ADAPTIVE ENCODING OF IMAGE REGIONS FOR MACHINE LEARNING AND AI APPLICATIONS
Invented by Rathi; Swapnil, Nikam; Prasad Prakash, Jagadish Ramalad; Chandrahas, Rupde; Bhushan, Gaikwad; Prashant, Purandare; Kaustubh
This article will help you understand an important new patent application that could change how machines process images for artificial intelligence and machine learning. We will break down what this invention does, why it matters, and how it fits into what came before. By the end, you’ll see how smart image encoding could help make machines—from self-driving cars to cloud servers—much better at seeing and understanding the world.
Background and Market Context
Machines are getting smarter every year. They learn to see, hear, and make decisions a lot like people do. But for a machine to “see,” it needs to process pictures or video. This happens in cars that drive themselves, robots in factories, and even your phone when it unlocks using your face. All these smart systems rely on cameras and sensors that send a flood of pictures or video data to a computer. The computer then uses machine learning models (MLMs) to figure out what’s in those images.
Here’s the problem: Sending and processing high-quality pictures or video takes up a lot of room and speed—both in the computer’s memory and in the network bandwidth. If you make every picture super clear, you need more space to store it and more power to process it. This can slow things down or cost more money in bigger servers. But if you make the images too blurry, the machine might miss something important—like a stop sign, a person, or a face.
The world needs a way to keep the important parts of a picture clear, while saving space and speed on the rest. That way, machines can work faster and smarter, without needing super expensive hardware or huge amounts of storage. This is true for self-driving cars, which have to make quick decisions in real time. It’s also true for cloud services processing thousands of pictures at once, or edge devices like security cameras that can’t store everything in high quality.
As machine learning keeps growing, companies want to make sure their systems are both smart and efficient. The market is pushing for solutions that help machines focus on what matters in an image—like a face, a license plate, or an object—without wasting resources. This is where the idea of “adaptive encoding” comes in, and why it’s so valuable.
Adaptive encoding means adjusting how sharp or detailed each part of a picture is, depending on what’s important for the machine’s task. For example, a car’s computer might need a super-clear view of a pedestrian’s face but can get by with a blurrier image of the sky. If this can be done automatically and in real time, it can save a lot of space, lower costs, and help machines make better decisions. This patent application aims to do just that.
Scientific Rationale and Prior Art
Let’s look at how machines have handled this problem before, and why this new idea is different.
Until now, the common way to make sure machines get good information from images has been to increase the quality of every picture or video frame. This means higher resolution (more pixels) or a higher bitrate (more data per second). But that creates a trade-off: more detail means more storage and more processing time. Sometimes, the important detail is only in a small part of the image. For instance, if you’re trying to see a person’s eyes for gaze tracking, that’s a tiny region in a big picture. Making the whole picture super clear just to get that detail is wasteful.
Some systems have used “Region of Interest” (ROI) encoding, where parts of the image believed to be important are saved in higher quality. For example, video conferencing software might keep faces sharp but blur the background. But these systems usually rely on simple rules or manual settings, not on smart, real-time decisions made by machine learning outputs. They don’t always adapt as the task changes, or as the objects in the scene move around.
Other attempts have used fixed pipelines, where each step in the machine learning process is separate. If one model finds a face, the next model might look for eyes. But the way the image is encoded doesn’t change based on what the models find in each frame. The encoding quality is not linked to what the machine actually needs at each step.
This is where the new invention stands apart. It ties the encoding of each image region directly to what the machine learning models find and need. The system checks which parts of the image are important for the next machine learning step, and then changes the quality settings for those regions only. It can do this over and over, frame by frame, as the scene changes. This lets the machine keep the important details sharp, without wasting resources on background areas.
Another difference is that the system can use performance feedback. If the machine learning model is struggling to recognize something in a region, the system can boost the quality there. If it’s doing fine, the system can lower the quality and save space. This feedback loop makes the system smarter over time, always aiming for the best balance between speed, cost, and accuracy.
The scientific idea here is simple but powerful: let the machine itself decide where it needs more detail, based on what it’s trying to do right now. This is a shift from fixed settings or simple rules, to adaptive, model-driven decisions. It’s a big step forward for efficient, intelligent image processing.
Invention Description and Key Innovations
Now, let’s get into how this invention works and what makes it special.
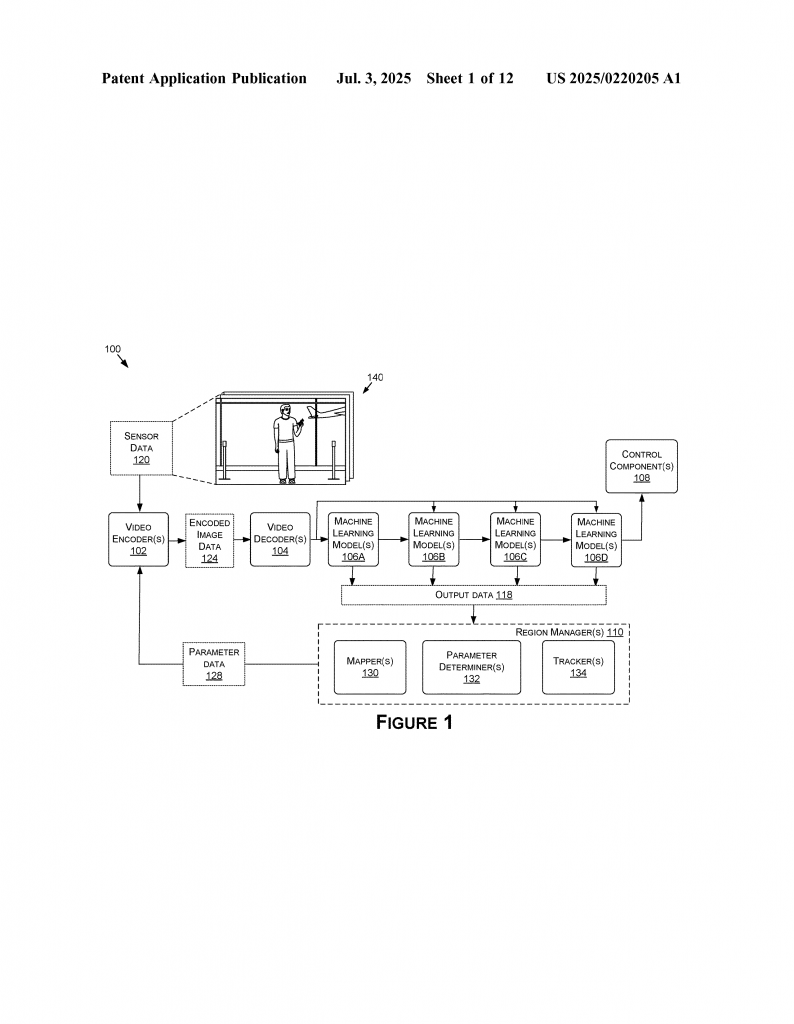
At the heart of this invention is a method that changes how pictures or video frames are encoded, based on what machine learning models (MLMs) find in those images. Here’s how it works, step by step:
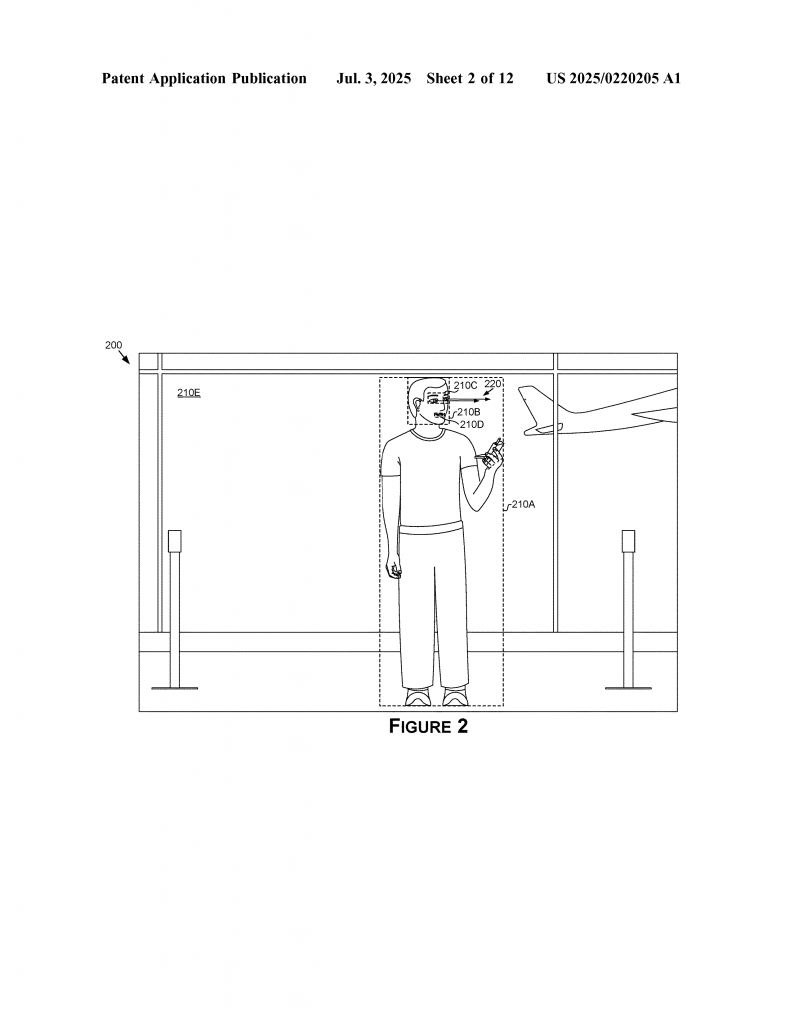
First, the system uses one or more machine learning models to look at a picture or video frame. These models might be looking for objects—like people, faces, cars, or other things. The output from these models tells the system which parts of the image are important. For example, a face detection model might say, “this box is a face.”
Next, the system figures out the properties of these important regions. Properties can mean the size, location, or even how important that region is for the next machine learning step. This could also include the type of object found, its movement, or how hard it is for the model to recognize it.
With this information, the system decides on encoding settings for each region. Encoding settings control how sharp or detailed the region is saved. Key settings might include:
- Quantization parameters: These control how finely the image data is saved. Lower numbers mean more detail.
- Bitrate: How much data is used for that region.
- Resolution: How many pixels are used for that part of the image.
Importantly, the system can set higher quality for regions that are small but very important (like eyes or faces), and lower quality for bigger or less important areas (like the sky or ground).
After setting these encoding choices, the system encodes the image. When it needs to process the image again—say, for the next step in a machine learning pipeline—it decodes the image. The models look again, possibly finding new or changed regions of interest. The system repeats the process, always adapting the encoding to what the models need now.
A key piece of the invention is that it works in a loop. The system can measure how well the models are performing on each region. If the model’s accuracy drops for a certain part of the image, the system can increase the quality next time. If accuracy is high, it can lower the quality and save resources. This feedback helps keep the machine’s decisions both smart and efficient.
Another smart feature is ranking. If there are several important regions, the system can rank them based on size, importance, or how hard the model is working to recognize them. It can then choose to spend more resources on the highest-ranked areas.
This system can be used in many places. In self-driving cars, it helps computers focus on faces, road signs, or other cars, making sure these key areas are always clear—even if the rest of the picture is less detailed. In cloud computing, it helps process thousands of images faster, keeping only the crucial parts sharp. In edge devices like security cameras, it saves storage and makes real-time decisions possible.
Let’s see how this might look in practice. Imagine a video feed from a car’s camera. The first model finds a person in the scene. The next model focuses on their face. The next model looks at the eyes to figure out where the person is looking. Each time, the region of interest gets smaller. The system encodes each of these smaller regions in higher detail, so the final gaze estimation model has all the data it needs. The rest of the image is saved in lower quality or even skipped, saving bandwidth and processing power.
The invention also handles technical details, like mapping regions to the correct parts of the encoded frame (macroblocks), working with different video formats (like H.264 or AV1), and integrating with many types of machine learning pipelines. It can work with cameras, robots, cloud servers, and almost any device that processes images with machine learning.
What makes this invention truly innovative is that it puts the machine learning models in the driver’s seat. The models themselves help decide what parts of the image need more attention, and the system responds in real time. This creates a smarter, more responsive, and more efficient way to process images—one that can adapt to changing scenes, tasks, and machine learning needs.
Conclusion
The adaptive encoding system described in this patent application is a big leap forward for machine learning and artificial intelligence. By linking image encoding directly to what machine learning models find and need, it makes machines much more efficient. It saves space, lowers costs, and helps computers make better decisions, whether in self-driving cars, smart cameras, or powerful cloud servers.
This new method moves beyond simple rules or fixed settings. It lets machines focus their resources where they matter most, adapting in real time as the scene or task changes. This not only improves performance but also opens the door to new applications where speed and efficiency are critical.
As more devices use machine learning to see and understand the world, adaptive encoding will become even more important. This invention sets the stage for smarter, faster, and more capable machines—machines that can process images just like we do: focusing their attention where it matters, and not wasting effort on the rest.
If your business or research depends on processing images for machine learning, adaptive encoding could be the key to unlocking higher performance and lower costs. As this technology matures, expect to see it become a standard part of smart, efficient computer vision systems everywhere.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250220205.

