AI-Powered Platform Delivers Safer, More Accurate Code for Software Development Teams
Invented by Le; Hung, Sahoo; Doyen, Zhou; Yingbo, Xiong; Caiming, Savarese; Silvio
The world is changing fast. Computers write code, not just people. But sometimes, the code a computer writes is broken or unsafe. A new way to fix this problem is here. It lets AI models “talk to each other” to check and improve the code before anyone uses it. This blog will break down how this new method works, why it matters, and what makes it different from anything before.
Background and Market Context
AI is everywhere now. It helps us search, chat, write, and even program computers. Big tech companies use large language models (LLMs) to do things that used to take teams of people. With just a few words, you can ask an AI to write a program for you. This is making software development much faster. But there is a big problem: sometimes the code these AI models write is wrong, or even dangerous.
If the code is wrong, it could crash your app, cost you money, or waste time. Even worse, unsafe code can be hacked, exposing private data or letting attackers take control. As more people and companies use AI for writing code, the risks also grow. Businesses want code that works and is safe, but that’s not easy when the AI can make mistakes or “hallucinate” answers that sound right but are not.
Companies have tried different ways to fix this. Some use more people to check AI-written code. Others make new tools to test and review it. But these ways can be slow and expensive. The market needs a way for AI to check itself and improve its own code, quickly and reliably. That’s where the idea of “internal dialogue” or “joint code generation with critique loops” comes in.
With this new invention, several AI models work together. One writes the code. Others review and critique it. Then, the first model uses this feedback to fix and improve the code. The code is even tested before it is sent to the user. This brings a new level of trust and safety for anyone using AI to write code, from solo programmers to big companies building the next big thing.
AI-powered code generation is moving from a nice-to-have to a must-have. But as the market grows, so does the demand for code that not only works but is safe, clear, and reliable. This new invention is set to shape the future of software development by making AI-written code trustworthy, quick, and secure.
Scientific Rationale and Prior Art
To understand why this new method is important, let’s look at how AI has written code in the past and what problems came up.
Large language models like GPT-3 or Codex are trained on lots of code and text. You give them a prompt, like “Write a Python function that adds two numbers,” and they give you the code. This is called “single-shot” generation. But these models can make mistakes. They might mix up the requirements, leave out steps, or choose unsafe ways to solve problems. Sometimes, their answers just don’t make sense even if they look good at first.
To fix bad code, some systems add an extra step: review. A human or another AI reads the code, looks for bugs or risks, and suggests changes. Some companies use “linting” tools or static analyzers to find problems. Others run lots of tests to see if the code works. There are even AI-powered code review tools that point out problems and suggest fixes. But these checks are usually separate from the code-writing step and can miss complex or hidden issues, especially around security.
Some research tried to close this gap by having the AI model “think” more deeply. For example, “chain-of-thought” prompting gets the AI to explain its reasoning. “Self-refinement” lets the AI generate code, check its own work, and try again if it finds problems. But often, it’s the same AI model checking its own work — like proofreading your own essay. You might miss obvious mistakes because you’re not looking at it with fresh eyes.
Other ideas include reinforcement learning, where the model gets rewards for better code, or “ensemble” methods where several models vote on the best answer. But these can be slow, costly, or hard to set up. And they often focus on just one thing: correctness. They do not always check for safety, security, or other important qualities.
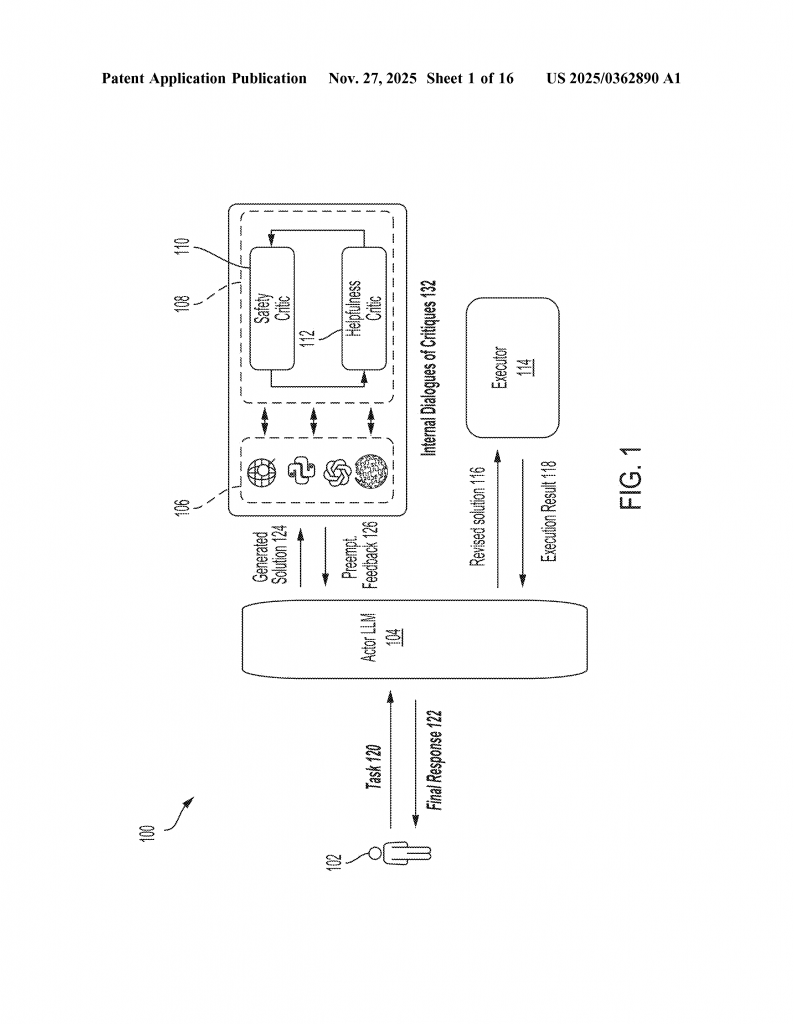
The new method stands out because it uses several different AI models, each with a special job. One model writes the code. Another checks if the code matches the task (helpfulness). A third checks if the code is safe (no hacks or risks). They “talk” to each other, share feedback, and work together to make the code better. This is more like a team of experts working together, not just one person guessing. The process can even bring in outside tools, like web search or code execution, to double-check the work.
Previous methods often stopped after one round of feedback. The new approach can loop as many times as needed until the code is both correct and safe, or until no new problems are found. This brings together the best parts of human code review, AI power, and real-world testing in a single, smart process.
By combining multiple models with different “personalities” and goals, and letting them “debate” and critique each other, this invention creates a much stronger safety net for code generation. It’s not just about writing code faster — it’s about writing code you can trust.
Invention Description and Key Innovations
Let’s see how this new way of generating code actually works. Imagine you want an AI to write a program for you. Here’s what happens step by step, in simple words:
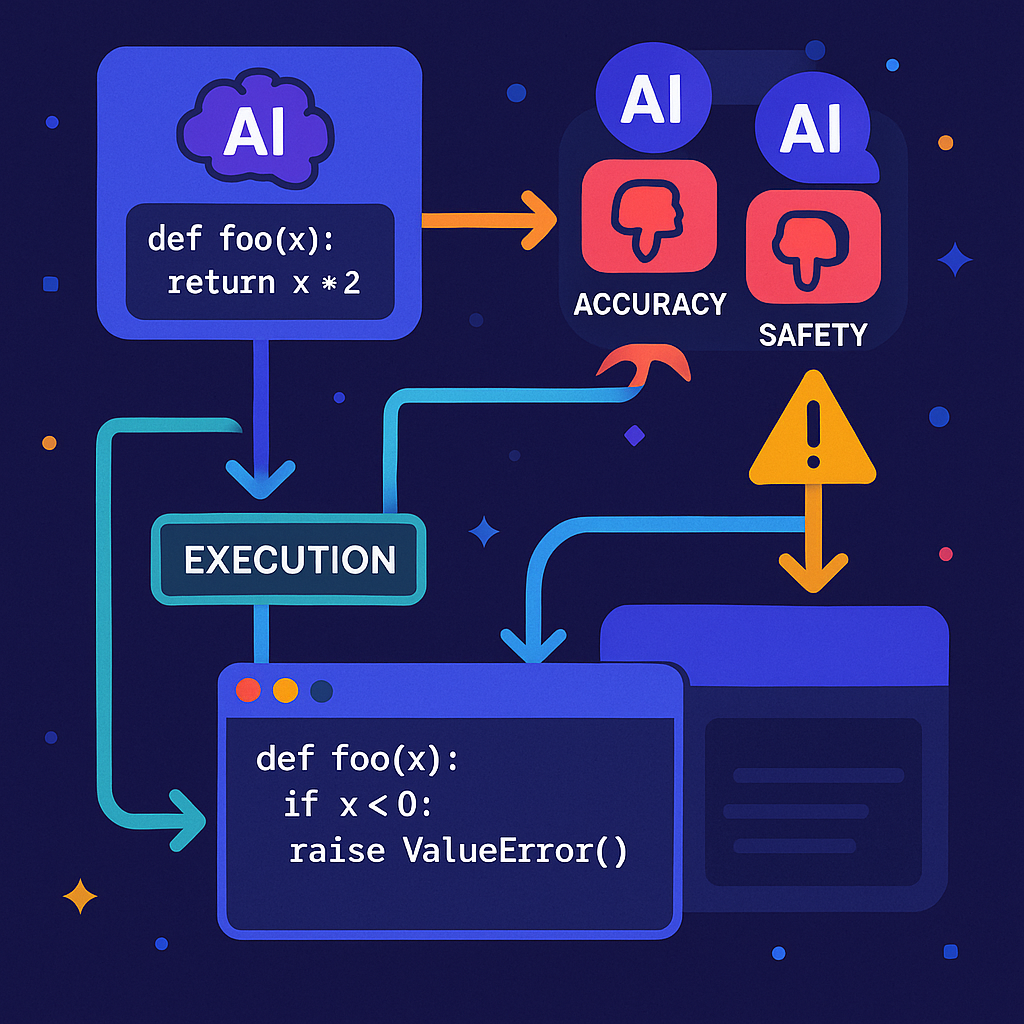
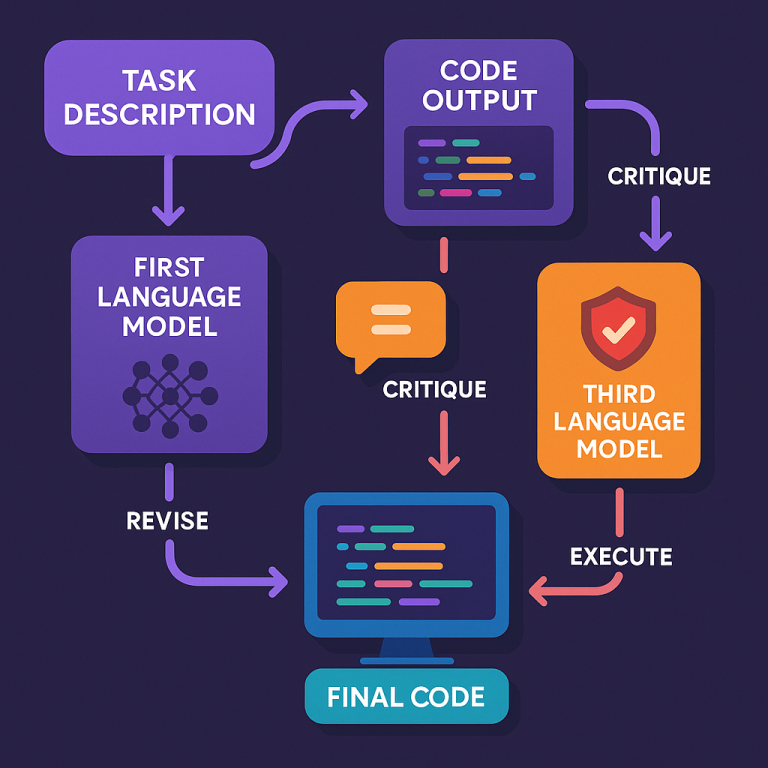
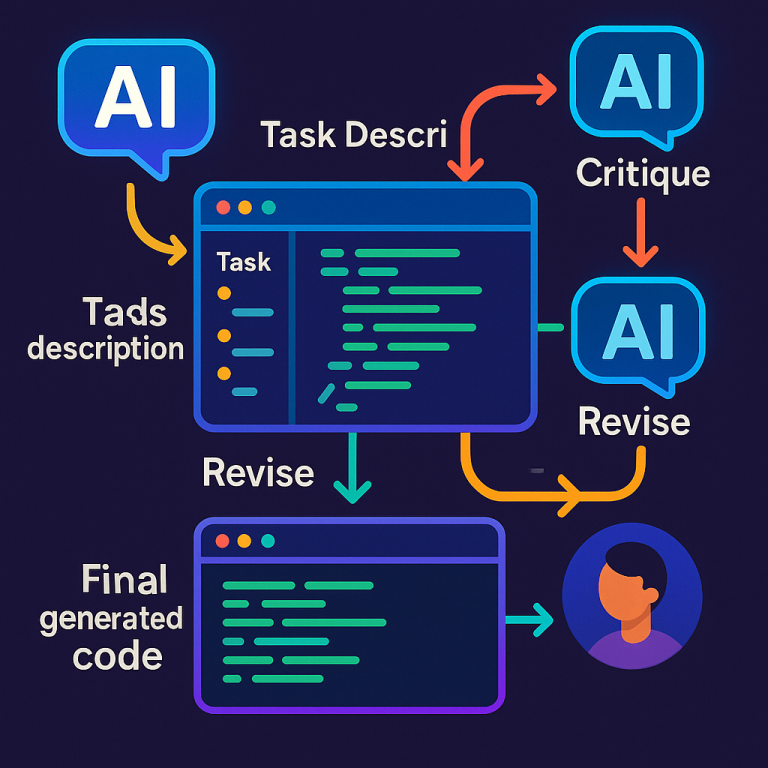
First, you tell the system what you want — maybe in plain English. For example, “Write a function to check if a number is prime.” The first AI model, called the “actor,” takes your request and writes the code.
Next, the code goes to a second AI model. This one is a “critic” that checks if the code does what you asked. Does it actually check for prime numbers? Does it miss any cases? The critic writes a short review explaining what’s good or bad about the code.
Then, a third AI model comes in. This one looks at your request, the code, and the first critic’s review. But its main job is to look for safety problems. Is the code safe from hackers? Does it avoid risky functions or bad practices? This critic also writes a review, focusing on safety.
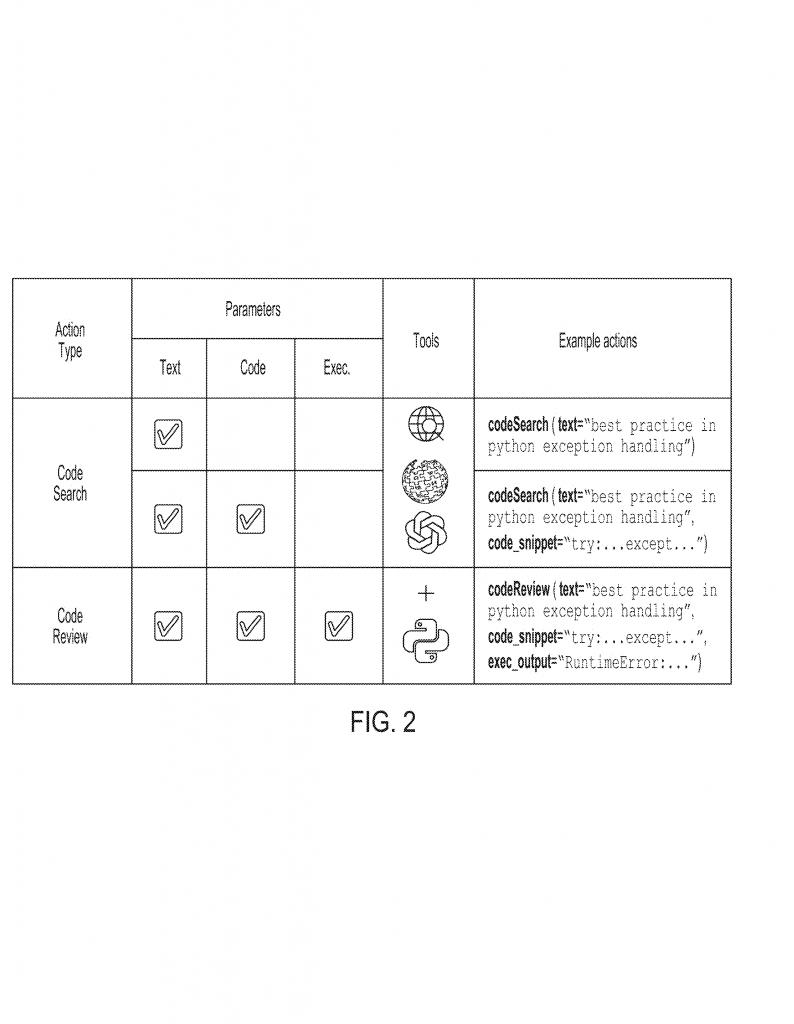
The actor model takes all this feedback — your request, the original code, both reviews — and tries again. It writes new code, fixing any problems found by the critics. This “revised” code is likely to be better: more accurate, safer, and closer to what you want.
Now comes the proof: the system runs the revised code in a special test environment (a “sandbox”) to see if it works. If the code still has errors or fails tests, this information goes back into the process. The actor can use the results — along with the previous feedback — to try again and make the code even better.
This cycle can repeat as many times as needed. Each round, the critics can look at the new code, check for new problems, and help the actor fix them. The process stops when the code passes all checks and tests, or when no new problems are found.
The invention is special because:
– It uses more than one AI model, each with a different role. This is like having a team of experts, not just one person.
– The critics can “talk” to each other, building a conversation and even debating points. This back-and-forth helps catch more problems.
– The process is flexible. You can set it to repeat a certain number of times, or stop when the code is good enough.
– The system can use outside tools (like web search or code interpreters) to double-check facts and test code for real, not just in theory.
– All the feedback, reviews, and test results are used together to make the code better at every step.
For example, the safety critic might say, “This code uses a function that can be hacked. Replace it with a safer option.” The helpfulness critic might say, “The code does not work for the number 2. Please fix.” The actor then combines these tips and writes improved code.
What’s more, the critics can use real tools. If they’re not sure about something, they can look it up online or run a small test. This makes their reviews more grounded and reliable.
The system is built to be smart with resources, too. Instead of training a huge, expensive AI for every job, it uses smaller, focused models that work together. This saves time and money, and makes the whole process faster.
In real-world tests, this invention has shown big improvements. The code it creates is safer (less likely to be hacked), more accurate (does what you asked), and more helpful (clearer and easier to use) compared to older methods. It works across many programming languages and in different situations, from simple scripts to more complex programs.
The key innovations here are:
– A team of AI models, each with a clear job: writing, critiquing for accuracy, and critiquing for safety.
– Internal dialogue: the critics “talk” to each other, building on each other’s feedback.
– Flexible, repeatable feedback loops: the process can go as many times as needed until the code is good.
– Use of outside tools: critics can search the web, run code, or use other tools to check their advice.
– Combining all feedback (from critics and code tests) into the next version.
– Adaptable to different programming languages and types of code.
This means users — whether they’re individual coders or big companies — get code that is not just fast, but also safe, correct, and ready to use. There’s less risk, less need for extra review, and more confidence in the results.
Conclusion
The future of coding is changing. With this new invention, AI models do not just write code — they check, debate, and fix it together, making sure what you get is safe and works the way you want. By bringing together multiple AI “voices,” testing code before use, and looping until the job is done right, this approach sets a new standard for AI-powered programming. The days of broken or unsafe code from AI are ending. Soon, with joint code generation and internal critique loops, you can trust the code you get, every time.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250362890.

