Accelerate Data Insights: Parallel Processing of Distributed Graph Queries for Faster Analytics

Invented by KARLBERG; Jan-Ove Almli, GJERDRUM; Anders Tungeland, INDREBERG; Marius

Today, data is everywhere. Big companies, governments, and even small businesses keep their data in many places. This can be emails, files, messages, events, or records. All this information is often stored in different databases or cloud systems. But what if you want to find something across all these places, quickly and safely? This is hard because each data source works in its own way.
A recent patent application proposes a smart way to solve this problem. It introduces a system for parallelizing distributed graph queries using a “graph metaphor.” This system makes it much faster and easier to search, fetch, and control access to data across different sources. In this article, we will break down this invention so anyone can understand how it works, why it matters, and what makes it special.
Background and Market Context
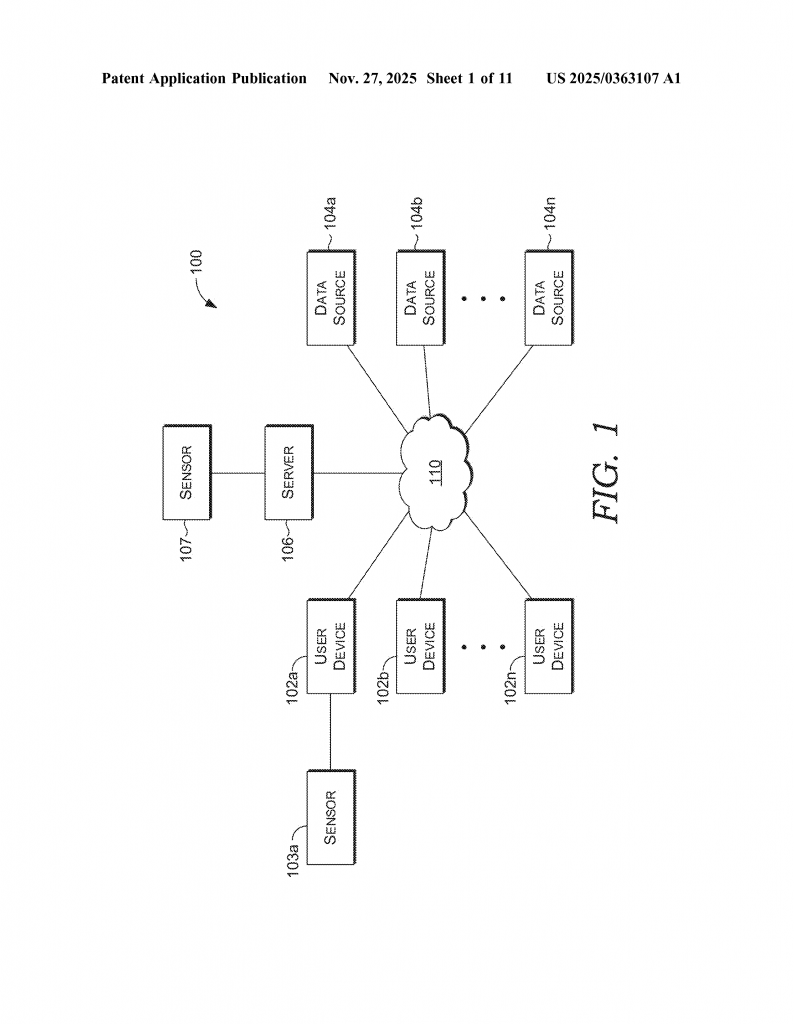
Let’s begin by thinking about the world we live in today. Most organizations use many different databases and platforms to store their data. Some of these databases are in the cloud, some are on company servers, and some may even be in other countries. This is called a federated database system. In a federated system, each separate database can work on its own, but they all connect together in some way.
Imagine a large company with offices in New York, London, and Tokyo. Each office uses its own database to store emails, files, and contact lists. Now, imagine an employee in New York wants to search for all files related to a project, including those stored in London and Tokyo. This employee wants results fast, and they want to be sure they only see files they are allowed to access. In the past, such a search could take a long time and would often require special teams or tools to run queries one at a time, often waiting for one search to finish before starting the next.
This is where the problem starts. Most systems search one place at a time, in a sequence. This method is slow. It also uses a lot of computer power and network traffic. When the search is slow, users get frustrated, and companies lose time and money. Plus, different data regions might have their own rules about who can see what. This makes it even harder.
The market is hungry for a solution that can:
– Search many places at once, not one after another
– Keep data secure and follow access rules
– Work fast, even with lots and lots of data
– Make it easy for users to find what they need without being experts
The need for this kind of technology is only growing. Companies are moving more data into the cloud. They need to manage data across many apps and services, often spread out worldwide. More and more, business depends on finding and using data quickly. If a company cannot do this, it falls behind.
This patent application addresses these market needs. It promises a way for computers to search many different data sources at the same time, while handling all the rules about who can see what. It does this by using something called a graph metaphor to model the data and its relationships.
A graph metaphor is like a map. The map shows places (called nodes) and how they connect (called edges). In this map, each node could be a file, an email, a person, or a device. The edges show how they relate to each other—maybe a file is attached to an email, or a person owns a device.
With this technology, companies can keep their data in the best place for each type, but still search across everything as if it were all together. This is a huge step forward for organizations that care about speed, security, and ease of use.
Scientific Rationale and Prior Art
To really understand this invention, we need to look at how things were done before, and why those ways had problems.
Traditionally, companies used graph databases to store and search data in the form of a graph. This means all the data and their connections are stored together, making it easy to run graph queries. But in the real world, not all data is stored this way. Most data lives in many different types of databases—some are for emails, some for files, some for contacts, some for logs. Each system has its own rules, formats, and security settings.
Some systems tried to bring all the data into a single graph database. But this is hard. Moving huge amounts of data into a new system is risky and costly. It can mean downtimes, lost data, or even security problems. Plus, each source is often optimized for its own type of data, and putting everything together can slow things down.
Another approach was to query each source one by one. For example, if you want to find all emails and files about a project, the system would search emails first, then files, then contacts, and so on. This method is called sequential querying. It is simple, but very slow. If you have to wait for each search to finish before starting the next, it can take a long time, especially if one source is slow or has network issues.
Some solutions tried to speed this up by sending multiple queries at the same time. But this brings new challenges. Each data source may have its own way of handling access control—who can see what. If you fetch data before checking if the user is allowed to see it, you risk leaking sensitive information. If you check access control first, you slow things down even more.
Prior art in this field includes:
– Systems that use a knowledge graph stored in a graph database, but require all data to be moved into that system.
– Query engines that send out queries to different sources, but handle them in a set order, not in parallel.
– Some systems that run queries in parallel, but do not handle access control or data merging very well.
These older methods often ignored the real-world problem that data is distributed, access rules are complex, and users want answers fast. They either sacrifice speed for security, or security for speed. They also rarely make it easy for systems to know which queries can be run at the same time, and which must wait.
The scientific challenge is to design a system that can:
– Model all data and its relationships, even when the data is spread out
– Decide which queries can run together and which cannot
– Check access rules at the right time, so no data is leaked
– Combine results from different sources without duplicates
– Do all this automatically, without needing humans to plan every step
This invention builds on the idea of a graph metaphor. Instead of moving all data into one place, it creates a map (the graph metaphor) that points to where the data lives now. Each node in the map has information about what it is, where it lives, and what rules apply to it. Each edge describes the relationship between things and any special rules for following that relationship.
The system receives a query and uses the graph metaphor to plan how to answer it. It figures out what needs to be fetched, from where, and what rules must be checked. Then, it decides which parts can be done in parallel. For example, it might fetch files from Tokyo while checking access control for emails in London, all at the same time. This smart planning leads to much faster searches, with less network traffic and less risk.
What is new here is not just running queries in parallel, but doing so while handling all the tricky rules about who can see what, and doing it in a way that works for real, distributed data. The system can even use machine learning to decide the best way to run the queries, based on past experience.
Invention Description and Key Innovations
Now let’s look at what this invention really does, and what makes it special.
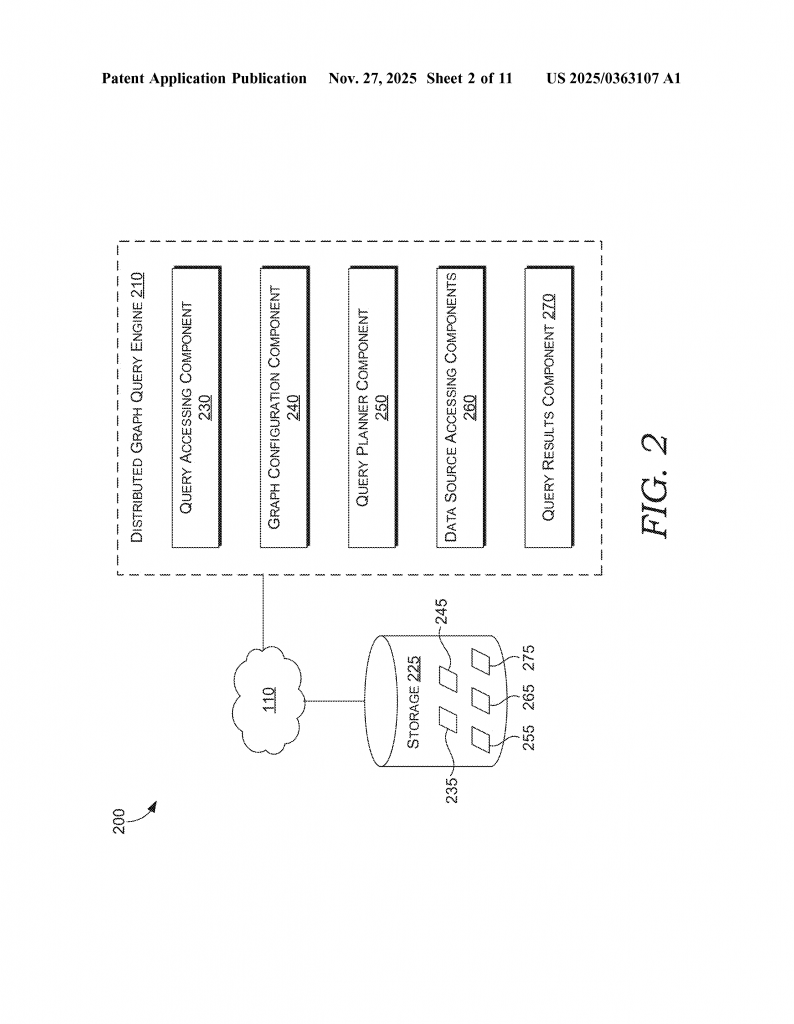
At its core, the invention is a computerized system that can make and run smart plans for searching data across many different sources, all at once, using a graph metaphor. Here’s how it works, step by step, in simple language:
1. Build the Graph Metaphor: The system creates a map (graph metaphor) of all the data sources. Each node in the map represents an item like a file, email, user, or event. Each edge shows how items relate. The nodes and edges store information about what they are, where the data lives, and what rules apply. This map does not store the actual data—just pointers and rules.
2. Receive and Parse the Query: When a user or program wants to find something, it sends a graph query to the system. The system reads the query and uses the graph metaphor to figure out which data sources need to be searched, what needs to be fetched, and what rules must be checked.
3. Create a Query Plan: The system uses the information in the graph metaphor to plan the steps needed to answer the query. It figures out which operations can be done at the same time (in parallel) and which must wait. For example, it might decide to fetch files from one source while checking access for emails in another.
4. Handle Access Control: Access control is a big part of the plan. The system knows the rules for each data source and each piece of data. It checks if the user is allowed to see each item. Sometimes it can check access while fetching the data. Other times, it fetches the data into a safe space (called a “sandbox”) and only releases it if access is granted.
5. Run Queries in Parallel: The system executes the steps that can be done at the same time, using plug-ins for each type of data source (like APIs, SQL, or search engines). This means data can be fetched from Tokyo and London at the same time, while access is checked in New York, for example.
6. Merge and Clean Results: Once the data is fetched and access is checked, the system merges the results. If there are duplicates, it removes them. The final result is then sent back to the user or program that asked for it.
7. Optimize with Machine Learning: Over time, the system can learn which query plans work best. It can use this knowledge to decide how to run future queries even faster and more efficiently.
Let’s look at some key innovations in this invention:
1. Dynamic, Parallel Query Planning: The system does not just run queries in parallel—it plans them dynamically. It looks at what is being asked, what the rules are, and what the current state of the network and data sources is. It then decides which steps can be parallelized and how. This planning can take into account latency, cost, and even reliability.
2. Access Control as a First-Class Citizen: Unlike older systems that handled access control as an afterthought, here it is built into the planning. The system can check access at the right time, even in parallel with data fetching. If access cannot be confirmed right away, data is held in a sandbox and only released when safe.
3. Flexible Graph Metaphor: The graph metaphor is very flexible. It can model any type of data and any kind of relationship, across any number of data sources. It stores not just what things are, but what rules and constraints apply. This makes it possible to plan complex queries without moving data around.
4. Smart Plug-in Architecture: The system uses plug-ins to talk to different data sources. This means it can work with any kind of database, API, or service, as long as there is a plug-in. This makes it very adaptable.
5. Machine Learning for Optimization: The system can use statistics, rules, or even machine learning models to choose the best way to run queries. For example, it can learn that running certain queries in parallel saves time, while others are better run in sequence.
6. Handling Conditional Access Rules: The system can even handle rules that depend on things like time of day, location, or other factors. For example, access to certain data may only be allowed during work hours or from certain networks. The system can model and check these rules as part of the query plan.
7. Sandbox Environments for Data Security: When data is fetched before access is confirmed, it is kept in a safe sandbox. Only if access is confirmed is the data released. This prevents leaks and makes sure no one sees data they shouldn’t.
8. Region-Aware Execution: If data must be fetched from different regions (for example, for legal or compliance reasons), the system can fetch access tokens in the right place and send them with the query, or fetch new tokens as needed. This keeps things fast and compliant.
All these innovations work together to create a system that is fast, secure, and flexible. It can handle any type of data, any number of sources, and any set of rules, without needing humans to plan each search. This is a big leap forward for organizations that need to find and use data from many places, quickly and safely.
Conclusion
The patent application for programmatically parallelizing distributed graph queries of a graph metaphor offers a smart, modern solution to a real problem. In a world where data is everywhere and rules are complex, this invention makes it possible to search across many data sources at once, without sacrificing speed or security.
By using a flexible graph metaphor, dynamic query planning, and careful handling of access control, the system can answer complex questions quickly and safely. It can adapt to any data source, use machine learning to get even better over time, and handle the most complicated rules about who can see what.
For businesses, this means faster answers, better security, and happier users. For technology teams, it means less manual work and more confidence that data is managed the right way. And for the future, it means a foundation for even smarter, more connected systems.
If your organization struggles to find and use data across many platforms, or if you care about security and speed, this technology could be a game changer. It brings together the best ideas from graph theory, distributed computing, and access control, in a simple yet powerful way. As data keeps growing and spreading out, solutions like this will only become more important.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250363107.

