Personalized Data Search: AI-Powered Recommendations Transform How Businesses Access Key Information
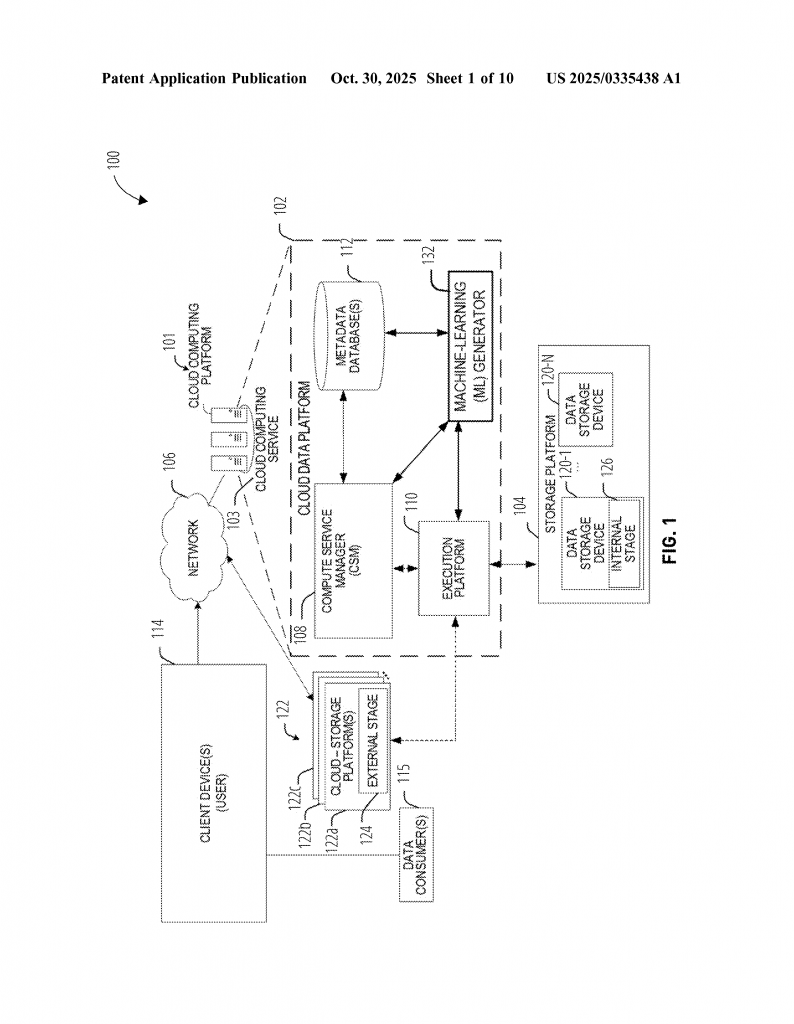
Invented by Ngan; Muhua, So; Chiu Wah, Tarakad; Nitya Kannan

Getting the right data from a cloud platform can sometimes feel like looking for a needle in a haystack. With so much information stored in so many places, it’s easy to get lost. But what if your system could learn what you need, remember how you ask, and help you find the right tables and columns—just by understanding how you search? Today, we’ll walk through a recent patent application that does just that, showing how machine learning and past search history can make your data queries smarter and faster.
Background and Market Context
In today’s digital world, most companies store huge amounts of information in the cloud. These platforms help teams save, manage, and analyze their data. But as helpful as these platforms are, searching for the right data can be tough. People use different words, styles, or even languages to ask for data. Sometimes, they type special commands (like SQL queries); other times, they just use plain English or another language.
Companies have noticed a big problem: traditional systems that recommend which tables or columns to use when searching are not very smart. They mostly look for exact words or simple patterns. This means if someone uses a different name or a slightly different way to ask a question, the system might not find the right data. As data grows and teams get bigger, this problem only gets worse.
Why does this matter so much? Every time a user struggles to find data, it slows down work, lowers productivity, and can even lead to costly mistakes. For businesses, that means wasted time and missed chances. For users, it means frustration and confusion.
That’s why smarter search is needed. If a platform could remember how each person searches, learn their favorite words, and help guide them to the right data—even when they ask in new ways—it would save time and make everyone’s job easier. This is exactly the gap this new patent application aims to fill.
The solution uses advanced computing and machine learning to help the system “understand” what each user really wants, not just what they type. It keeps track of past searches, learns each person’s style and preferences, and uses this knowledge to make better recommendations. This isn’t just helpful for experts—it’s also great for anyone who isn’t a database pro, allowing them to use natural language and still get the right answers. In a world where more people need to use data, but not everyone knows technical language, this kind of system can be a game-changer.

In short, as more companies move to cloud platforms and as data keeps growing, the need for smart, user-friendly search is bigger than ever. Businesses want solutions that save time, reduce errors, and help everyone—from the IT expert to the business manager—get the data they need, when they need it.
Scientific Rationale and Prior Art
Traditional data platforms use simple matching to help users find tables or columns. For example, if you search for “sales,” the system looks for any table or column named “sales.” This approach is basic and doesn’t account for how people actually work. Users may use nicknames, abbreviations, or even new words when searching for the same thing. If you call something “revenue” today and “income” tomorrow, simple systems see them as different, even if you mean the same thing.
Previous systems tried to improve by adding more rules or allowing for some synonyms, but they still fell short. They did not pay attention to how each user works over time. For example, they did not learn that you, as a user, often join certain tables together or filter data in a specific way. They could not adapt to your personal habits, or to the way your team prefers to look at data.
The field of information retrieval has seen many advances, especially with natural language processing (NLP) and machine learning. Recent systems use large language models to understand spoken or written language better. Some tools can even translate plain English into SQL queries. But even these systems often work in a general way and don’t get smarter as you use them. They can’t pick up on your habits, the words you use, or the mistakes you make often. Also, most of the prior art does not use a user’s search history to make the system better for that user.
Another problem with old systems is that they can’t handle the scale of today’s cloud data. As businesses grow, users may have thousands of tables and millions of columns. Old matching systems become slow or overwhelmed. They also can’t learn from feedback—if you choose a table from their list, the system doesn’t use that choice to improve future recommendations.
In summary, before this new invention, systems were either too simple (using only keyword matching), too general (not learning from each user), or too slow (not scaling to big data). They didn’t combine user history, language understanding, and smart recommendations in one solution. There was a clear need for a system that could:
– Learn from each user’s past searches.
– Understand both technical and plain language queries.
– Use machine learning to make smarter, more personal recommendations.
– Scale to handle big data while staying fast.
This patent application builds on these scientific advances, using machine learning in a new way to solve these real-world problems.
Invention Description and Key Innovations
This invention is a computer system that makes searching for data in the cloud much easier and smarter. Here’s how it works in simple terms:
First, the system watches how each user searches for data over time. It looks at all the questions (queries) you type, whether you use technical language (like SQL) or just plain English. This search history is stored and analyzed.
The system uses two special machine learning models:
1. The first model looks at your past searches and learns your unique style. It finds patterns, like which tables you use most, any nicknames you use for tables or columns, and how you join different tables together. It even notices if you use certain filters or “where” clauses a lot.
2. The second model is used when you enter a new search. It reads your new question—no matter how you write it—and turns it into a special set of numbers called embeddings. These embeddings capture the meaning and intent behind your words, not just the words themselves.

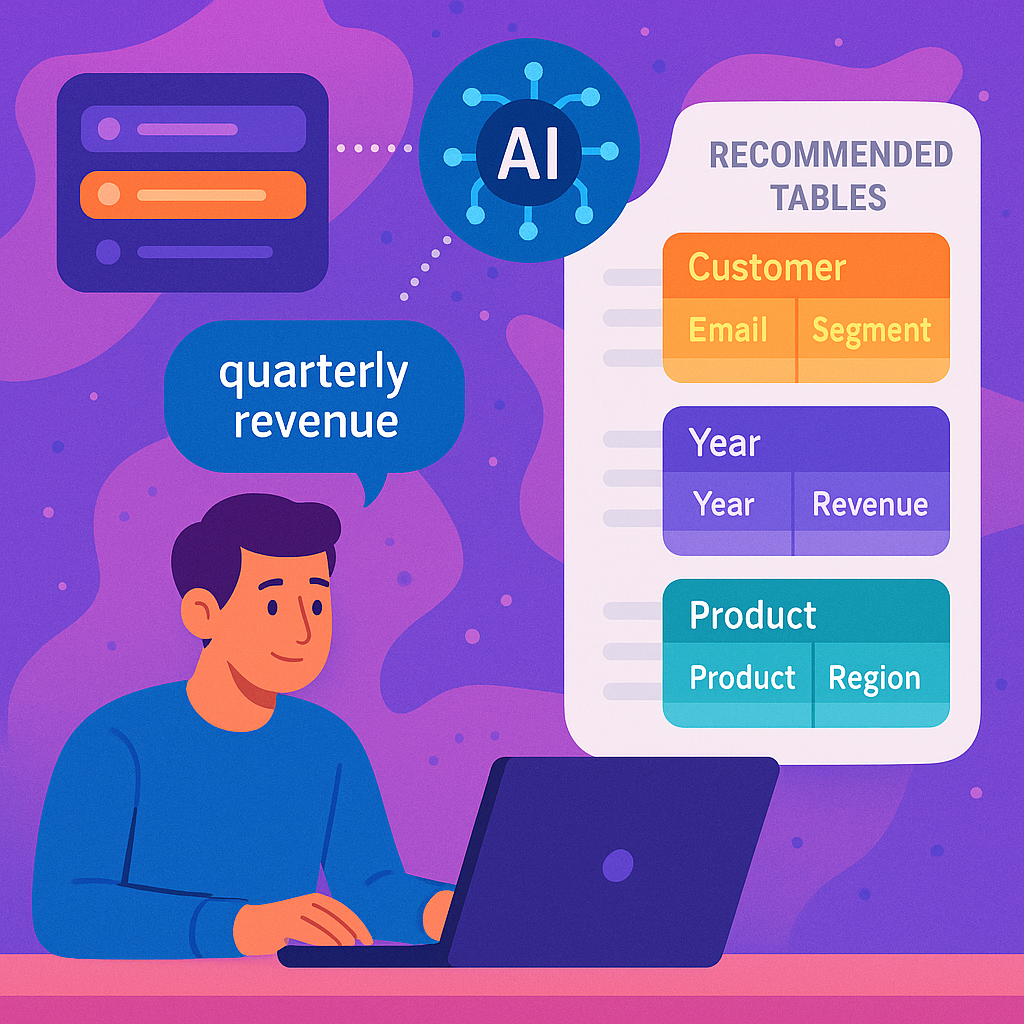
With your search history now “enriching” the database, the system uses these embeddings to look for the best matches. It doesn’t just look for exact matches but also considers your personal habits, your favorite terms, and the way you usually ask questions. This way, if you write “Show me last month’s earnings,” the system knows you really want the “sales” table and the “revenue” column, because it learned that from your past behavior.
Key features of the invention include:
– Learning naming habits: If you call a table “CA customers” one day and “XP California customers” the next, the system learns both mean the same thing for you.
– Tracking usage: It remembers which tables and columns you use most, so they show up higher in the recommendations.
– Understanding joins: If your searches often combine certain tables, the system learns to suggest those joins.
– Adapting to filters: It picks up on your favorite filters or conditions, like always filtering by “last month” or “active customers.”
– Handling both SQL and natural language: Whether you use technical commands or just type in a question, the system understands both.
– Improving over time: Each time you search, the system gets smarter by learning from your behavior and feedback.
The process works like this:
– The system first gathers your search history and cleans it up, removing duplicate or messy entries.
– It uses the first model to find out your naming patterns, aliases, and typical ways of joining tables or filtering data.
– It updates the database with this information, so it “remembers” your style.
– When you type a new search, the second model turns your query into embeddings.
– The system compares these embeddings to the enriched database, looking for the best tables and columns that match what you want.
– It then shows you a ranked list of recommended tables and columns—tailored just for you.
– You pick what you need, and the cycle continues, with the system learning more each time.
The invention also uses advanced models called bi-encoders and cross-encoders. The bi-encoder creates embeddings for both your query and all possible tables and columns. It compares them quickly to find matches. The cross-encoder then takes these matches and gives them a relevance score, so the most likely answers show up first. If you keep picking certain results, the system learns to rank those even higher.
Another key innovation is the way the system handles both structured (like SQL) and unstructured (like plain English) searches. It can even learn from your corrections or feedback, so if it gets something wrong and you pick a different table, it adjusts its recommendations for next time.
All of this works in real time and can handle huge amounts of data, making it suitable for large companies with many users and massive databases. The system can run on any computer or cloud platform and can be scaled up as needed.
Overall, this invention makes searching for data in the cloud as easy as searching the web. It learns from you, adapts to your needs, and gets better the more you use it.
Conclusion
In a world where data is everywhere but time is scarce, finding what you need, when you need it, is more important than ever. This patent application turns the challenge of searching for the right data into a smart, personal, and seamless experience. By combining user history, language understanding, and machine learning, it closes the gap left by older systems and opens the door to a new way of working with data.
Whether you’re a business analyst, a data scientist, or someone who just wants answers fast, this invention can help you work smarter, not harder. As cloud platforms keep growing and more people need to access data without being technical experts, solutions like this will become the new standard. With this advanced system, the future of data search is not just easier—it’s personal, adaptive, and always improving.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250335438.

