METHOD AND APPARATUS WITH TILE-BASED IMAGE RENDERING
Invented by KANG; Seok, SAMSUNG ELECTRONICS CO., LTD.
Today, we are exploring a new way to make computer images faster and better. This method uses both smart computers (neural networks) and classic shading in small pieces called “tiles.” This mix promises less work for computers and prettier pictures for everyone.
Background and Market Context
To understand why this invention matters, let’s first look at how pictures are made on computers today. Every time you play a video game or watch a movie on your device, what you see is made up of lots of little dots called pixels. Making each pixel look right takes a lot of computer power, especially when you want sharp, colorful, and smooth images.
Modern computers use special chips called GPUs (graphics processing units) to do this work. Over time, GPUs have gotten bigger and more powerful. They can now handle millions of pixels at once. But as screens get bigger and games get fancier, even the best GPUs struggle to keep up without using a lot of electricity or getting too hot.
The market for faster and better image rendering is huge. Video games, movies, virtual reality (VR), and even phones and tablets all need to show images quickly and clearly. People want smooth experiences, but they also want their devices to last longer and use less energy. This is especially important for portable gadgets that run on batteries.
To make rendering faster, some companies try to split the job into smaller parts and process them separately. Others use clever tricks to guess what pixels should look like instead of calculating each one from scratch. These tricks help, but they can sometimes make images look blurry or wrong, especially at the edges where two objects meet.
Another big push in the market is artificial intelligence (AI). AI can learn to make pictures look sharper and more real, even when starting with a blurry image. AI is now being used to make games run faster without losing quality, but it often needs a lot of training and can be hard to use in real time.
This invention brings together the best of both worlds: it uses the tried-and-true shading that GPUs are good at for important parts of the image and lets neural networks fill in the rest. This means you get great quality where it matters most, and the computer does less work overall. For the market, this means better images, quicker response times, and lower energy use—all things that users, game makers, and device companies are looking for.
Scientific Rationale and Prior Art
Let’s break down why this new method works and what has been tried before.
First, what is “shading”? In computer graphics, shading means figuring out what color each pixel should be. This depends on light, shadows, and what is in the scene. Traditional shading is very accurate but can be slow, especially for lots of pixels. So, most systems only do full shading for every pixel when they really need the best quality, like at the edge of objects or where lights change quickly.
Now, what is “super-sampling”? Super-sampling is a trick to make images look less jagged. Normally, computers guess what color a pixel should be, but this can make straight lines look like stairs. Super-sampling means making the image bigger, doing all the calculations, and then shrinking it down. This helps smooth things out, but it takes even more work.
Recently, neural networks, especially convolutional neural networks (CNNs), have become very good at “upscaling” images. That means they can take a blurry or small image and guess what it would look like if it were bigger and sharper. This is a form of AI super-sampling. These networks are trained on many examples and learn what real images look like, so they can fill in missing details very well.
But there are problems. First, CNNs often shrink the image a tiny bit each time they process it, because of the way they work. To fix this, developers add “padding” around the image, but this padding isn’t real data. When the network tries to fill in pixels near the edge, it doesn’t know what should go there. This makes the edges look wrong or blurry.
To get around this, some older methods use not only the tile (the small piece of the image being worked on) but also some of the tiles around it. That way, the network has more real data at the edges. But this means waiting for the other tiles to be finished, which slows down the whole process.
Another issue is that AI upscaling is usually done after all the classic shading is complete. This means either the GPU does all the work first, or the AI waits until everything is ready. This doesn’t save as much power or time as it could, and it can still lead to blurry or mismatched edges.
Some attempts have divided the image into tiles so each can be processed on its own. While this helps with memory (since each tile is small), it doesn’t solve the edge problem. The AI still has trouble at the borders, and waiting for neighbors means using more memory and slowing things down.
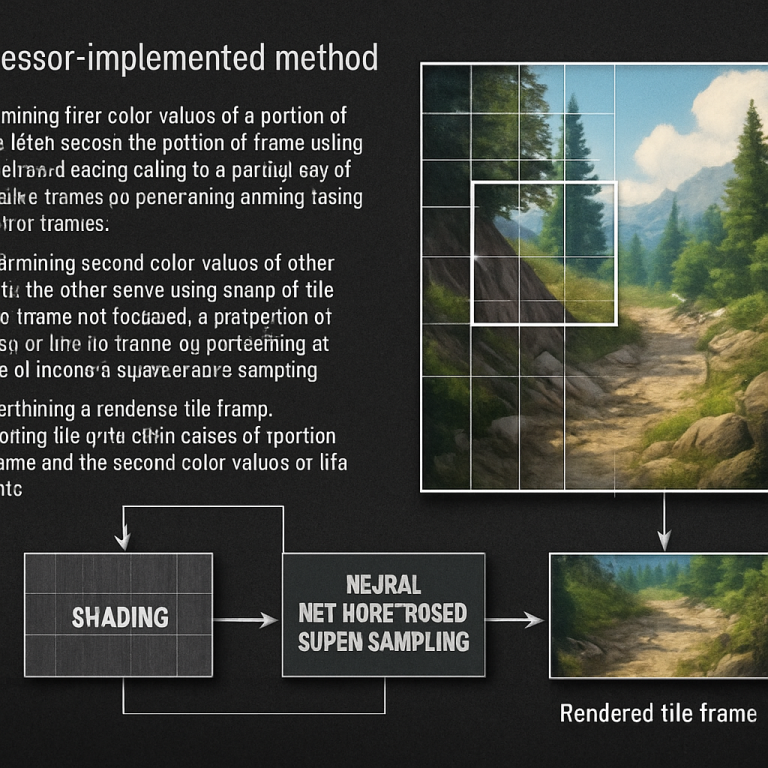
This invention tackles these problems in a new way. It shades the most important pixels (the edges) with the full GPU process and uses the neural network only where it can do the best job—inside the tile, away from the edges. This means the AI gets all the real data it needs for the inside, and the tricky edge pixels are handled by classic, reliable shading.
With this smart mix, each tile can be processed separately, without waiting for other tiles. There is no need to fetch data from neighbors, so memory and power use go down. The result: sharp edges, smooth interiors, and a fast, efficient process.
So, the main difference from older art is this clever split: use shading where it matters most (edges), and let neural networks do the rest, but only inside each tile. This avoids the known problems of padding and neighbor-dependency, making the process both simple and powerful.
Invention Description and Key Innovations
Let’s get into the details of how this invention works and what makes it special.
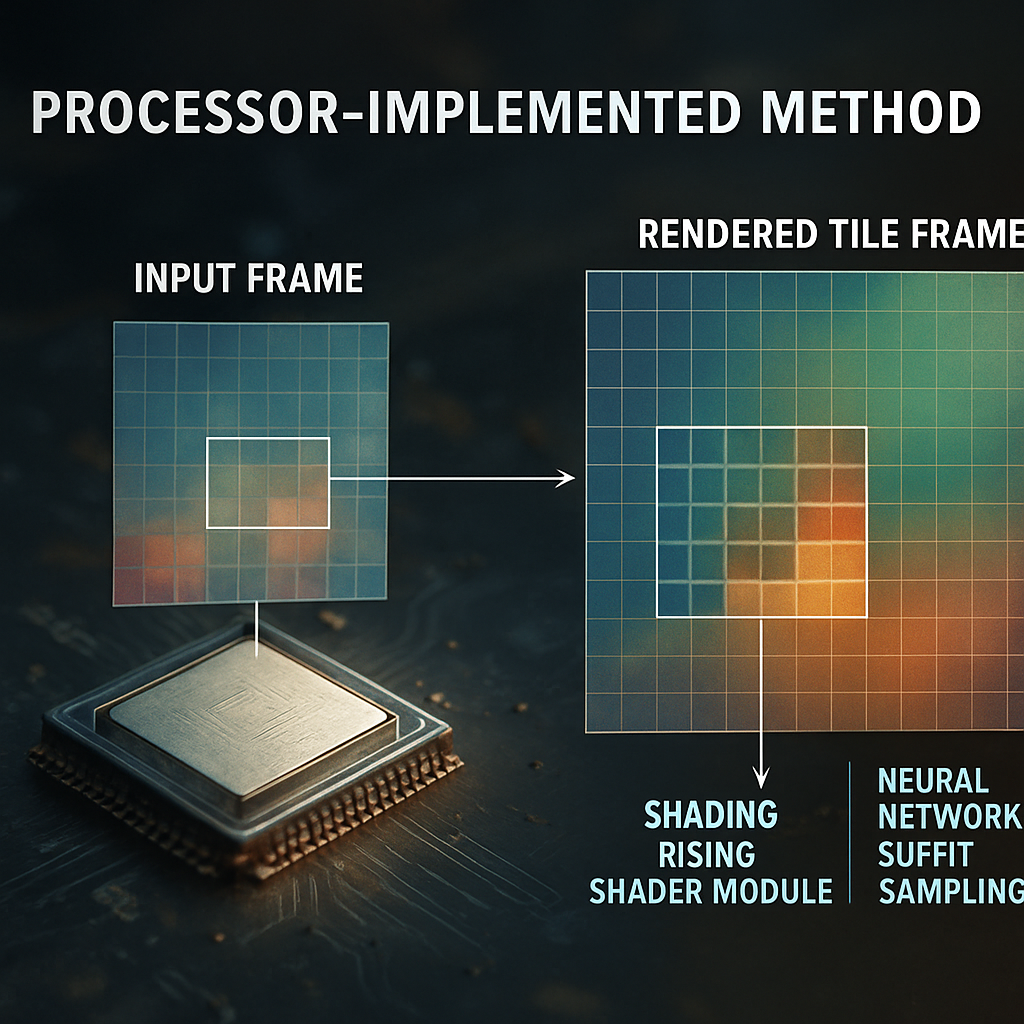
The core idea is to break the image into smaller parts called tiles. Imagine a big picture being split into lots of little rectangles, like tiles on a floor. Each tile is worked on one at a time or even in parallel, which is great for modern GPUs.
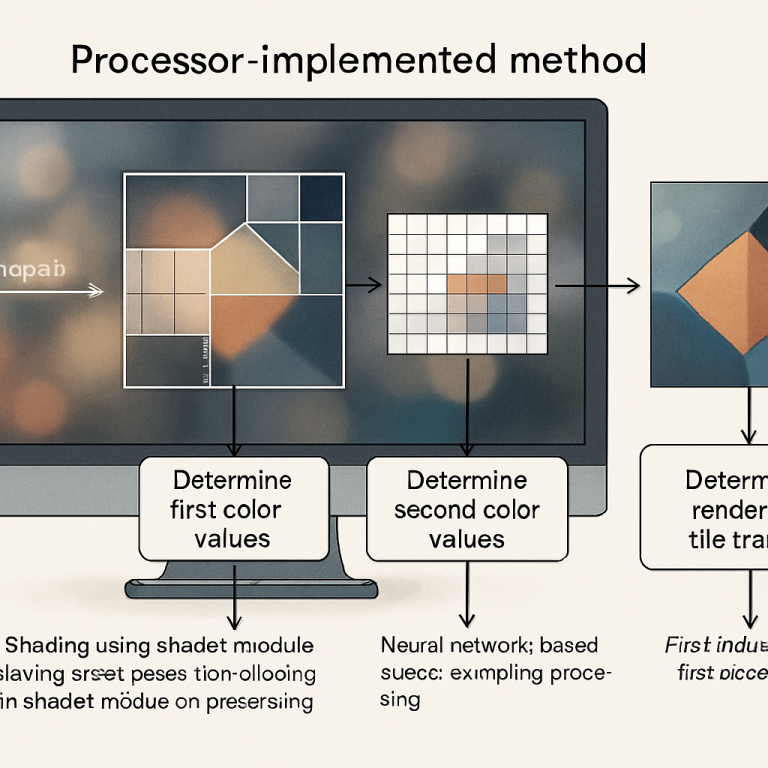
Inside each tile, the method looks at the edges—the outermost rows and columns of pixels. These are the pixels that are most likely to show sharp changes, like the edge of a character or a border between light and shadow. For these edge pixels, the GPU does full shading, just like in the classic approach. This makes sure that important details are sharp and accurate.
For the middle part of the tile, the “non-edge” region, the invention uses a mix. Some of these pixels are shaded with the GPU, based on how much time or power is available. For example, if you want to save power, you can shade fewer inside pixels. If you have lots of resources, you can shade more. This can be adjusted on the fly, making the system flexible.
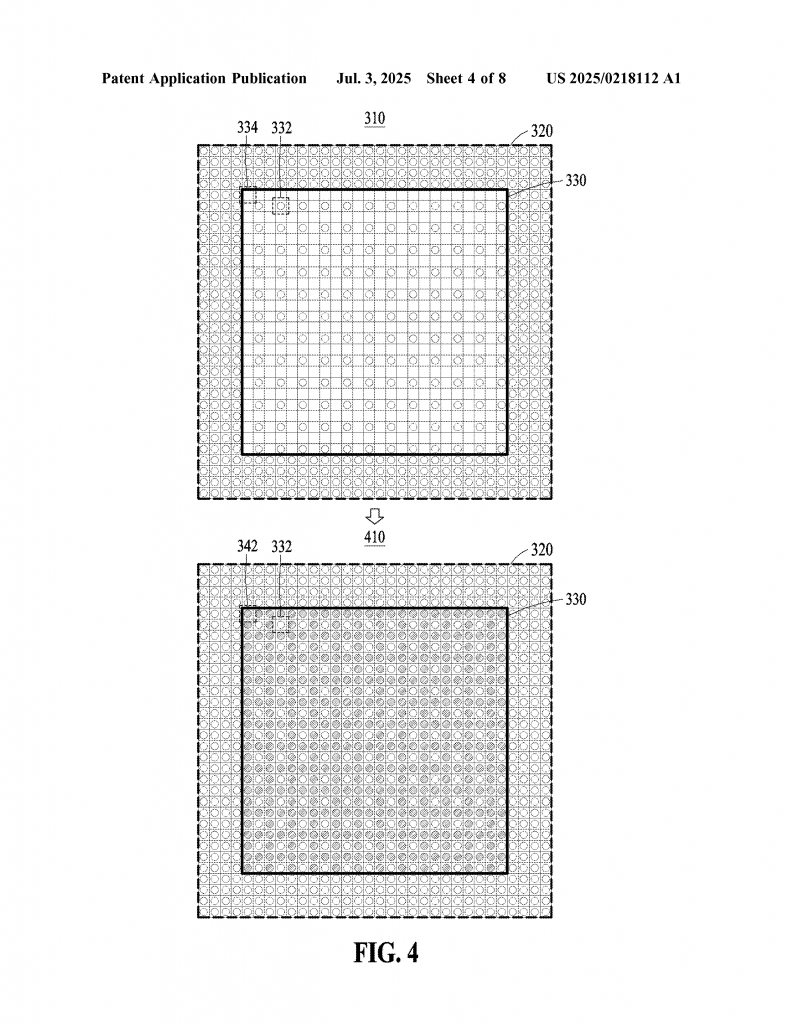
The rest of the non-edge pixels (the ones not shaded) are filled in by a neural network using super-sampling. The AI looks at the already-shaded pixels (both the edges and any inside ones) and guesses what the missing pixels should look like. Because the AI has good data all around, it can make accurate guesses and keep everything looking smooth.
Here’s how the process goes, step by step:
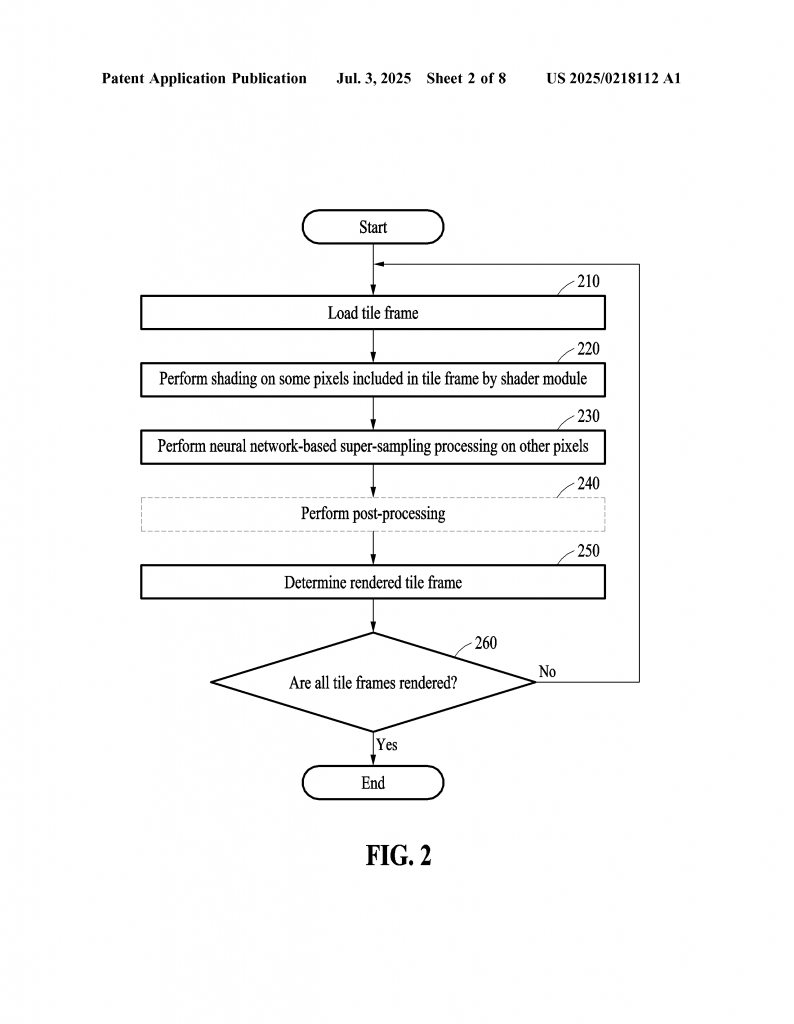
1. The image is split into tiles, each tile is loaded into memory.
2. For each tile, the edge pixels are fully shaded by the GPU. Some inside pixels may also be shaded, depending on settings.
3. The tile now has a mix: sharp edges with real colors, and some inside points also filled in.
4. The tile is passed to the neural network, which fills in the missing inside pixels using super-sampling.
5. The finished tile (now with all pixels filled in) is sent back to system memory.
6. Once all tiles are done, they are put together to make the full image, ready to be shown.
A key innovation is that the neural network never needs to look at other tiles. It only uses data from inside its own tile, thanks to the fully shaded edges. This means no more waiting for neighbors, no more padding, and no more fuzzy borders. Each tile is independent, so the system can go as fast as the hardware allows.
Another smart feature is the ability to change how many inside pixels get shaded, based on needs. If you want to save battery, you can let the AI do more work. If you want the best quality and have power to spare, you can shade more inside pixels. The system can even adjust on the fly, like lowering GPU work if the battery is low or the game is running too slowly.
The hardware setup is also clever. The GPU has special modules for shading and super-sampling, and a scheduler decides which tiles to work on and in what order. Memory is used efficiently: graphics memory keeps tiles handy for fast access, and system memory stores the final results.
The neural network used is a convolutional neural network (CNN), which is great at spotting patterns in images and filling in gaps. The CNN is trained in advance, so it knows how to make blurry or missing pixels look sharp and real. When running, it uses the shaded pixels around the missing ones to make its best guess, keeping the image smooth and clean.
The invention isn’t just for games or movies—it can be used in any device that needs fast, high-quality images: phones, tablets, VR headsets, TVs, and even servers. It works well for any picture or video that needs to look good without using too much power or memory.
In summary, the key innovations are:
– Splitting images into tiles for easy, fast processing
– Shading edges with the GPU for sharp details
– Using a neural network to fill in the rest, based only on inside data
– No need for neighbor tiles or padding, so everything is simple and quick
– Flexible control over quality and power use
– Efficient memory and hardware design, making the process smooth and scalable
This approach brings together old and new: reliable shading where it matters, smart AI where it can do the most good, and a setup that saves time, power, and memory.
Conclusion
The new method for image rendering described here is simple yet very smart. By combining classic GPU shading for the important edge pixels and AI-powered super-sampling for the rest, it solves long-standing problems in making images both fast and beautiful. This approach saves power, works with less memory, and can adjust to the needs of different devices and users.
For anyone making games, movies, or devices that need great visuals, this invention offers a practical way to get more from today’s hardware and software. It’s a step forward in making computers work smarter, not harder, and promises a better experience for everyone who uses digital images.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250218112.

