Unlocking Ultra-Efficient 3D Data Compression for Faster, Smarter AR and Digital Twins

Invented by LODHI; Muhammad Asad, PANG; Jiahao, AHN; Junghyun, TIAN; Dong
3D data is everywhere, from cars that drive themselves to games that pull you into a new world. But all that rich, detailed 3D information is hard to store and even harder to send over the internet. Today, we’ll break down a new invention that makes these big 3D files much smaller and easier to handle without losing what makes them great. Get ready to learn how smart sorting and attention help us pack 3D point clouds tight, faster and better than ever before.
Background and Market Context
Let’s start simple: what is a point cloud? Imagine lots of tiny dots floating in space, each one marking a spot on the surface of an object or in a scene. When you put all these dots together, you get a full 3D picture. These dots come from special cameras and scanners—like LiDARs on self-driving cars, or the sensors in your phone or a VR headset. Every dot has its own spot in space, and sometimes it even holds extra information, like color or how hard the light bounced back.
Point clouds are super useful. Self-driving cars use them to “see” the road and spot other cars, people, or obstacles. In movies and games, point clouds help make worlds look real. In construction, they help scan buildings and even save details about old statues or temples. If your phone has a LiDAR sensor, it’s already gathering point clouds to help you measure things or make 3D pictures.
But here’s the problem: these clouds can be gigantic. Even a small scene might have millions of dots. Storing and sending all that data takes a lot of space and time. If your car is sending 3D maps to the cloud, or your VR headset is streaming a world to your eyes, you need that data to move fast and not overload your device or your network.
Because of this, there’s a big push to find better ways to squeeze these point clouds down—shrinking their size while keeping all the details that matter. This is called compression. Sometimes, we want to keep every single dot and detail (lossless compression). Other times, we’re okay losing a little detail if it means a much smaller file (lossy compression).
Many industries need these solutions. Self-driving cars need to send and receive 3D maps quickly and safely. VR and AR companies want to deliver worlds that feel real, without waiting ages for them to load. Even engineers and architects want to store huge 3D scans on their laptops without filling up the hard drive. All these needs make 3D compression a hot topic.

To tackle this, experts have tried different tricks. Some turn 3D dots into blocks called voxels, kind of like 3D pixels. Others work directly with the dots. Each way has its own trade-offs in speed, size, and how much detail you lose. As 3D data gets more common, the demand for even smarter, faster compression keeps growing.
Scientific Rationale and Prior Art
Let’s dig into how people have been working with point clouds before this new invention came along. There are two big ways to handle all those 3D dots:
First, there’s the voxel-based approach. Imagine covering your 3D scene in a big grid of tiny cubes—like a box of sugar cubes. You mark each cube as “filled” or “empty,” depending on whether there’s a dot inside. This is like turning your 3D world into a blocky Minecraft version. The good part is that computers know how to work with grids, so you can use tricks from 2D pictures, like convolution, to process them. But here’s the catch: most of those cubes are empty. This makes the process wasteful, especially when you try to use big grids for lots of detail. Even when you only look at the cubes with dots inside (sparse convolution), you still end up with a system that gets slower and eats up more memory as you try to capture more detail.
Second, there’s the point-based approach. This one keeps the dots as they are. Instead of cubes, you look at each dot and its neighbors. Computers use things called MLPs (multi-layer perceptrons) to give each dot a list of features. Then, you gather info from nearby dots, either by pooling (like taking the average) or by using attention mechanisms (paying more attention to some dots over others). This means you can look at a bigger area without making your system much more complicated. But, finding all the nearby dots for every single point is slow and uses a lot of memory, especially with millions of points.
To solve this, experts built something called the Swin Transformer. Instead of searching for neighbors for every dot, you chop the point cloud into small windows (think of them as little groups of dots). Inside each window, you use attention to figure out which points are important. Then, you shift the windows a bit and do it again. This covers the whole scene without searching everywhere. But the Swin Transformer has its own problem: some windows have lots of dots, others have few or even none. This makes it hard for the system to learn well, because the windows aren’t balanced.
Some researchers tried fixing this by sorting the dots before grouping them into windows. They used different ways to sort, like following curves that snake through space. Sorting makes sure that each window has the same number of dots, and that the dots inside are close in space. It also means that dense areas (lots of dots) get smaller windows, while sparse areas get bigger ones.
Most previous research used these ideas for big-picture tasks, like classifying what an object is, or segmenting a scene. But these tasks only need to know broad features. Compressing point clouds, especially without losing any detail, is much harder. You need to keep track of fine details, not just big shapes.
There’s also the unique challenge of LiDAR data. LiDAR sensors spin and capture points in a specific order. Regular sorting doesn’t match this order, so you might lose the natural flow of data. Some attempts used domain-specific sorting, but none focused on compression at the fine, bit-by-bit level.
This new invention builds on these ideas. It takes the best parts of sorting and windowed attention, and makes them work for tough compression problems. It even adds a new way to sort points, matching how LiDAR sensors collect data, for even better results in real-world use.
Invention Description and Key Innovations
Now, let’s unpack how this new method works and what sets it apart.
The heart of this invention is something called the SortFormer. It’s a system built to compress 3D point clouds with more balance, speed, and accuracy than before. Here’s how it does its magic:
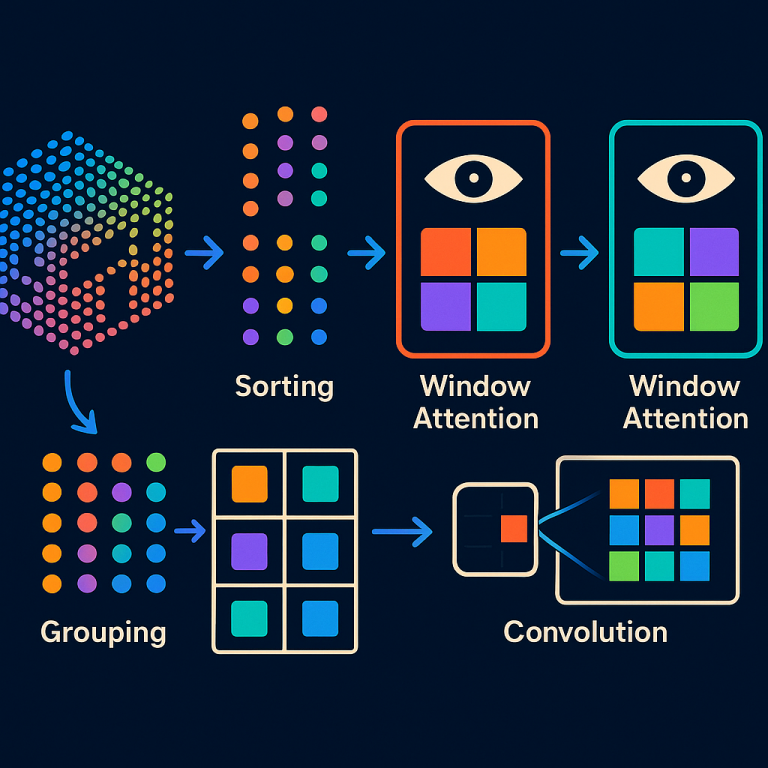
First, you start with your point cloud—a bunch of dots, each with its own location and maybe some extra info. The system sorts the points. Sorting is done in a way that keeps nearby points together. You can use special curves (like Z-order, Hilbert, or Peano) that snake through space and group points that are close. Or, for LiDAR data, you can switch to spherical sorting: you change the points’ coordinates to spherical (using angles instead of x, y, z), and sort by those angles. This matches the way LiDAR captures data, making the compression even better.
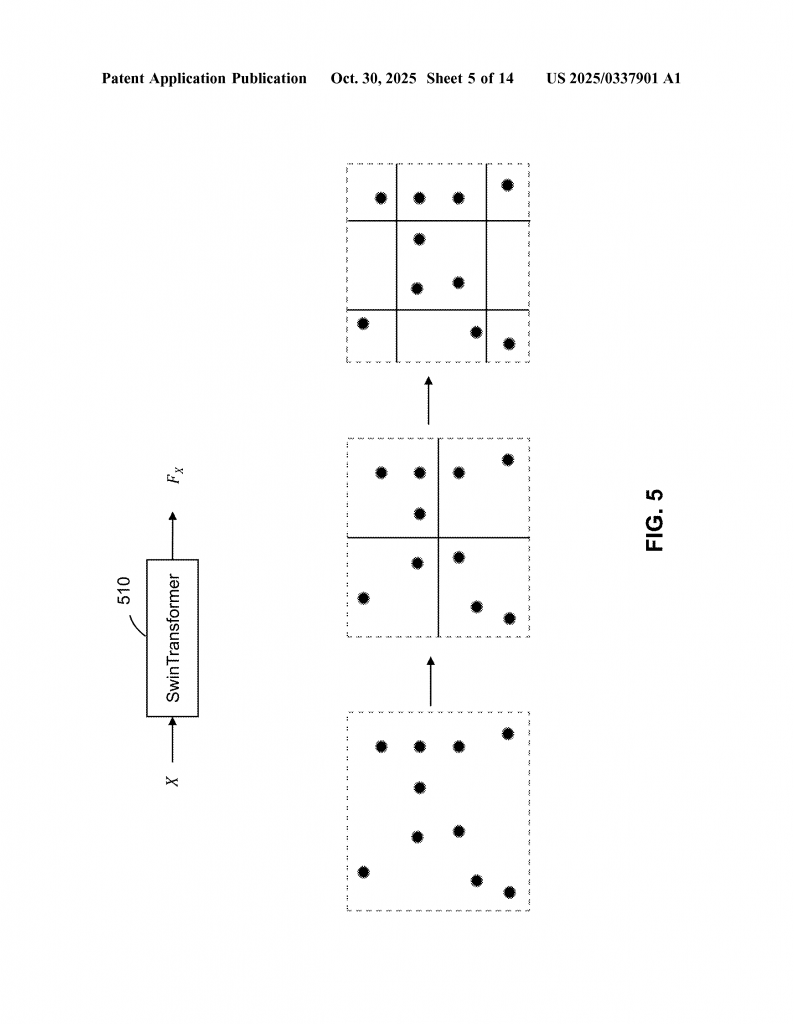
After sorting, the points are grouped into windows. Each window has the same number of dots. If there aren’t enough dots for the last window, some are padded with empty spots. This way, dense parts of the scene get more, smaller windows, and sparse parts get fewer, bigger windows. This keeps the system balanced and avoids the problem where some groups are empty and others are packed.
Inside each window, the system uses self-attention. This means it looks at all the points in the window and decides which ones are most important for the current task. It updates each point’s features based on what’s around it. Then, the windows are shifted—moved over by half the window size—and attention is done again. This lets each point interact with new neighbors, helping the system “see” more of the scene over a few rounds.
The invention supports both lossless and lossy compression. For lossless, it predicts probabilities for each point (or each node in an octree, which is a way of cutting the space into boxes). These probabilities help encode the positions of points in a way that can be perfectly reversed later. For lossy, it predicts where points should be based on the updated features, allowing some details to be left out if needed to save more space.
There’s also a smart way to combine information at different scales. After a few rounds of attention, the system can downsample—making a smaller, simpler version of the point cloud. Features are gathered at each scale, and then combined at the end. This multi-scale approach means the system can capture both fine details and big shapes, squeezing the data even tighter.
A hybrid approach is also possible. Here, the features inside each window are split into two parts. One part goes through the attention process, while the other goes through a convolution (like in 2D image processing). The results are then mixed together. This gives the system the strengths of both attention and convolution: attention is great for seeing long-range connections, while convolution is fast and good at spotting local patterns.
The attention mechanism itself is flexible. You can use the classic SoftMax attention, which is powerful but slow for big groups. Or, you can use linear attention, which is much faster and uses less memory. The invention even includes a special “focused linear attention” that’s tweaked for 1D groups of points, using depth-wise convolutions to make it work better for sorted point clouds.
If you want to compress huge point clouds, you can split them into blocks. Each block is compressed separately, using the same sorted window attention. This makes it easy to process and send parts of the scene, or even handle real-time video from a moving car or drone.
Finally, this system isn’t just for point clouds. It can also compress 3D meshes—the kind of models used in games and CAD software—by applying the same sorted grouping and attention to the locations of mesh points.
In practice, this means:
- Smaller files that keep more detail, even for huge, complex scenes.
- Faster processing, because the windows are balanced and the attention is efficient.
- Better results for industry-specific tasks, like LiDAR data, thanks to custom sorting methods.
- Flexibility to choose between lossless and lossy compression as needed.
- Simple integration into existing devices, since the system can run on regular processors with standard memory.
The SortFormer invention is a big step for 3D data. By keeping windows balanced, using smart sorting, and combining attention with convolution, it solves many of the problems that made 3D compression slow or lossy before. It’s ready for the next generation of VR, robotics, mapping, and more.
Conclusion
3D data is changing how we see and interact with the world. But all those millions of tiny dots are tough to store, send, and process. The new SortFormer system brings a clever way to sort, group, and compress point clouds so we can use them everywhere—faster, smaller, and with more detail. Whether it’s for self-driving cars, VR, building scans, or 3D maps, this system fits right in. If you’re working with 3D data, now is the time to look at smarter, sorted attention for your compression needs.
Ready to make your 3D worlds lighter and brighter? Keep an eye on advanced point cloud compression—because the future is taking shape, one smartly sorted dot at a time.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250337901.

