AI-Powered System Predicts Product Return Risks to Help Retailers Reduce Losses and Improve Sales
Invented by Bhatnagar; Nishant, Deshmukh; Vaishali Mahesh, Shankar; Vijaya Rajan, Toshniwal; Akshay Rakesh, E.; Tamilselvan, Subramanian; Naveen Kumaar, T.; Ganesan, V.; Jai Goutham
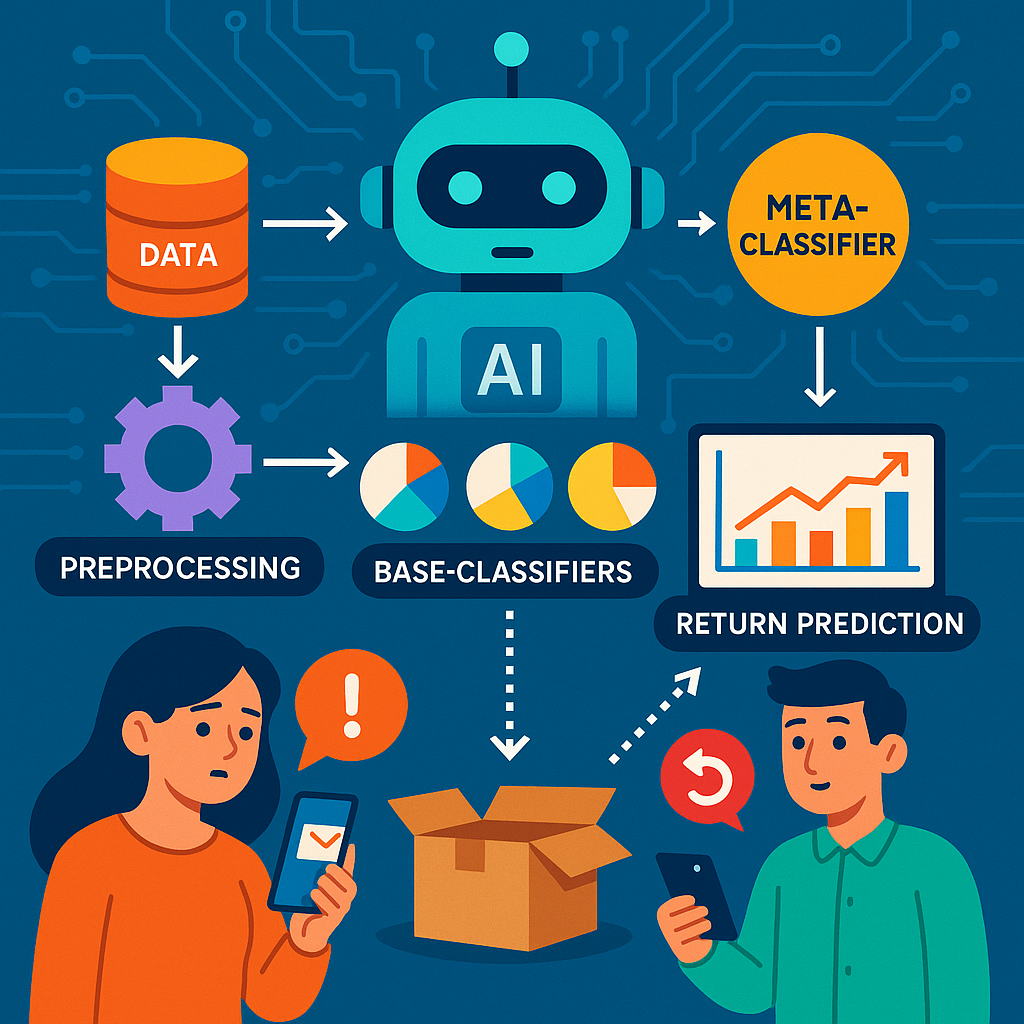
Predicting if a product will be returned is one of the biggest challenges in online retail. A new patent application proposes a smart system that uses AI to help stores and shoppers avoid returns and improve their experience. In this deep dive, we’ll look at why this matters, how the science behind it works, and what’s new in this invention.
Background and Market Context
Shopping online is now a part of everyday life. With just a few clicks, you can buy almost anything and have it delivered to your door. While this is great for shoppers, it creates a headache for stores: lots of people return things they buy. In e-commerce, as many as one in five items gets sent back. In some categories, like clothes or shoes, the number can be even higher.
Returns are expensive and messy. Every time something comes back, stores have to process it, restock it, or sometimes throw it away if it’s damaged. Often, the item can’t be sold again at the same price, and sometimes not at all. This means lost money and extra work for the store. It also makes it harder to keep track of what’s in stock and what needs to be reordered.
On top of that, many customers feel unhappy if their return isn’t handled well. They might not shop at that store again. For stores, keeping customers happy is just as important as making a sale. Unhappy customers can leave bad reviews and tell friends to avoid the store. If returns are too high, a store’s reputation and profits both take a hit.
Returns don’t just cost money; they create a lot of waste, too. Shipping items back and forth uses fuel and packaging, which is bad for the environment. Damaged returns that can’t be resold add to landfills. For all these reasons, finding ways to reduce returns is a top goal for online stores.
Despite all this, most stores still don’t have a good way to predict who will return something or why. Some big software companies offer basic analytics, but these tools often look only at past sales or simple patterns. They don’t consider all the details that might lead someone to send something back. For example, they might miss how a heatwave could delay shipping, or how a change in the economy could make people more careful with money.
Retailers want better tools. They want to know, before a sale happens, if a customer is likely to return an item. If they know this, they can give shoppers more information, suggest different products, or make sure the packaging is strong enough to handle bad weather. They can also spot trends, like certain products being returned more often, and fix problems before they get worse.
This is where the patent described in this article comes in. It offers a way to use all kinds of data—about customers, products, traffic, weather, and even the economy—to predict, in real time, how likely it is someone will return a purchase. If the system thinks a return is likely, it can alert the store or even the shopper, giving advice on what to do next. This could mean fewer returns, happier customers, and better profits.
Scientific Rationale and Prior Art
To understand what’s new about this patent, let’s look at how stores have tried to solve the return problem before, and why those methods fall short.
Most older systems rely on simple models. They look at things like how often a certain product is returned, or if a shopper has a history of sending things back. Some use machine learning, but they often limit their data sources to what’s easy to track, like sales records or basic customer info.
For example, a basic system might flag a dress as “high risk” for returns because it often comes back due to sizing issues. Or it might notice that a certain customer sends back 30% of what they buy. But these tools miss a lot. They don’t combine different types of data, like live shipping traffic, weather, or whether the customer just saw a better deal elsewhere. They also don’t adjust well to new trends, like sudden changes in buyer behavior during holidays or economic shifts.
Some systems try to use machine learning to predict returns, but they often use just one model. This can lead to “blind spots,” where the model misses something important or makes the same kinds of errors over and over. The models can also get stuck if the data changes, for example, if people start shopping in new ways because of a special event or a new sale.
A few companies have tried to add more data, like browsing history or reviews, but it’s rare to see a system that brings together static data (like who the shopper is and what they bought) and dynamic data (like current weather, traffic, or the latest economic news). Most don’t use data from live APIs, such as up-to-the-minute road conditions or real-time shopping trends from social media. They also don’t send smart alerts to shoppers or stores at just the right time.
Another limit is how the data is processed. Many systems don’t clean or combine the data well, which can lead to mistakes. If a model gets data in the wrong format or with missing values, it can make bad predictions. And if it uses too many features (columns of data), it can get confused or overfit—meaning it does well on old data but badly on new cases.
This is where ensemble learning comes in. An ensemble isn’t just one model; it’s a group of models working together. Each model might be good at spotting certain patterns. When their answers are combined, the overall prediction is often more accurate and less likely to make the same mistake twice.
In science, ensemble methods are used to boost accuracy and guard against errors. It’s like asking a group of experts for their opinions and then making a decision based on their combined wisdom. Some common models in an ensemble are decision trees (which split data based on rules), logistic regression (which predicts yes/no outcomes), random forests (groups of decision trees), and gradient boosting (which builds models in steps to fix earlier mistakes).
The patent described here takes these ideas further. It doesn’t just use one or two models. It uses several models (the “base classifiers”), each of which looks at the data in its own way. Then, a “meta-classifier” takes the results from all these models and makes a final call. This approach is called stacking. It’s smarter than any single model because it learns from the strengths and weaknesses of each part.
The system also goes beyond the basics by cleaning and preparing the data before making predictions. It uses techniques like scaling numbers so they’re on the same scale (helpful when different features have very different ranges) and turning words into numbers so models can use them. It even uses dimensionality reduction—ways to shrink the number of features down while keeping the important information. This makes the models faster and less likely to get confused.
Finally, the system doesn’t just make predictions and leave it at that. It acts on them. If it thinks a customer might return something before they buy, it can send a message suggesting a better size or a different product. If it sees a risk after the purchase but before delivery, it alerts the retailer, who can change the packaging or reach out to the customer to fix problems before they happen.
In summary, the prior art was limited by not using enough data types, relying on simple models, and not giving actionable advice at the right time. This new approach fixes these problems by using more data, smarter models, and real-time alerts.
Invention Description and Key Innovations
Now, let’s break down what makes this patent’s system special and how it works, step by step.
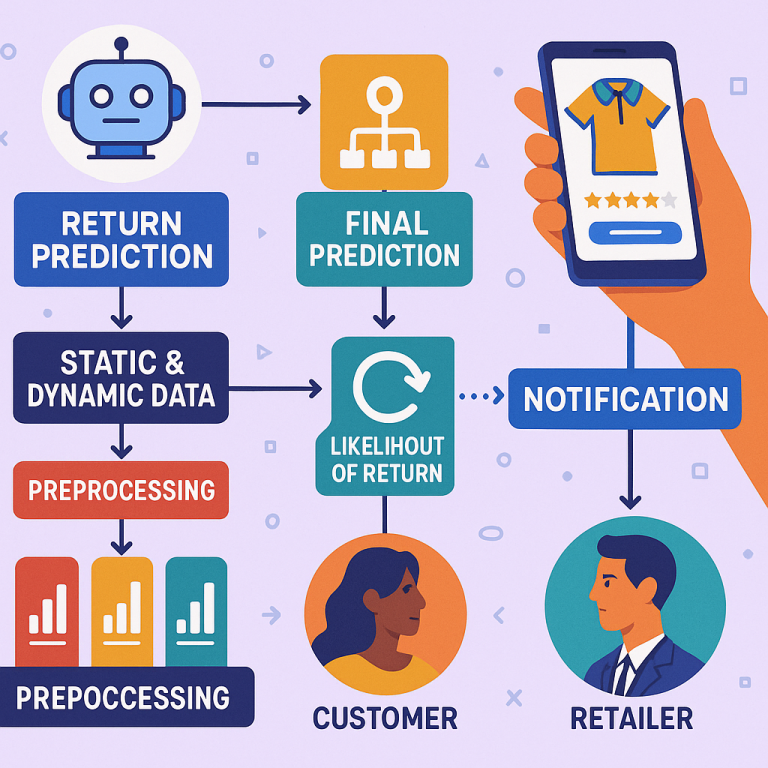
The core idea is a computer system that predicts the chance of a return for every product, for every customer, at multiple stages—before they buy, after they buy but before delivery, and even after delivery. The system gathers data from many sources. Some of this data is “static,” like:
- Who the customer is: age, gender, location, shopping history, and browsing behavior.
- What the product is: size, color, brand, material, pictures, and descriptions.
- Unified ID: ways to link a customer’s actions across devices and platforms.
Other data is “dynamic,” meaning it changes all the time:
- Transaction details: order history, shipping choices, payment methods, and return history.
- Cookie data: what the customer does on the website, like clicks, time spent, or pages viewed.
- Live traffic: road conditions, delivery times, and possible delays on the way to the customer.
- Weather: temperature, rain, snow, or storms that could affect shipping or the product’s condition.
- Macro-economic factors: the state of the economy, like unemployment rates or consumer confidence.
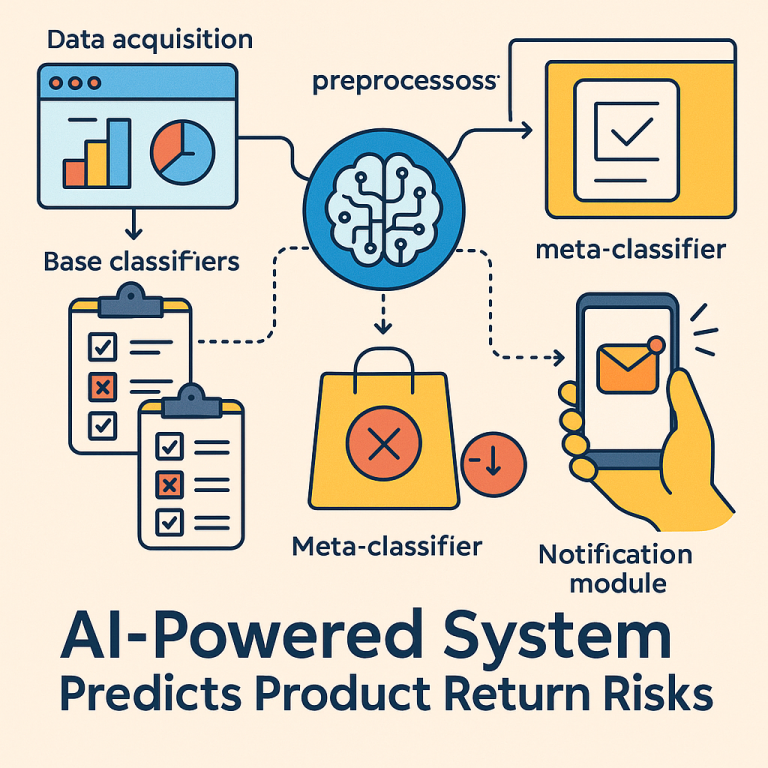
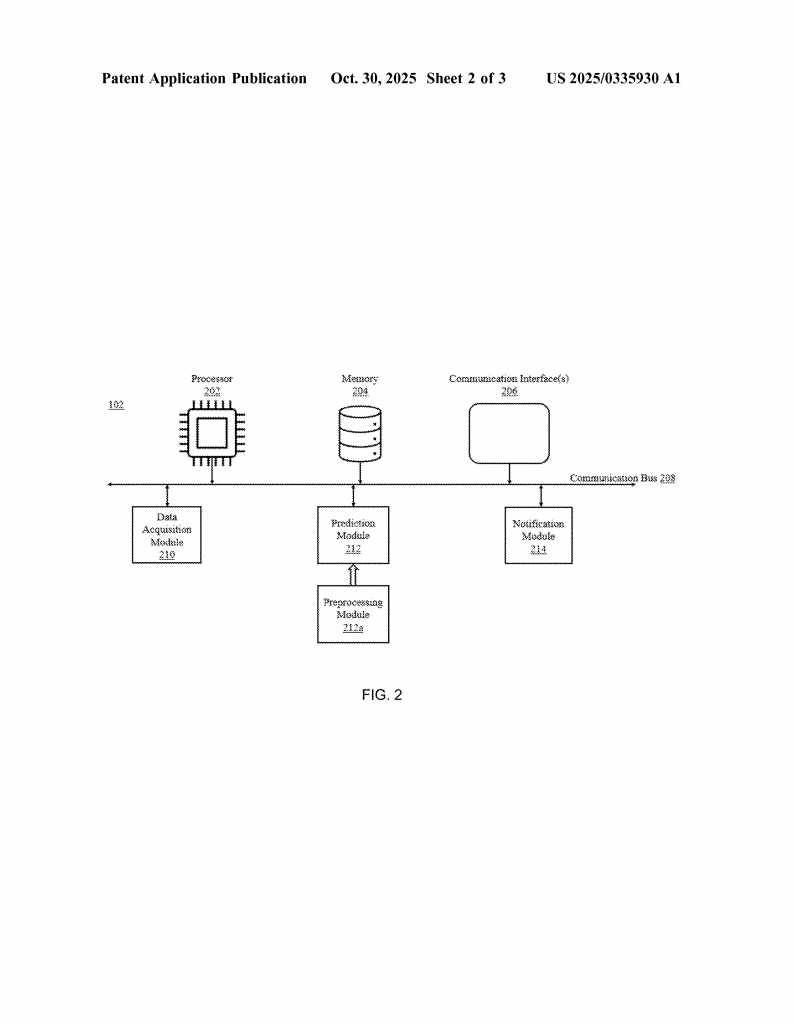
All this data is collected by a “data acquisition module.” This part connects to many sources, including APIs that give real-time updates on traffic and weather. It also respects user privacy, letting customers opt out of certain types of tracking.
Once the data is collected, it goes through a “preprocessing module.” This step cleans up the data, fills in missing values, turns text into numbers, and scales everything so it’s ready for machine learning. If there are too many features, the system uses special math (like Linear Discriminant Analysis or autoencoders) to shrink the data down to its most important parts.
Next comes the “prediction module.” Here’s where the magic happens:
- Several base models (like decision trees, logistic regression, random forests, and gradient boosting) each make their own prediction about whether a product will be returned.
- A meta-classifier takes all these predictions and combines them into one final answer.
- The system learns and improves over time by retraining itself with new data about actual returns.
This isn’t just theory. The system is designed to work in real time. For example:
- Before purchase: If the system predicts a high chance of return, it can alert the customer, suggesting a better size, a more reliable product, or extra details to help them decide.
- After purchase but before delivery: If there’s a risk of return (say, because of bad weather or slow traffic), the system alerts the retailer. The store can then change the shipping method, add extra packaging, or contact the customer to fix any issues.
The system also sends notifications to both customers and retailers. These aren’t just warnings; they include tips on what to do next. For customers, it might suggest double-checking product details or looking at alternatives. For retailers, it might recommend changing shipment timing, using stronger packaging, or reaching out to the customer with helpful info.
The dashboard is another key part. It lets retailers see, at a glance, which products are most likely to be returned, which customers are most at risk, and why. This helps stores spot patterns, improve their listings, and make smarter decisions about stock, pricing, and marketing.
Some unique features include:
- Combining both static and dynamic data for a fuller picture.
- Using multiple models together for better accuracy.
- Real-time integration with live data sources like weather and traffic.
- Automatic retraining, so the system keeps learning and stays up to date.
- Actionable notifications that help both the customer and the store act before a return happens.
The overall process is smart, fast, and practical. It doesn’t just predict returns—it helps everyone do something about them. By using more data, better models, and real-time alerts, this invention could cut down on avoidable returns, save money, and make shopping better for everyone.
Conclusion
Product returns are a big problem for stores and shoppers alike. They waste money, time, and materials. Until now, most solutions have been too simple, looking only at basic data and missing key warning signs. This new invention changes the game by bringing together lots of data, using smart AI models, and sending timely advice to stop returns before they happen. With this system, stores can work smarter, shoppers can make better choices, and everyone wins. The future of retail is not just about selling more, but about making sure every sale sticks.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250335930.

