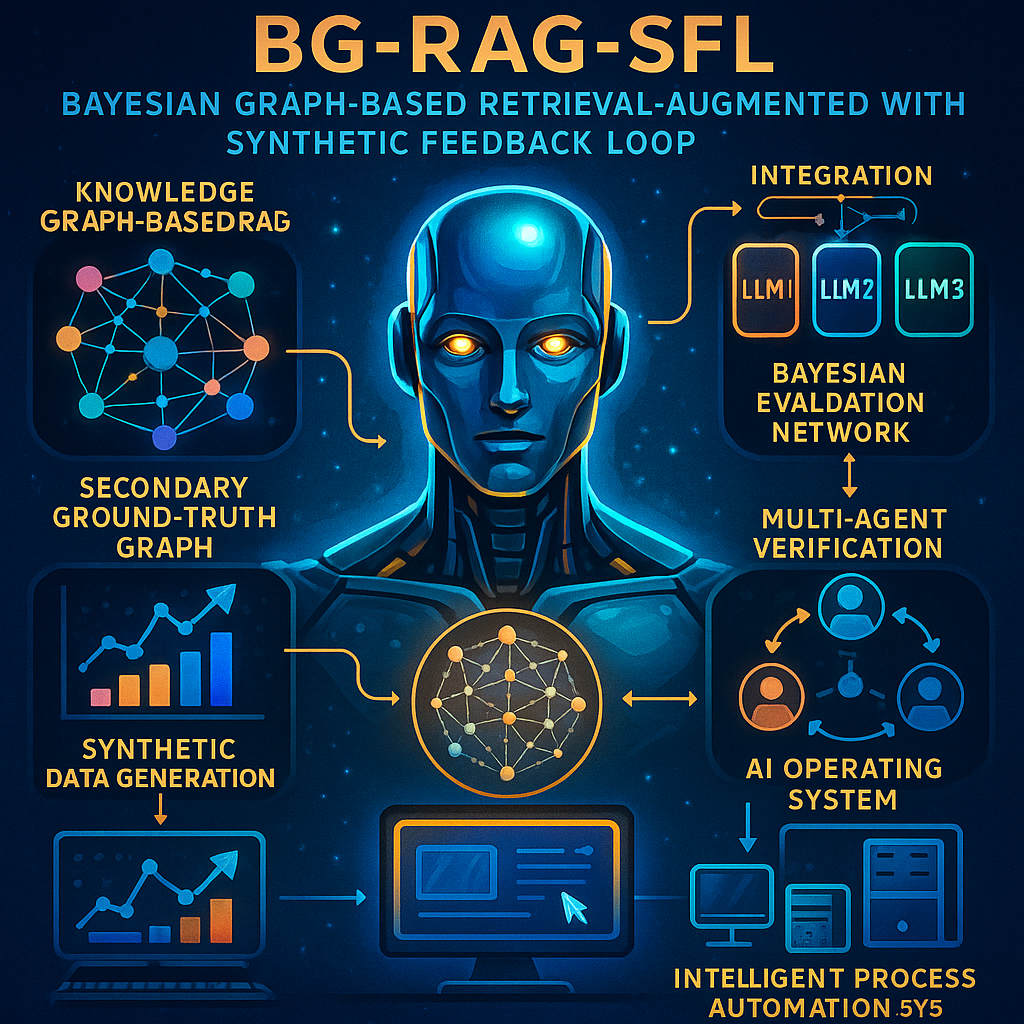
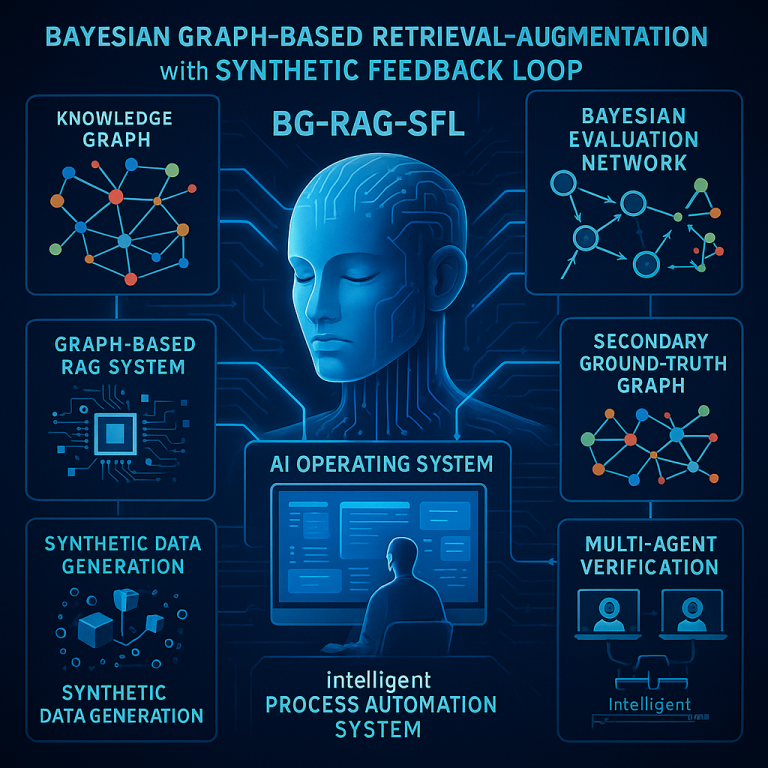
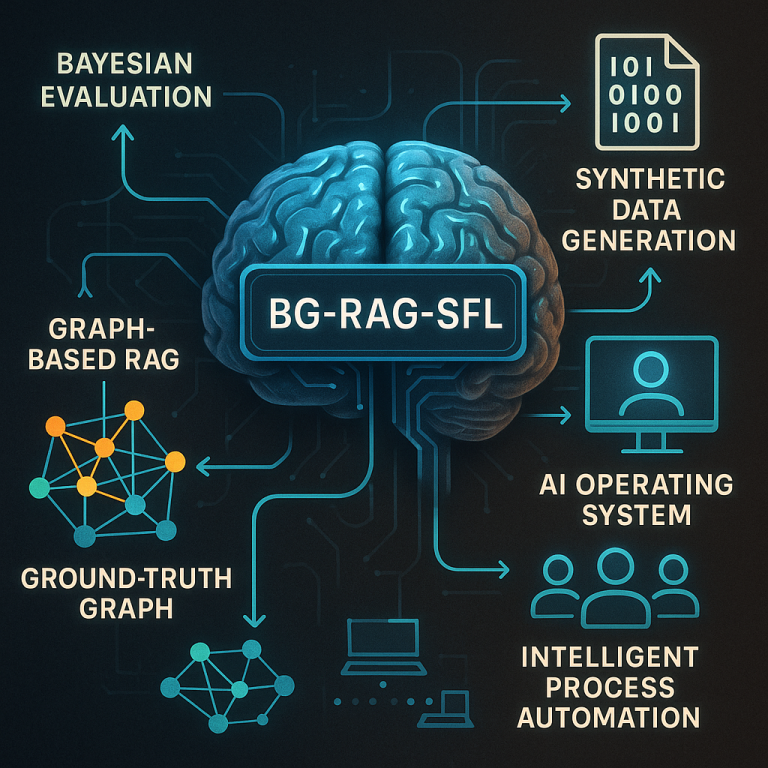
At its heart, this system is called Bayesian Graph-Based Retrieval-Augmented Generation with Synthetic Feedback Loop (BG-RAG-SFL). That’s a mouthful, so let’s explain it step by step.
First, when a user asks a question—whether it’s about a fact, a task, or even how to make audio sound better—the system starts by searching a “knowledge graph.” Think of this as a smart web of facts and relationships, not just a list of documents. This lets the system find connections that would be missed in a simple search. For example, if you ask about a band, the system can find not only their albums but also related genres, influences, and even typical recording techniques.
Once it has gathered the best information, it passes this to one or more large language models (LLMs). These models are the writers—they take the facts and turn them into a clear, helpful answer.
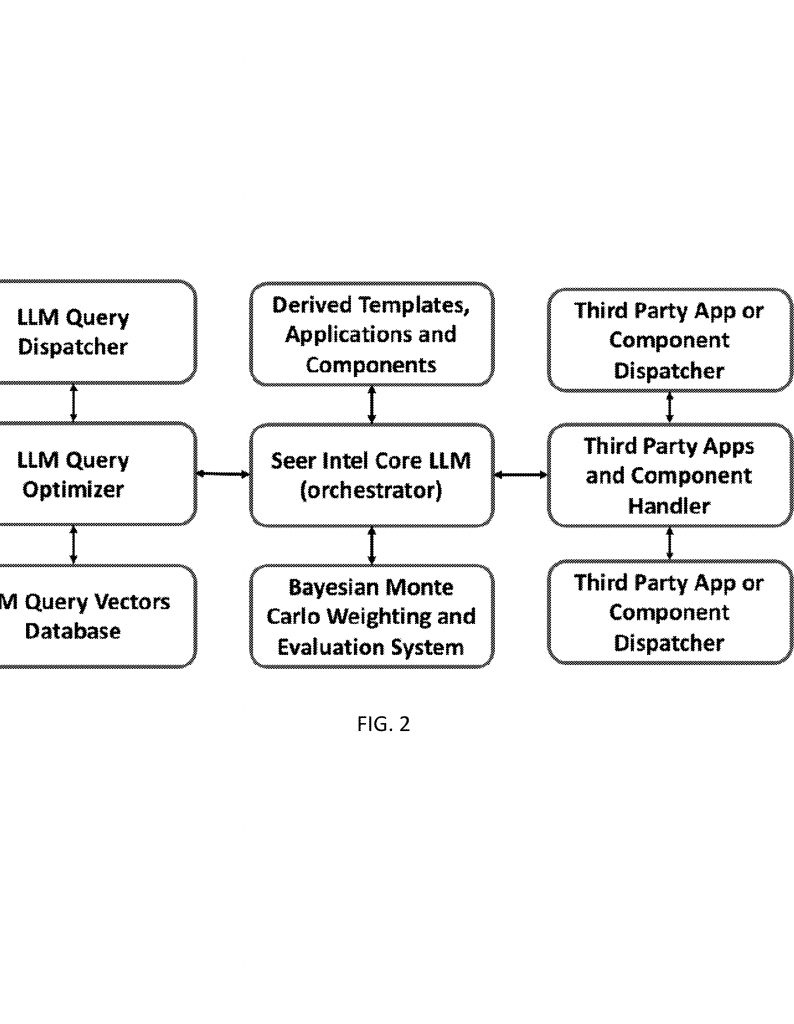
But here’s where it gets clever. Instead of just trusting the answer is good enough, the system runs a Bayesian evaluation. In simple words, it uses probability to judge how likely it is that the answer is correct, clear, and relevant. If the answer isn’t good enough, it doesn’t stop there—it checks again, this time using a “secondary ground truth” graph. This is like a trusted backup set of facts—maybe curated by experts or gathered from reliable sources.
Even then, the system isn’t done. It brings in multiple specialized AI agents—one checks facts, another checks if the answer makes sense, and a third checks if it’s really relevant to the question. If any agent finds a problem, the system tweaks the answer, learns from the feedback, and tries again. Only when the answer meets a set quality threshold does it send the result back to the user.
But the most powerful feature is the feedback loop. Every time the system checks and improves an answer, it creates synthetic data—new examples of good and bad answers, new connections in its knowledge graph, and new ways to update its internal “beliefs.” This synthetic data is then used to retrain the system, making it smarter and more accurate over time. The more it’s used, the better it gets.
This same approach is applied to audio. When enhancing sound, the system uses AI to compare the current audio to a “ground truth” reference—an example of perfect sound, even beyond what’s usually possible with standard recordings. It applies smart transforms, guided by its learning, to recover lost details, correct distortions, and even adapt the audio for different playback devices or environments. It learns from every piece of feedback, constantly raising the bar for what counts as “high quality.”
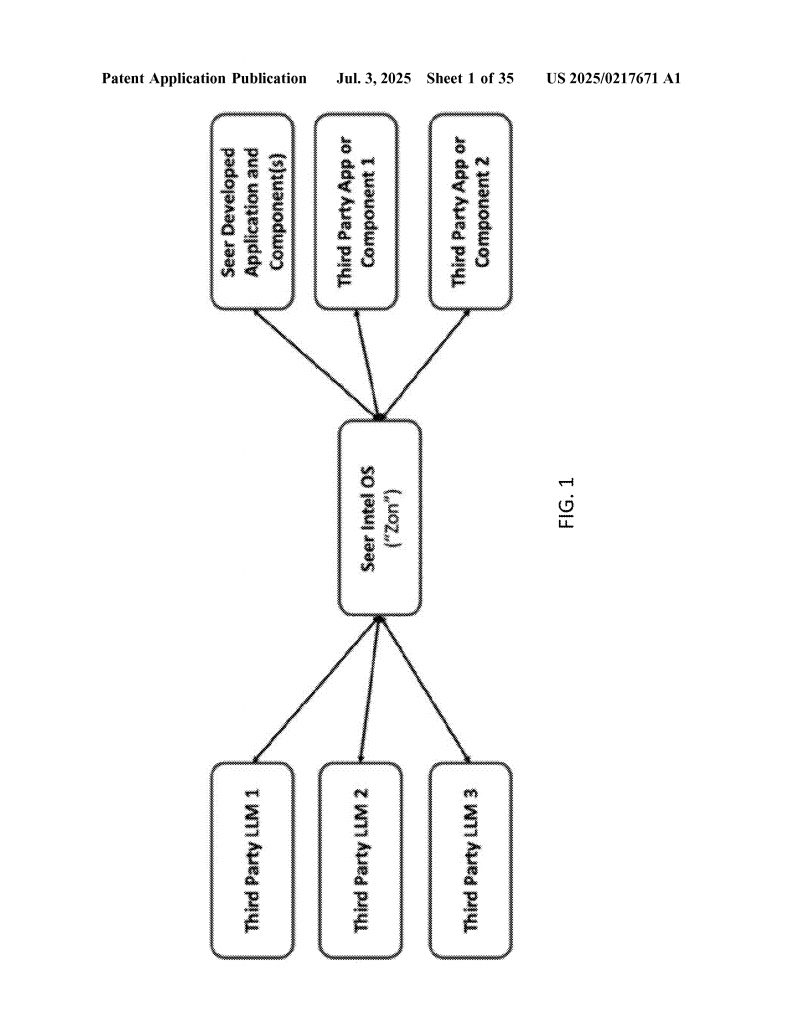
The invention isn’t limited to text or audio. It’s designed as an “AI Operating System” that controls multiple models, handles different types of input (text, voice, images, video), and can even act as a virtual user—reading screens, controlling devices, and automating complex tasks across computers. It includes modules for research, asynchronous task management, result analysis, and seamless integration with other software and APIs.
Some standout innovations include:
– A knowledge graph retrieval system that captures complex relationships, not just keywords.
– Bayesian evaluation to judge answer quality using probabilities, not just fixed rules.
– A secondary, trusted knowledge graph for double-checking answers.
– Multi-agent verification for fact checking, coherence, and relevance.
– Synthetic data generation and feedback looping for continuous self-improvement.
– Modular design, so new models, data sources, or agents can be added easily.
– Full support for multi-modal inputs and outputs, making it future-proof and adaptable.
For users and businesses, the benefits are huge. You get more accurate answers, smarter automation, and higher quality media, all from a system that keeps getting better with use. For audio professionals, it means restoration and enhancement that actually matches how people hear, not just what the old rules say. For AI researchers, it’s a blueprint for systems that don’t just work—they learn, adapt, and redefine what’s possible.
Conclusion
The world of AI and digital media is always moving forward, but true breakthroughs are rare. This invention is one of those rare leaps—a system that combines the best of retrieval, evaluation, multi-agent feedback, and self-improvement, then applies it to both language and audio. By learning from every answer, every correction, and every piece of feedback, it sets a new standard for accuracy, quality, and adaptability in AI.
Whether you care about getting the right answer, enjoying music the way it was meant to sound, or building systems that keep getting smarter, this invention points the way forward. It’s not just about fixing old problems—it’s about setting a new bar for what AI and media can be.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217671.

