Artificial Intelligence For Contextual Keyword Matching
Invented by Selvaraj; Ernest Kirubakaran, Shah; Akshay Rajendra, Kewalramani; Rohit, Golsefid; Samira
Understanding what people really mean when they type or say something online is not easy for computers. The new patent application we are examining today is about making computers much better at this task. It shows a method for using special layers in artificial intelligence to help computers match keywords in context, so that the results are more useful and accurate. Let’s break down this invention and see why it matters, how it builds on what came before, and what exactly is new about it.
Background and Market Context
In the digital world, keywords are everywhere. Businesses use them to target ads, improve search results, and understand what users want. However, just matching words is not enough. The same word can mean different things in different situations. For example, the word “apple” could be about a fruit or about the tech company. If a computer only matches the word “apple” without knowing the context, it may give wrong results. This can be a big problem, especially for companies that want to reach the right audience, or for tools that help people find what they need on the internet.
Right now, many systems still use simple string matching. They look for exact words or phrases and return results based on that. This method is fast, but not very smart. It does not understand what the user really means. As a result, businesses often get a lot of false positives — meaning results that look like a match but are not actually helpful. For example, a company selling software to other companies might want to know when someone is looking for “cloud computing,” but a simple match might confuse this with weather clouds. That’s a wasted opportunity and can cost money and time.
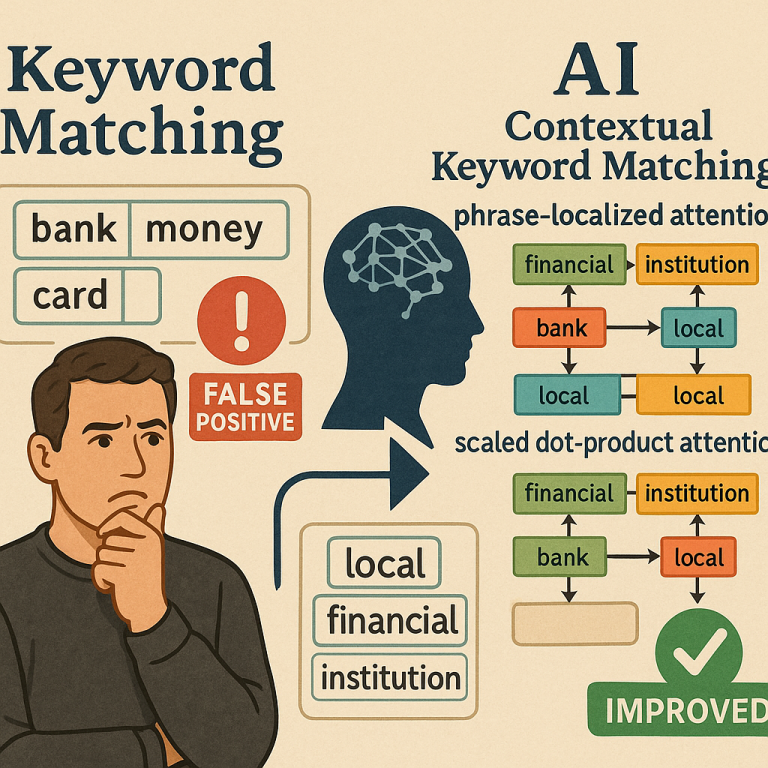
The stakes are high. Digital marketing, online services, and e-commerce all depend on understanding user intent. Getting the context right means reaching the right customers, showing the right ads, and making smarter business decisions. In a world where online data is growing every second, and competition is fierce, this context-aware matching is more important than ever. Companies that can better understand what their users are looking for have a big advantage.
That’s why there is a race to make keyword matching smarter. The market needs tools that do more than just match words. It needs systems that can read between the lines, understand what users mean, and deliver results that make sense for each situation. This is not just a technical challenge; it’s a business imperative for anyone who wants to stay ahead in the digital economy.
Scientific Rationale and Prior Art
To understand what makes this new patent special, we first need to look at how keyword matching has evolved. The earliest methods were just string matches. If the word matched, it was considered relevant. These methods are very basic and do not handle ambiguity at all. For a long time, this was enough because there was not as much data, and user needs were simpler.
As the internet grew, people realized that words can have many meanings. This led to the use of more advanced tools like statistical models, which look at how often words appear together, and machine learning models, which can learn from lots of examples. Still, even these models often struggle with understanding context in a deep way. They might look for words that appear together often, but they do not really “understand” what those words mean in each case.
The rise of deep learning and artificial intelligence brought new hope. Models like transformers became popular. A transformer is a kind of neural network that can look at many words at once and learn how they relate to each other. They use something called “attention” to focus on important words in a sentence. The original transformer model, introduced with the paper “Attention Is All You Need,” changed how computers handle language tasks. It works very well for sentences, but has a problem: it cares a lot about the order of the words. This is not good for keyword arrays, where the order does not matter.
Some researchers tried to fix this by making the transformer “permutation-invariant.” That means the model produces the same result no matter what order the keywords are in. One way to do this was by resetting the position encoding at each keyword, so that the model does not get confused by the order. This helped, but it also created a new problem: the model lost track of the structure inside each keyword. It could not tell, for example, which word came first inside the phrase “cloud computing.”
Another challenge with past approaches is that they usually treat each word or phrase on its own, without looking at the details inside each keyword or the relationships between keywords. They might use a single attention layer that tries to look at everything at once, but that can miss the finer details. As a result, computers using these models still make mistakes that humans would not.
In summary, previous methods either ignored the order of keywords and lost important details, or they paid too much attention to order and did not handle keyword arrays well. None of them could really understand both the inside of each keyword and the context between keywords at the same time. That’s the gap that this new patent tries to fill.
Invention Description and Key Innovations
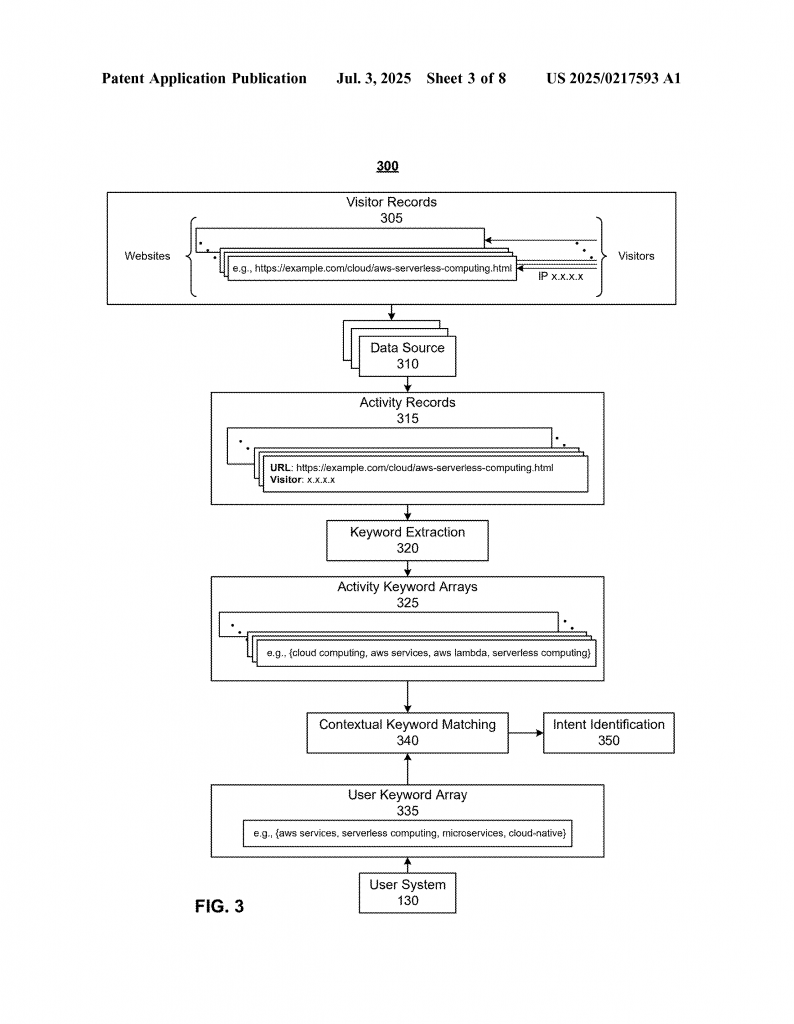
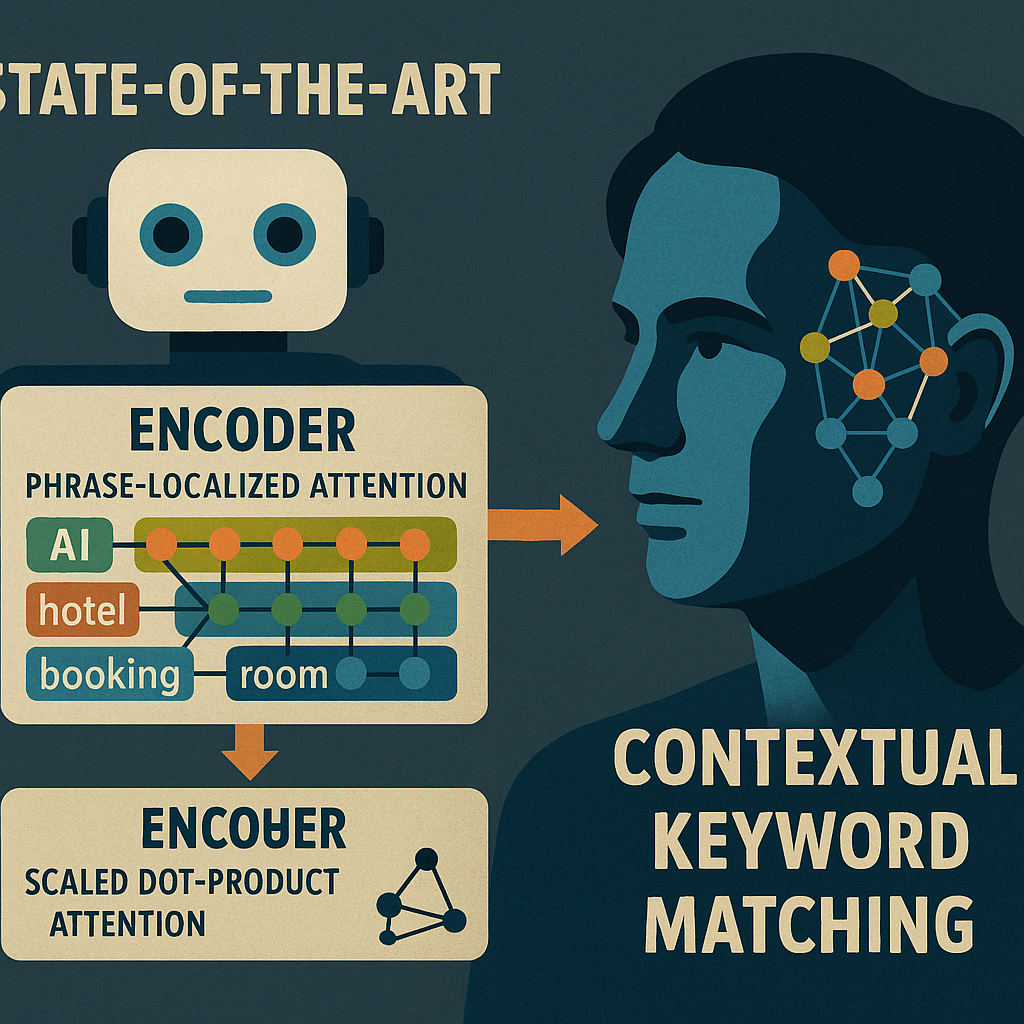
This patent introduces a new way for computers to match keywords by using artificial intelligence that truly understands context. The core of the invention is a special encoder that has two main parts: phrase-localized attention layers and scaled dot-product attention layers. Let’s break down what this means and why it matters.
First, the system takes in two things: a user keyword array and many activity keyword arrays. Each keyword array is a set of keywords, and each keyword can have one or more tokens (words or parts of words). For example, “cloud computing” is a keyword made up of two tokens: “cloud” and “computing.” Each activity keyword array is tied to an activity record, which has a website address (URL) and an IP address. This means every time someone visits a website, their activity is recorded along with the keywords that describe that visit.
The process starts by using an encoder to turn the user’s keyword array into a “user embedding vector.” An embedding vector is just a set of numbers that represent the meaning of the keywords in a way the computer can understand. The encoder is special because it is made up of one or more phrase-localized attention layers. Each of these layers has a separate attention network for each keyword in the array. This means the model can look inside each keyword, understand the order of the tokens in that keyword, and learn its structure. So, it knows the difference between “cloud computing” and “computing cloud,” even if the order of keywords in the array changes.
After the phrase-localized attention layers, the encoder uses scaled dot-product attention layers. These layers look at the relationships between all the keywords in the array. While the first part focuses on the inside of each phrase, this second part focuses on how the different phrases relate to each other. This two-step process helps the system understand both the details and the big picture.
To make sure the order of keywords does not matter (since keyword arrays are not sentences), the system uses “keyword-level positional encoding.” This means it resets the position count at the start of each keyword. So, every keyword is treated the same way, no matter where it appears in the array. This is what makes the model permutation-invariant — it gives the same result even if you shuffle the keywords.
The encoder is trained using a method that helps it learn the meaning and context of keyword arrays. During training, it is shown many keyword arrays. In each round, one keyword is hidden, and the encoder is asked to guess what is missing based on the rest. This helps the model get very good at understanding the relationships between keywords and the context they create together. After training, the decoder part (the part that guesses the missing keyword) can be removed, and just the encoder is used to turn any new keyword array into an embedding vector.
When it is time to match keywords, the system runs the user’s keyword array and every activity keyword array through the encoder. It then compares the resulting embedding vectors using a similarity metric, often cosine similarity. If the vectors are close enough, that means the contexts are similar, and the system counts it as a match. The matching activity records are then collected and sent to other tools, like models that predict if a company is about to make a purchase.
This approach is powerful because it avoids many of the mistakes that older systems make. It understands the fine details inside each keyword, gets the big picture across multiple keywords, and ignores the order of keywords in the array. This means fewer false matches and more relevant results. For businesses, that means reaching the right people at the right time, making better marketing decisions, and getting more value from their data.
On the technical side, the invention can use any number of phrase-localized attention layers and scaled dot-product attention layers, but the patent suggests using three of each for best results. Both types of layers use multi-head attention, which means the model can focus on different aspects of the data at the same time. The system can also be used as software, hardware, or a mix, and it can run on servers, in the cloud, or on local machines.
Finally, the invention is flexible. It can be combined with other features, and the patent covers both the method and the system for doing all of this. It can be used in many ways, not just for marketing, but for any problem where context-aware keyword matching is needed.
Conclusion
The patent application we explored today marks a big step forward in making computers truly understand what people mean, not just what they type. By combining phrase-localized attention with keyword-level positional encoding and scaled dot-product attention, the system can see both the details inside each keyword and the context that connects them. This leads to smarter matches, fewer mistakes, and better business results. As online data keeps growing, and as companies look for better ways to connect with their audience, solutions like this will become even more important. With this invention, the future of keyword matching looks bright, accurate, and context-aware.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217593.

