AI-Driven Platform Accelerates Custom Peptide Design for Targeted Protein Degradation in Drug Discovery
Invented by PALEPU; Kalyan, BHAT; Suhaas, CHATTERJEE; Pranam, UbiquiTx

Peptide drugs are a big hope for treating diseases that traditional medicines can’t reach. A recent patent, known as Cut&CLIP, shows how machine learning can help design new peptides that bind to target proteins, even ones considered “undruggable.” In this blog, we’ll explain what this invention is, why it matters, and how it works, using simple words so everyone can understand.
Background and Market Context
Today, there are many diseases that we struggle to treat with the tools we have. Most drugs are small molecules—tiny chemicals made to fit into a specific spot on a protein and change how it works. But many disease-causing proteins have shapes or features that make it almost impossible for small molecules to stick to them. These are called “undruggable” targets. In fact, only about 2% of all the possible protein-protein interactions in our bodies can be targeted by these drugs.
Scientists have tried other ideas too. Monoclonal antibodies are very precise and good at sticking to proteins, but they can only work outside of cells. They’re too big to get inside. Peptides, on the other hand, are short chains of amino acids—the building blocks of proteins. They’re small enough to slip inside cells and stick to many different kinds of proteins, including some that small molecules and antibodies can’t touch. This makes peptides very useful for treating a wider range of diseases, from cancer to viral infections.
But making new peptides that bind to a specific protein is hard. Traditional methods use big libraries of random peptides and test each one to see if it works. This takes a lot of time and money. Even when we use computer models that need detailed 3D shapes of proteins, it doesn’t always help. Many target proteins are floppy or disordered, so we can’t even get a good 3D shape to work from.
As a result, there is a huge need for faster, cheaper, and more flexible ways to design peptides that can bind to any target protein—even the tricky ones. If we could do this, we could unlock new treatments for many diseases that are currently out of reach.
This is where the Cut&CLIP invention comes in. It uses machine learning—a type of computer program that learns from data—to design peptides just from the sequence of the target protein. This means we don’t need a 3D structure. It makes the process much faster and more accessible to more labs and companies. The market for peptide drugs is already growing rapidly, and a tool like this can help researchers and drug developers move much faster, bringing hope to patients with diseases that have no good treatments today.
Scientific Rationale and Prior Art
Let’s look at how the science behind Cut&CLIP fits into what has been done before, and why this invention is different.
Earlier, scientists tried two main ways to design peptides. The first way is experimental: make huge libraries of random peptides, like in phage display, and test them all to see which ones stick to the target protein. This is slow and expensive. The second way uses computer tools. These tools work if you know exactly what the 3D shapes of both the target and the peptide look like. You can use special programs to try to “dock” the peptide onto the protein, like fitting a key into a lock. But if the protein is floppy or doesn’t have a known structure, this doesn’t work.
Machine learning has changed the game in many fields, including drug discovery. Recent advances in “protein language models” let computers learn patterns from the sequences of millions of natural proteins. These models can capture details about how proteins behave, even if we don’t have a 3D structure. For example, transformer models, like ESM-2, learn to represent each protein sequence as a kind of “embedding”—a special vector that captures lots of information about the protein.
Another idea from the field of computer vision is “contrastive learning.” In simple terms, this is a way for a computer to learn what things go together. For example, the CLIP model from OpenAI learned to match images with their descriptions by training on pairs of images and captions. The model learns to make the embedding of the image and the embedding of the caption close together if they match, and far apart if they don’t.
The inventors of Cut&CLIP realized that this idea could be used for proteins and peptides. If you train a model to make the embedding of a peptide close to the embedding of the target protein when they bind, and far apart when they don’t, you can use this to score new peptides. This is the basis of the contrastive learning approach in this patent.
Previous tools like AlphaFold2 made big progress in predicting the 3D shape of proteins, and even protein complexes. But these methods are slow and need lots of computer power. They also struggle with proteins that don’t have a stable shape. The Cut&CLIP approach skips the need for 3D structures and instead works directly from the sequence, making it much faster, cheaper, and more flexible.
Before this invention, there were some attempts to use protein language models for design, but they mostly focused on predicting if a single peptide could bind a protein, not on generating lots of new peptide candidates or ranking them for experimental testing. The Cut&CLIP approach is new because it combines a language model, contrastive learning, and a streamlined process for cutting known protein partners into peptide candidates, ranking them, and even generating new ones from scratch.
In summary, Cut&CLIP builds on recent advances in machine learning and protein modeling, but it uses these tools in a new way to solve an old problem—how to quickly find peptides that can bind to any protein, even the hard ones.
Invention Description and Key Innovations
Now let’s get into how the Cut&CLIP invention works, what makes it unique, and why it’s a big step forward.
At its core, Cut&CLIP is a process and a system that uses a trained machine learning model to identify short peptides that will stick to a target protein. Here’s how the process goes, step by step, using simple words:
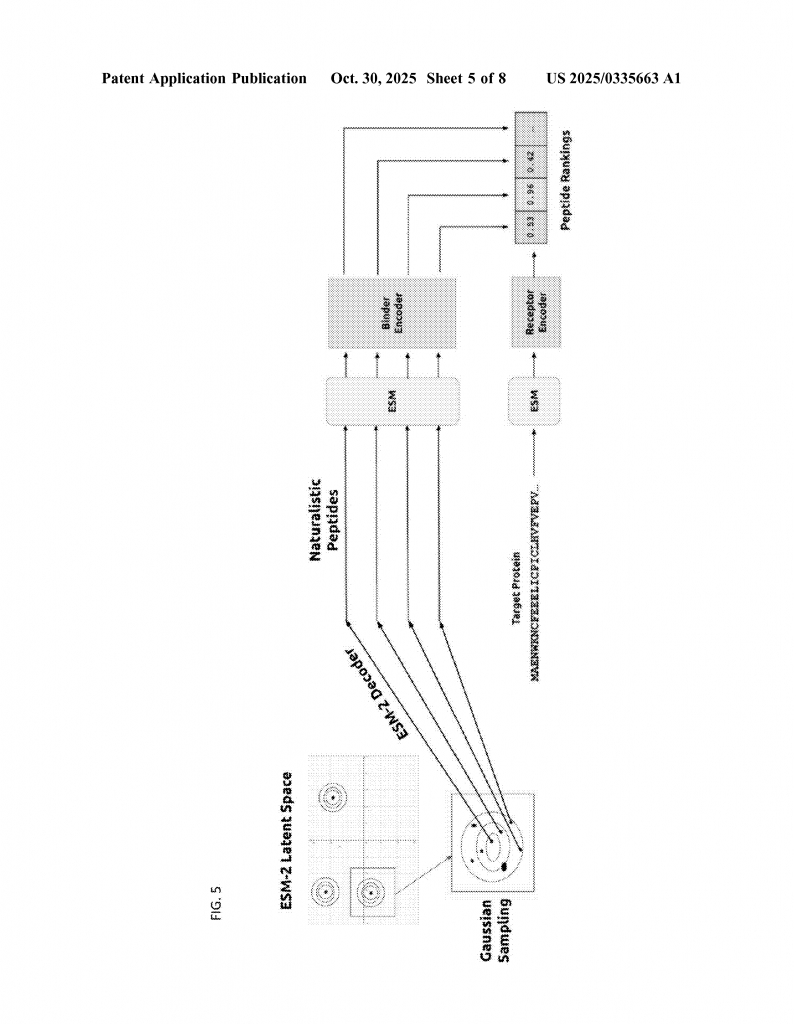
First, the inventors gather lots of data about known protein-peptide pairs—cases where a certain peptide is known to bind to a certain protein. They use powerful protein language models, like ESM-2, to turn the sequence of each protein and peptide into a set of numbers called embeddings. These embeddings capture important features about the sequence.
Then, they train two encoders—one for the protein (called the receptor) and one for the peptide. These encoders are trained together using a contrastive learning approach. The idea is to make the embeddings of pairs that bind have high similarity (close together), and pairs that don’t bind have low similarity (far apart). The similarity is measured by something called “cosine similarity”—a simple way to see how close two sets of numbers are.
The training is done in batches, with lots of known pairs. The model learns to bring together the embeddings of true pairs and push apart the embeddings of non-pairs. This makes the model good at predicting which new peptides are likely to bind to a new target.
Once the model is trained, there are two main ways to use it to find new peptides:
1. Cutting Known Protein Partners (Cut&CLIP):
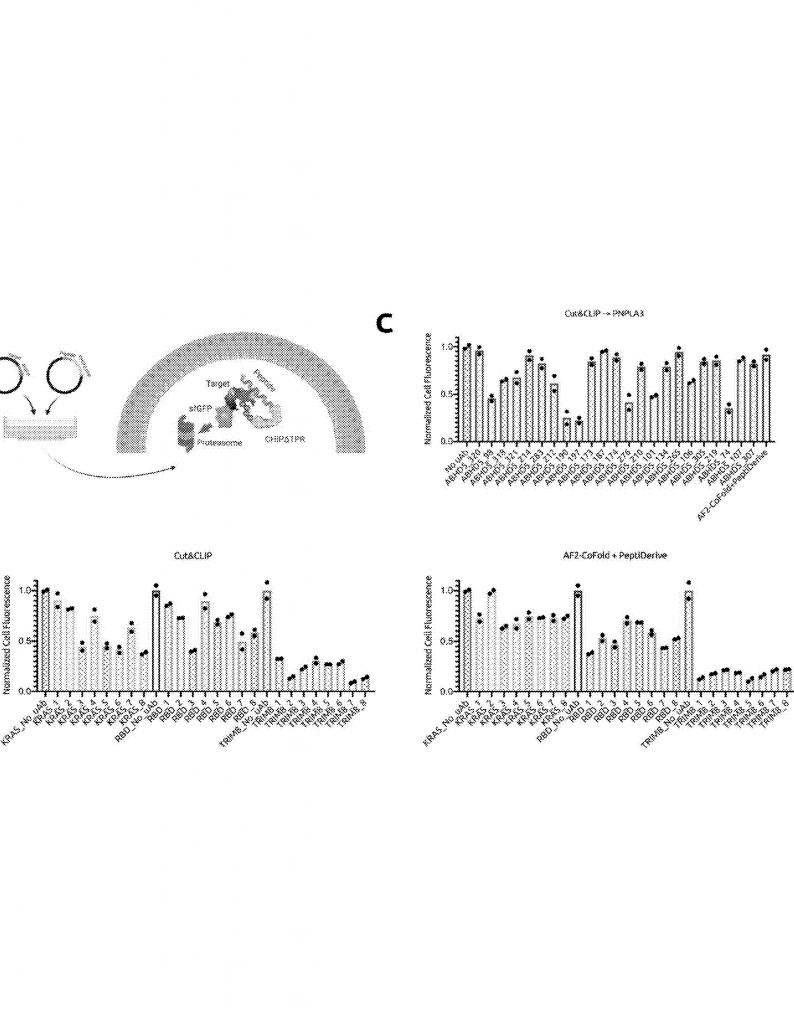
The system looks up known proteins that interact with the target protein in a database. It then “cuts” these known partners into all possible short peptide slices (for example, all possible 10-amino-acid pieces). Each slice is scored by the model to see how likely it is to bind to the target. The best-ranking slices are chosen for further testing.
2. Generating New Peptides from Scratch (De Novo Generation):
Sometimes, there are no known protein partners, or you want to find completely new peptides. Here, the system samples new peptide embeddings from the language model’s latent space, making sure they look like real peptides. Then, it uses the trained model to score these new candidates for binding to the target.
The system can make thousands of peptide candidates quickly and rank them, making it easy to pick the best ones for lab testing.
But the invention doesn’t stop there. The inventors also showed that you can take these top-ranked peptides, fuse them to a part of an enzyme called an E3 ubiquitin ligase, and create a fusion protein called a “ubiquibody” (uAb). These uAbs can enter cells and mark the target protein for destruction. This is a big deal because it lets you destroy disease-causing proteins inside cells, even ones that can’t be reached by traditional drugs.
The inventors tested their system on several tough targets, including the KRAS oncoprotein, which is very important in cancer but is usually considered undruggable. They showed that peptides designed with Cut&CLIP could bind to KRAS and lead to its degradation in cells—a major breakthrough. They also showed the system works much faster and with less computer power than older methods based on 3D structures.
Some other important features in the patent:
– The model can work with just the sequence of the target protein, making it useful for proteins that don’t have a known 3D structure.
– The approach can use multiple sources of data, combining computational and experimental peptide-protein pairs.
– The system is flexible: you can use it to design peptides for any protein, and you can pick candidates for different uses (binding only, or degradation).
– The rankings are clear and easy to use: the closer the model’s score is to +1.00, the more likely the peptide will bind to the target.
The patent also describes how the system can be built using standard computers, how the data is stored, and how the process can be automated from start to finish. This makes it practical for labs or companies without lots of resources.
The invention goes all the way to describing how to make peptide-based drugs using the peptides found by Cut&CLIP, how to deliver them, and how to use them in therapy for diseases like cancer and viral infections.
Conclusion
The Cut&CLIP patent shows a new way to find and design peptides that can bind to any target protein, even the most challenging ones. By using the latest machine learning methods and skipping the need for 3D structures, it makes peptide drug design much faster, cheaper, and open to more researchers. This approach is already proving its value in tough areas like cancer drug discovery and could help bring new treatments to patients who need them the most. If you’re working in drug development, bioinformatics, or biotechnology, learning about this invention—and the tools behind it—could open up new possibilities for your own work.
The world of peptide drug design is changing fast, and inventions like Cut&CLIP are leading the way. Stay tuned, because this technology is just getting started.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250335663.

