Seamless Data Integration: Effortless Metadata Sync Across Multiple Cloud Platforms for Modern Enterprises
Invented by Ma; Jiyue
Data lives everywhere. It moves fast, gets split up, and often sits in different places at once. Bringing all that data together, making sense of it, and using it to drive business can be very hard, especially when different tools and systems are involved. This new patent application shows a way to solve those problems. Let’s break it all down so it makes sense, even if you’re not a tech expert.
Background and Market Context
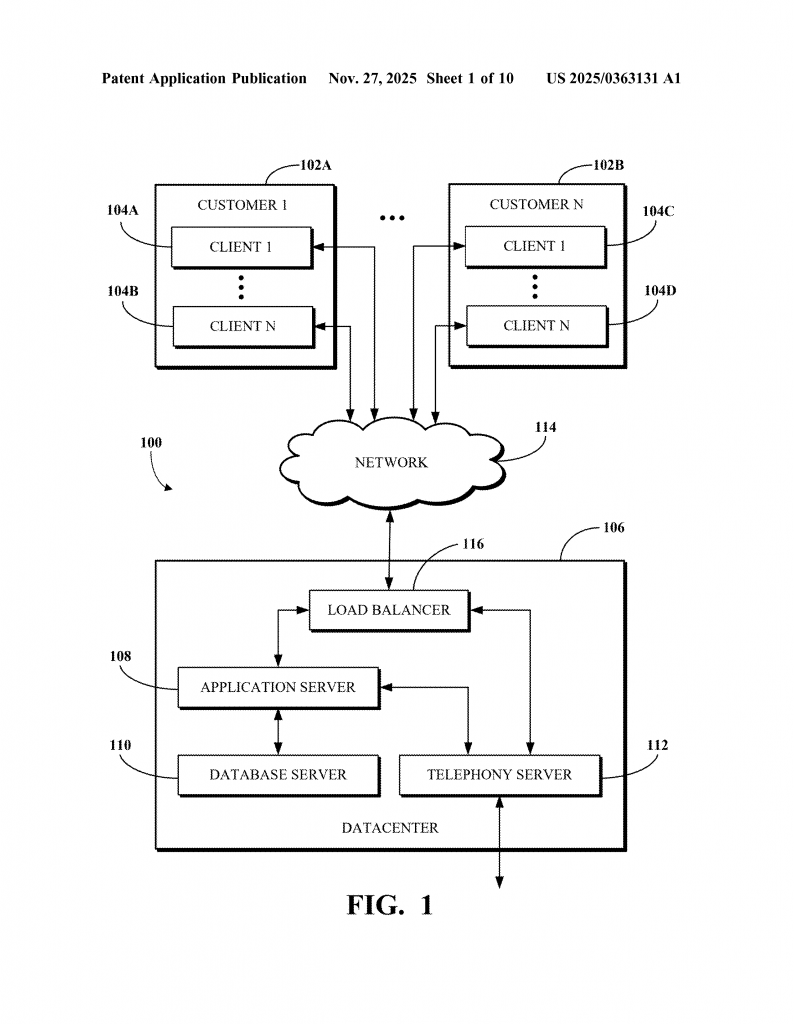
Imagine you are running a business. Your company uses video calls to connect with customers, sends messages between teams, and stores client records in large databases. Some of these tools are in the cloud, some are on your own servers, and others are rented from different technology providers. All these different systems need to work together, but each one keeps its data in its own way. This makes it tough to pull all your information together when you want to run a report, do some analysis, or use new tools like artificial intelligence to spot trends.
This is not a problem only for big companies. Even small businesses use many different software tools and cloud services. Each service often has its own “data warehouse” or “data lake”—think of these as giant digital filing cabinets. And each has its own “metastore,” which is a special place that stores information about where data lives, how it is organized, and who can use it. The challenge comes when you want to process data that lives in many different places at once, or when you want to use a tool that your main data system doesn’t support.
For example, you might want to take customer records from one system, run a report using a fancy analytics tool from another provider, and then send the results to a third tool that emails customers. This is hard because:
1. Each system organizes its data differently.
2. The rules about who can access what data are different in each system.
3. You risk losing or corrupting data as it moves from place to place.
4. New tools using artificial intelligence need lots of data from many places, but getting that data can be slow and error-prone.
Companies want a solution that lets them:
– Use their existing data no matter where it lives.
– Safely manage who can access data.
– Run new types of analysis (like AI) without moving all their data around.
– Make sure all the “metadata” (the information about data, like how it is split up or who owns it) stays in sync, so nothing gets lost or mixed up.
The patent application we’re examining tackles these exact issues. It offers a way to manage and connect different data systems using a special type of manager called a “metastore manager.” This manager helps tools talk to each other, keeps metadata lined up between different systems, and lets powerful data pipelines do their work across all the data, no matter where it lives. This is key for companies using modern cloud platforms, big databases, and AI-powered apps—basically, almost everyone today.
Scientific Rationale and Prior Art
Before this invention, there were some ways to connect different data systems, but they had real problems. Let’s look at what these older solutions did and why they often fell short.
Most big data platforms (think of names like Apache Spark, Flink, or Hadoop) use their own way of storing and organizing data. Each one has a “metastore” that holds information about data tables, how big files are split up (called “partitions”), and other important facts. If you run a report or a job in Spark, it asks its own metastore where to find the data, how it is laid out, and what rules to follow.
Sometimes, companies would manually copy data from one system to another. This is slow, uses a lot of storage, and can lead to mistakes. Other times, they would use special “connectors” or “APIs” to let one system read another’s data, but these only work if both systems are set up just right. If you change something in one system, the other may not know about it. This can lead to errors, lost data, or the need to run jobs all over again.
Another problem is with “metadata sync.” When data is changed in one place (for example, a new data partition is added after a job runs), the other systems might not know about it. This means that jobs in other systems could use old data, or miss new data entirely. For companies that need up-to-date numbers—like in finance or customer service—this is not acceptable.
Artificial intelligence and machine learning tools make things even harder. These tools often need to read data from many sources, process it quickly, and output new data to yet another system. If the connections are not smooth and the metadata is not kept up to date across all systems, the AI tools might not work right or could give wrong results.
Some prior solutions tried to fix these issues by building bigger, more complicated data warehouses that tried to bring all data into one place. But this is very costly, slow, and does not work well for real-time or fast-changing data. Others tried to build “federated” systems that let queries run across different systems, but these often struggle with keeping metadata (like partitions and permissions) in sync.
This patent application recognizes that the key is not just moving the data. It is about moving and syncing the metadata that describes the data, and making sure that new data pipelines can use all this information, no matter where it lives. By introducing a “metastore manager” that acts as a bridge and a coordinator, the invention lets different systems talk to each other, keeps metadata updated, and lets new tools (including AI) work across all the data.
The idea of a separate manager for metadata is not completely new. But this application introduces a system where the metastore manager:
– Syncs metadata between systems, so updates in one are reflected in the other.
– Lets new data processing jobs (or “pipelines”) access data across platforms, even if they are not directly connected.
– Allows for distributed jobs (like SQL queries or AI tasks) to be run on processed data, and for results to be sent to new places (like a unified communications platform).
This is a real step forward because it means you don’t need to rebuild your data stack, or move all your data into one system. The metastore manager is like a translator and a traffic cop, making sure every system knows what’s going on. It helps data flow smoothly, safely, and quickly, which is what today’s businesses need.
Invention Description and Key Innovations
Now, let’s look closely at what this patent application covers, and why it matters. We’ll keep things simple and clear, using easy words and examples.
The main idea is to use a “metastore manager” to help move, sync, and process data across different systems. Here’s how it works:
1. A job (like a report, a query, or an AI task) starts in one system. This is called the “first data management platform.” It has its own data (the “first data store”) and its own metastore, which tracks how the data is split up and organized.
2. The job runs and creates a new set of processed data (the “first processed data set”). The metastore is updated with new information about this data, including how it is split (partitioned).
3. The metastore manager now syncs the metadata from the first platform to another system (the “second data management platform”). This means that the second system knows about the new data, how it is partitioned, and how to access it.
4. The metastore manager then “activates” a new data processing pipeline. This pipeline is not directly connected to the first system—it talks to the second system (which now has the metadata and can access the data, thanks to the sync).
This pipeline can now:
– Get the partition metadata it needs to read the new data.
– Fetch the processed data, even though it lives in the first system.
– Run new processing jobs (like more SQL queries, or even AI tasks).
– Output the results to anywhere, including back to the business’s main platform or to a customer-facing app.
What makes this special?
– The pipeline can be totally separate from the first system. It does not need special access or direct connections. It uses the second system’s interface and the synced metadata to work.
– The metastore manager keeps metadata in sync, avoiding errors or data loss.
– You can run jobs in one place, but use the results everywhere. This is great for AI, real-time analytics, and any workflow that needs to cross system boundaries.
– The system supports jobs that use SQL (the main language for databases), and also supports jobs that need special resources (like extra computing power or AI features).
Let’s use a real-world example:
A company runs a video meeting platform (like Zoom or Teams). All the meeting records are stored in one cloud system (the first data management platform). But the company wants to run AI analysis on the meetings to pick out action items or spot problems. The AI tool lives in another system (the second data management platform), which is better for running machine learning jobs.
With this invention, a “driver node” in the video meeting platform asks the metastore manager to start a data processing job. The job runs, processes the meeting data, and stores new results. The metastore manager syncs the new metadata with the AI system. It then activates a pipeline so the AI tool can read the new meeting data, analyze it, and output results (like a summary or list of action items) to the company’s main platform.
This works for any type of data: customer records, chat logs, sales numbers, and more. It means you can use the best tool for each job, without worrying about moving all your data around or losing track of how it’s organized.
The patent also covers ways to make these jobs efficient and safe:
– The metastore manager can create and use “directed acyclic graphs” (DAGs), which are like maps of how data flows through each job.
– It can allocate computing resources as needed, so big jobs get enough power to run fast.
– It supports jobs that use SQL and jobs that use AI.
– It can send results to special business platforms, keeping everything connected.
All of this is done in a way that is careful with privacy. If a job uses AI, personal data is not used to train the AI model (unless the business says it’s okay). The AI only looks at personal data to do its job, not to improve itself for the future. This is important for safety and trust.
The claims in the patent cover:
– The method of syncing metadata and activating pipelines.
– The use of a metastore manager to do all the coordination.
– The ability to run jobs across systems, even if the systems are not directly connected.
– The use of SQL, DAGs, and AI in these jobs.
– The ability to output results to different business systems.
In summary, this invention is like a universal translator and traffic manager for business data. It lets you use your data wherever it lives, with whatever tools you want, while keeping everything in sync and safe. For any company using cloud platforms, AI, or modern analytics, this is a big step forward.
Conclusion
Bringing together data from many different places has always been hard. Different platforms have their own ways of organizing and protecting data, which makes it tricky to run jobs or use tools across systems. This new patent application solves that problem by introducing a smart “metastore manager” that keeps metadata in sync and lets powerful data pipelines work across different platforms, even if they’re not directly connected.
With this system, businesses can:
– Run jobs in one system and use the results in another.
– Keep metadata up to date and avoid errors or data loss.
– Use advanced tools like AI and analytics without moving all their data.
– Stay safe and respect privacy when using personal data.
This approach is simple, smart, and fits perfectly with how companies use data today. It allows businesses to get more value from their information, move faster, and use the best tools for every job. The patent covers the key ideas and methods that make this possible, and it marks a new way forward for data management in a connected world.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250363131.

