Efficient AI Language Model Training Reduces Costs for Scalable Chatbots and Voice Applications

Invented by OH; Jonghoon, ASAO; Yoshihiko, TORISAWA; Kentaro, MIZUNO; Junta, OTAKE; Kiyonori, National Institute of Information and Communications Technology

Today’s smart devices talk with us, listen to us, and try to understand us. But even the best computers can get confused when they hear words that sound the same. This blog will help you understand a new patent application about a clever way to train language models to be much better at handling speech mistakes. We will walk you through why this is important, how it relates to other ideas out there, and what makes this invention special.
Background and Market Context
Imagine talking to your phone or a robot at home. You ask for the weather, or maybe you want to set a timer. The device listens, tries to figure out what you said, and answers you. But sometimes, it gets things wrong. Maybe you said “umbrella,” but it heard “gorilla.” This kind of mix-up happens because some words sound alike, and speech recognition is not perfect. When this happens, your device might answer the wrong question or do the wrong thing.
This is more than just a small problem. As more people use voice assistants, smart speakers, and robots, we need these devices to understand us better. In healthcare, older adults might use a talking robot for daily check-ins. In customer service, voice bots help answer questions. Even in cars, drivers use voice commands to stay safe without touching buttons. When these systems fail to understand, it can be frustrating or even dangerous.
To help computers understand us, companies use language models. These are programs trained on lots and lots of text. They learn how words fit together and what they mean. Recently, models like BERT have become very popular because they can read huge amounts of text and learn to answer questions, translate languages, and do many other jobs. But these models often only use written words. They are not very good at dealing with mistakes that happen when speech is turned into text. So, when the speech recognizer (the part that listens) makes a little mistake, the language model (the part that understands) gets confused.

To fix this, some researchers have tried training language models with data that comes from speech, including the kinds of mistakes that happen during speech recognition. But this is very hard and expensive. It takes a lot of computer power to turn text into speech, add fake noise, turn it back into text, and then train the model on all of that. If you want to train a big model like BERT, you need billions of sentences. Doing all that speech processing for so much data is just too slow and too costly for most companies.
So, the market needs a way to train language models that can handle mistakes—from speech recognition—without needing all the extra work and computer time. A solution that can use regular text, but still help language models learn to deal with the kinds of errors that happen when people talk, would be a big step forward.
Scientific Rationale and Prior Art
To understand this invention, let’s look at how people have tried to solve this problem before. The main idea is to make language models that are strong, or “robust,” against errors in speech recognition. When you say something, a computer turns your speech into text. But this process is not perfect. Sometimes, the computer hears a word wrong, or it picks a word that sounds similar but has a different meaning.
A popular idea from past research is to train language models not just on plain text, but also on the kind of messy text that comes from speech recognition systems. For example, one method called “Phoneme-BERT” converts text into speech using a speech synthesizer, then adds noise (like a busy room or a crackling microphone), and finally turns the noisy speech back into text using a speech recognizer. This creates text with the same kinds of mistakes real speech recognition systems make. The language model is then trained on this noisy text along with the regular text.
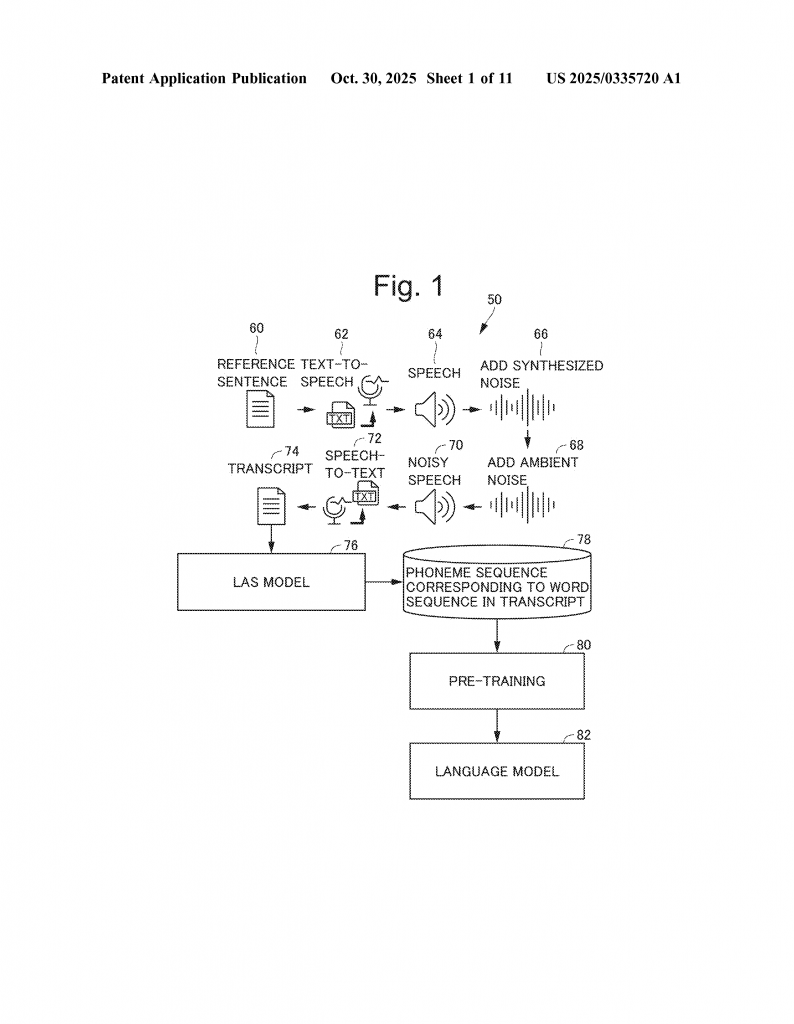
While this idea helps the model learn to understand even when there are errors, it has some big problems. First, making all this data is very slow and expensive. You need a speech synthesizer to turn text into audio, you need to add fake noise, and then you need a speech recognizer to turn the noisy audio back into text. Doing this for billions of sentences takes a lot of time and computer power.
Second, the models made this way depend on the specific speech synthesizer and speech recognizer used. If you change these tools later, the language model may not work as well and might need to be trained all over again. This makes it hard to keep up with new and better speech tools as they come out.
There have been other ideas too. Some tried to add noise directly to the text or use rules to change words to ones that sound similar. But these methods often lack the detail needed to match real-world speech mistakes. Also, most language models only use the words in text, not how they sound. But in languages like Japanese, how a word sounds is very important, because many words look different but sound similar (like “hasami” for “scissors” and “kasami” for “umbrella”).
So, the need is clear: a method that can train language models to deal with errors, without needing all the hard work of speech synthesis and recognition, and that still captures the way words sound so the model can better handle mistakes from speech.
Invention Description and Key Innovations
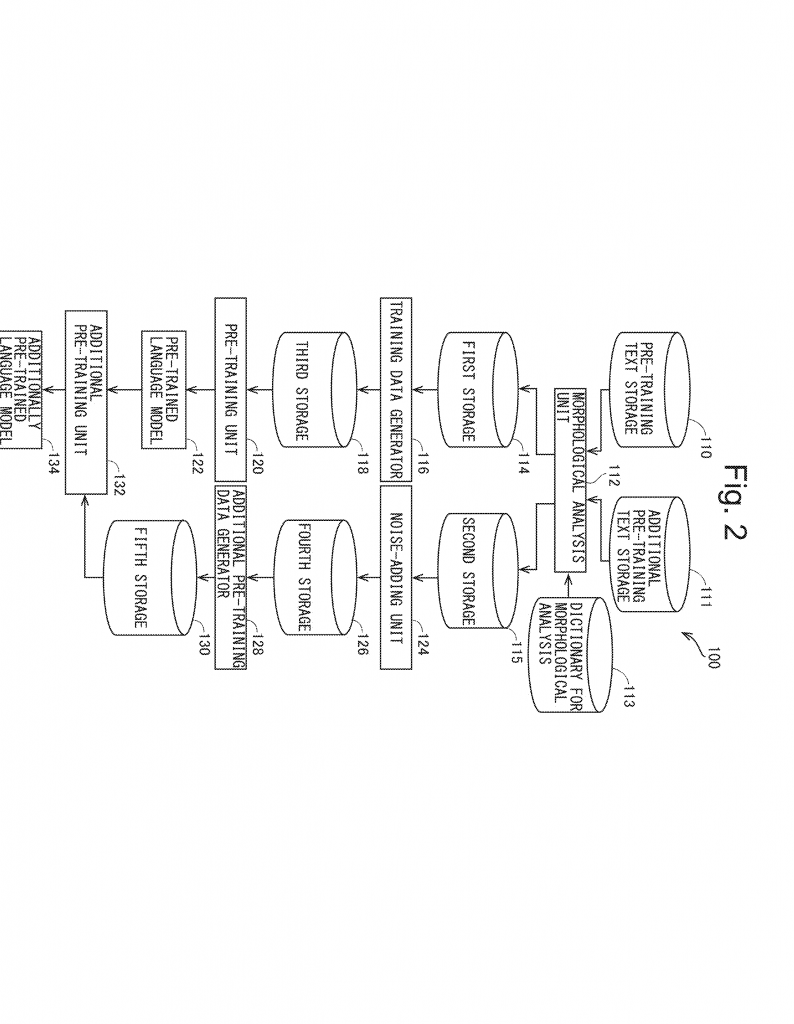
This new patent solves the problems above in a clever, simple way. It introduces a language model training device that uses text and their “phonetic letters”—basically, a way to write how the words sound—to help the model learn about speech errors, all without needing speech synthesizers or recognizers.
Here’s how it works. First, you start with regular text sentences. The system uses a tool (called a morphological analyzer) to break each sentence into words and convert each word into its phonetic spelling. In Japanese, this might mean turning written words into “hiragana,” a system for writing sounds. So, each sentence now has two parts: the word itself and how it sounds.
Next, the model combines the text and the phonetic letters into a special training sample. Sometimes, the model masks (hides) some of the words or their phonetic forms and tries to guess them, just like the popular BERT model does for regular text. This helps the model learn the link between how words are written and how they sound.
But the smart part comes when the system adds “noise” to the phonetic letters. Instead of going through the slow process of turning text into speech, adding audio noise, and turning it back into text, the system simply changes some of the phonetic letters to those of different words that sound similar. For example, it might change the phonetic spelling of “morning” (asa) to “umbrella” (kasa) in Japanese, which sound almost the same. It can pick these replacement words by looking for words that have a very similar phonetic spelling, measured by something called “edit distance” (how many changes you need to go from one word to another).
This fake noise mimics the kinds of mistakes real speech recognizers make, but it’s much faster and doesn’t require any speech processing. The system can control how much noise to add, and it can pick which words to change at random or by some rule. This makes the training data look a lot like the kind of text you get from speech recognition, with realistic mistakes.
The model is trained in two main steps. First, it is pre-trained on regular text and their phonetic forms. Then, it is “additionally trained” or “fine-tuned” on the noisy data, so it learns to handle errors. You can use this model for any language, as long as you have a way to turn words into how they sound, like using phonetic alphabets or pronunciation dictionaries.
The patent also covers using this model in a dialogue device. The device listens to a user’s speech, recognizes what was said, converts it into text and phonetic letters, and then uses the trained model to understand the meaning, even if there are mistakes. For example, a robot talking to an elderly person can still understand what is being said, even if the speech recognizer mixes up words that sound alike.
This approach is very efficient. It only needs text data, not audio, so it saves a huge amount of computer time and cost. It does not depend on which speech recognizer or synthesizer you use, so you can upgrade your tools without retraining the model. The system is flexible and works for different tasks, like answering yes/no questions, extracting keywords, or having casual chats.
Tests in the patent show that models trained this way are much better at handling noisy, speech-like data. Even when a lot of noise is added, the models still perform well, showing they are robust and reliable.
Conclusion
This new way of training language models is a big step forward for speech dialogue systems. By using regular text and turning it into phonetic letters, then adding realistic noise, the system teaches language models to handle the kinds of errors that happen in real conversations. It does this without the need for slow, costly speech processing. The invention is practical, fast, and works in any language with a phonetic writing system. With this approach, voice assistants, robots, and other smart devices can understand us better, even when speech recognition is not perfect. This makes human-machine conversations smoother, safer, and more reliable for everyone.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250335720.

