STORAGE FORMAT FOR CHINESE LANGUAGE AND RELATED PROCESSING METHOD AND APPARATUS
Invented by YANG; Mingwei
Chinese is a beautiful language, but computers have always struggled to handle it in a way that is both smart and simple. A new patent application introduces a fresh way to store and process Chinese text, called Readable Hanyu Expression (RHE). This article will help you understand the market need, the science and history behind Chinese text in computers, and how this invention changes everything for Chinese language processing.
Background and Market Context
Today, Chinese is one of the most important languages in the world. Billions of people use it every day in homes, schools, and businesses. But when it comes to computers, Chinese is not always easy to handle. Unlike English, where each letter is simple and linked to a sound, Chinese uses thousands of characters. Each character has its own meaning and sound, but the written form often does not tell you how to say it. That’s a big problem when working with computers.
In the past, computers were designed mainly for English. They used simple codes, like ASCII, which could represent only English letters, numbers, and a few symbols. When it came to Chinese, this system didn’t work. The first solution was to create special codes just for Chinese, like GB2312 in mainland China and BIG5 in Taiwan and Hong Kong. These codes let computers store and show Chinese characters, but they were not perfect. Each character got a unique code, but there was no help for knowing how to say the word.
Later, Unicode came along. This giant code system tried to include almost every character from every language. Chinese got a huge number of codes, covering both the “simplified” set used in China and the “traditional” set used in Taiwan and Hong Kong. Even so, Unicode is still just a giant list of numbers for each character. It does not help people know how to say the words or how to deal with characters that look the same but sound different, or vice versa.
Another twist is that Chinese has two main writing systems: simplified and traditional. Sometimes a simplified character matches only one traditional character, but sometimes it matches more than one. That creates confusion and makes it hard for computers to switch back and forth cleanly.
There is also Hanyu Pinyin, which is a way to write Chinese words using English letters and numbers for the tones. It helps people pronounce words and is often used for learning or typing Chinese on a keyboard. Still, most storage and display systems do not use Pinyin as their main way of saving Chinese text.
With the growth of the internet and global trade, the need for better Chinese text processing is stronger than ever. People want to read, write, and search Chinese words easily, no matter which version of the writing system they use. They want to learn Chinese, look up words, and switch between characters and Pinyin. None of the old systems solve all these needs at once.
This is where the new patent steps in. It introduces a way to store Chinese words so that their sound, their tone, and their meaning are all easy to see and use. The new format, called RHE, makes Chinese text much more “readable” for both people and computers. It promises to make life easier for students, teachers, business people, and anyone who uses Chinese in the digital world.
Scientific Rationale and Prior Art
To understand why this new method matters, we need to look at how computers have handled Chinese up to now.
Traditional systems like ASCII were built for simple languages. They could handle about 128 different symbols. That was enough for English, but not for Chinese, which has over 50,000 possible characters (though only a few thousand are widely used). To make things work, new code tables were created. GB2312, for example, gave each Chinese character a two-byte code. BIG5 did something similar for other parts of the Chinese-speaking world. Unicode tried to bring all these codes together, giving each character its own place in a giant table. Still, these systems only focused on how to store the shape of the character, not how to say it.
The difference between Chinese and English is clear. In English, you can often guess how to say a word by looking at its letters. In Chinese, the shape of a character almost never tells you the sound. Many characters share the same sound but look different. Some characters can be pronounced more than one way, depending on the context. To read and speak Chinese well, you need to memorize a lot.
This is why Hanyu Pinyin was invented. Pinyin writes Chinese words using English letters and numbers for tones. It helps people learn the sounds, but Pinyin is not used for storage or main display. When you read a Chinese book, it is in characters, not Pinyin. When you type Chinese on a keyboard, you often use Pinyin to input the words, but the computer saves the result as characters.
Earlier systems tried to solve some of these problems. Some tools let you see both the character and the Pinyin. Some apps let you switch between simplified and traditional characters. But these systems are often clunky. They do not make it easy to know all the possible sounds, tones, or meanings for each word.
Another big problem is that computers store Chinese words as individual characters. But in real life, words are often made up of two or more characters. Storing each character by itself does not always capture the meaning of the full word. For example, “中国” (China) is a word made of two characters, but if you store them separately, you might lose the fact that together they mean “China.”
Some systems tried to add extra codes or special fonts, but this just made things more complex. None of the old methods could handle all the needs: making text easy to read, easy to speak, and easy to switch between writing systems.
The new patent builds on years of effort to solve these problems. It borrows the idea of using Pinyin to help with pronunciation, but it goes much further. It creates a smart way to store every word, not just as a character, but as a package of its sound (without the tone), its tone, and a special mark that tells it apart from other words that sound the same. This way, you can always know how to say the word, what it means, and how it should look in both simplified and traditional Chinese. It makes the storage both human-friendly and computer-friendly.
In short, past systems focused on the look of the character. The new method brings in the sound, the tone, and the meaning, all in one. It is a complete step forward for anyone who works with Chinese text on computers.
Invention Description and Key Innovations
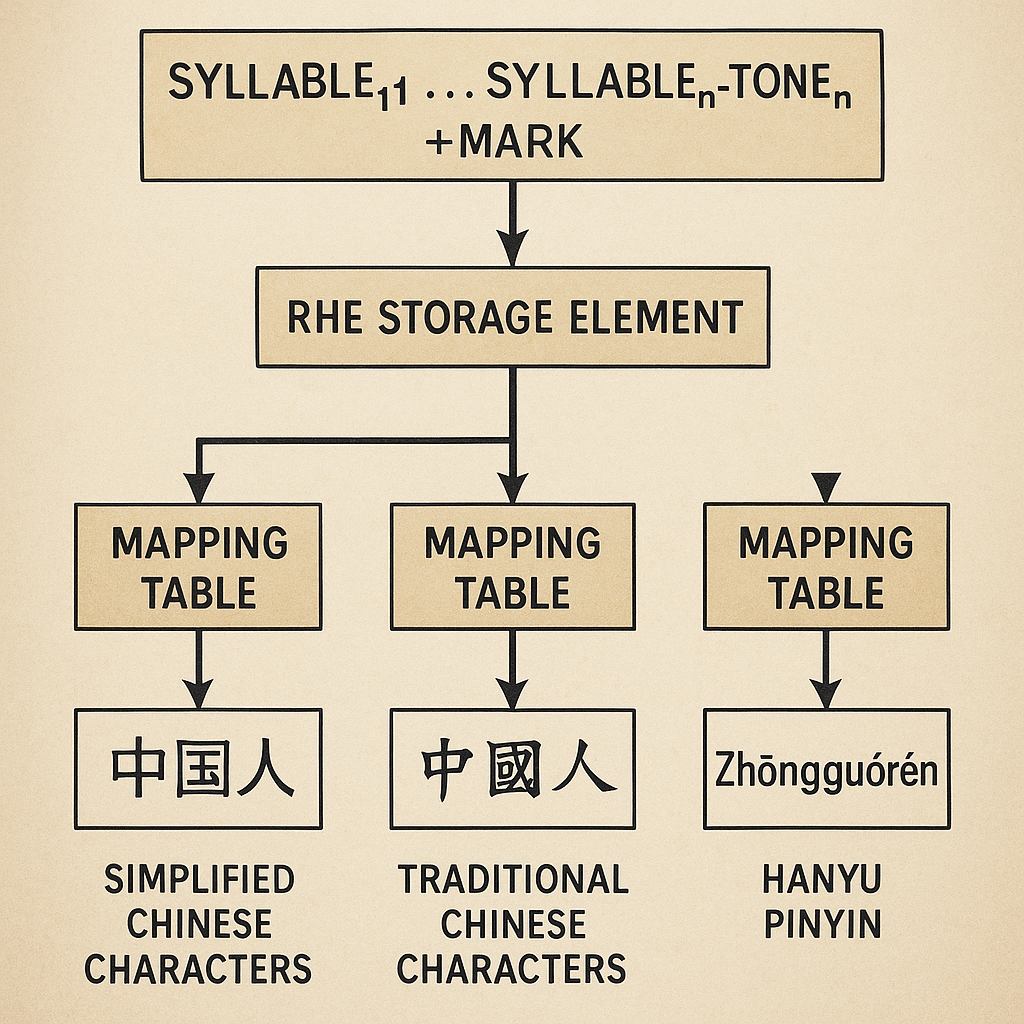
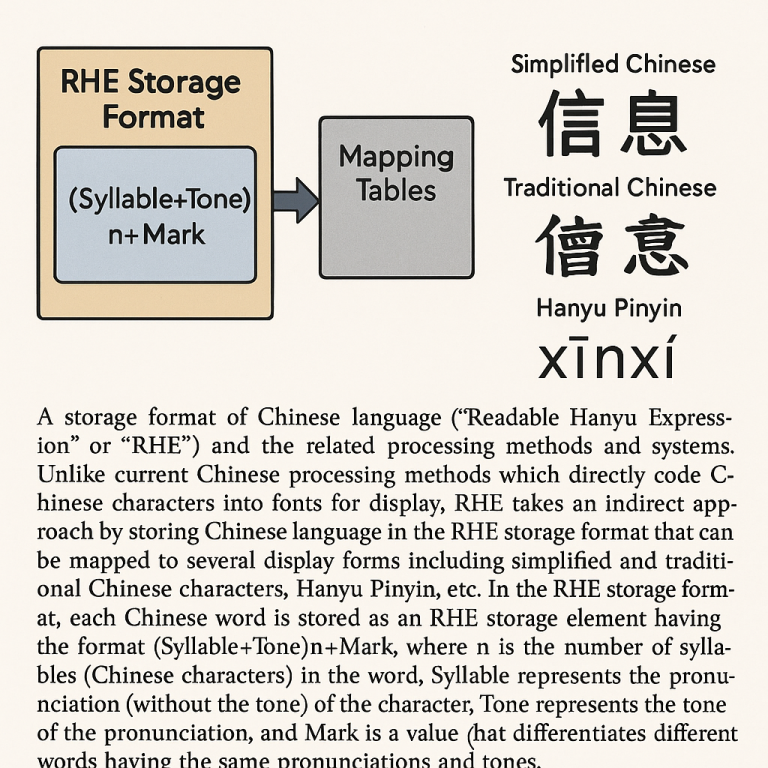
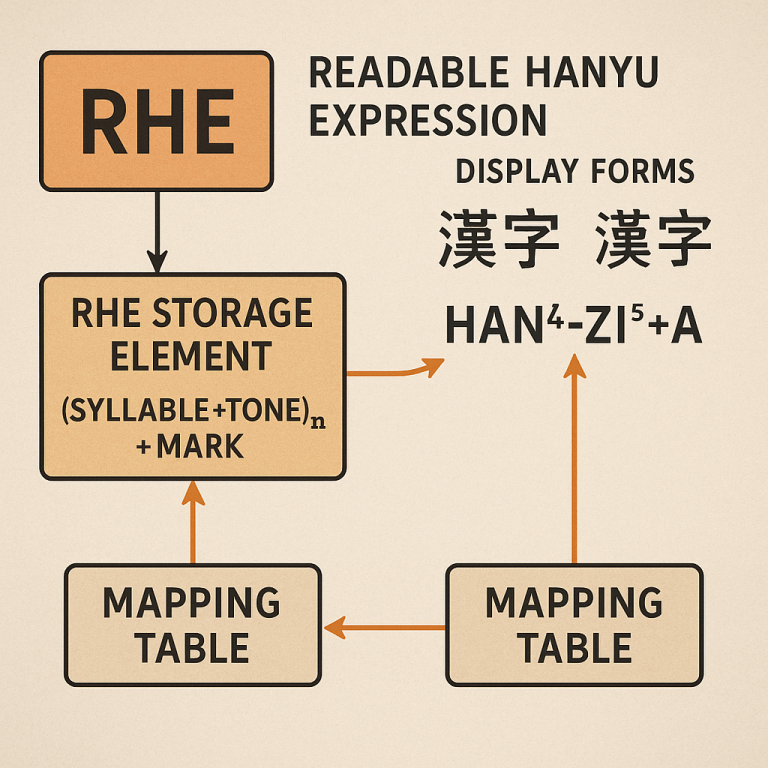
The heart of this invention is a new way to store Chinese language that is easy to read, pronounce, and convert between different writing systems. This new storage method is called Readable Hanyu Expression, or RHE.
In the RHE system, each word in Chinese—whether it is made up of one character or several—is turned into a special string of letters and numbers. This string is divided into three main parts:
First is the Syllable, which shows how to say the word, using Pinyin letters (like “zhong” or “guo”) but without the tone. This way, anyone who knows Pinyin can see how to say the word right away.
Second is the Tone, which is a number from 0 to 4, or sometimes higher for special cases. Each number stands for a tone in Mandarin Chinese. 1 is the first tone, 2 is the second, up to 4. 0 means no tone or a soft tone, which is used in some words. Sometimes, numbers 5 to 9 are used to show a special “r” sound at the end, which is common in spoken Chinese.
Third is the Mark, which is a three-digit number (like 001 or 202). This mark tells apart words that are spelled and pronounced the same but mean different things or look different. For example, “wang2” can mean “king” or “to look,” but each gets its own mark so you always know which one you mean.
For single-character words, the storage looks like this: Syllable + Tone + Mark. For example, “wang2002” could mean “king.” For words with more than one character, the storage strings together each Syllable+Tone pair, then adds one Mark at the end. For example, “zhong1guo2007” could stand for “China.”
The system uses only regular English letters (A-Z) and numbers (0-9), which makes it easy for computers to store and search. It also means you can read the stored data and figure out how to say the word, even if you don’t know the Chinese character.
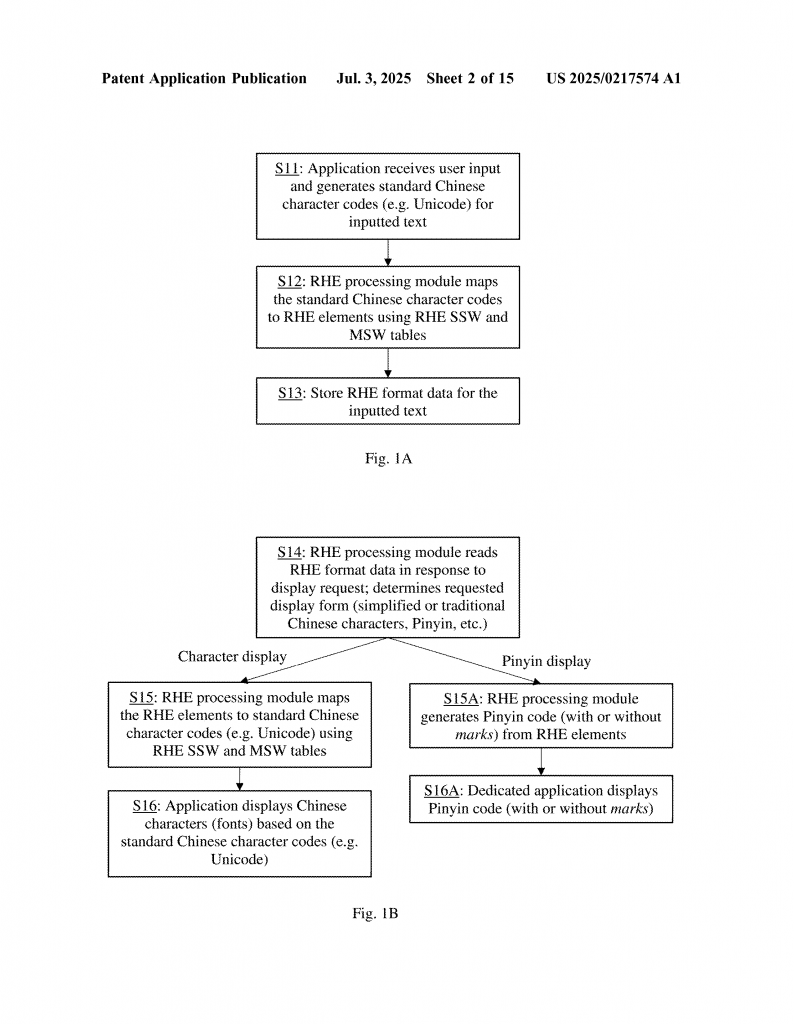
But the RHE system is more than just a way to store words. It also includes smart mapping tables that help convert RHE strings into whatever form you want: simplified characters, traditional characters, Pinyin with or without tone marks, or the RHE form itself.
Here’s how it works in practice:
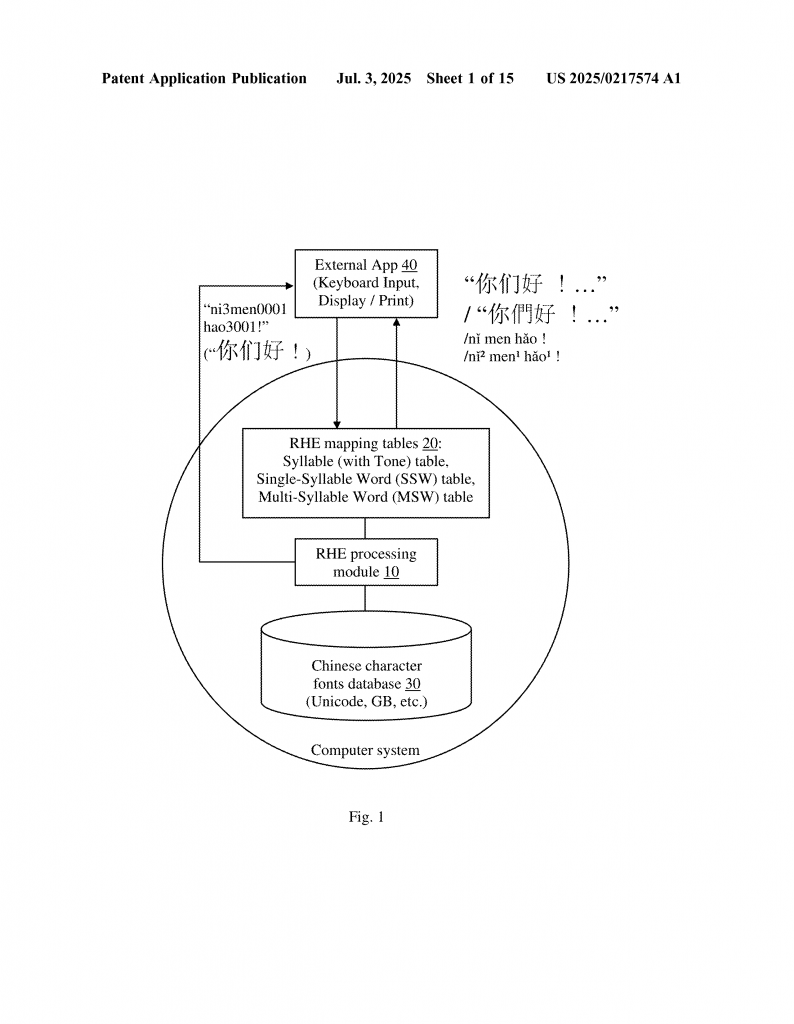
When you enter Chinese text, your computer takes the standard character codes (like Unicode) and looks them up in the RHE tables. It turns each word into its RHE string. This data is then stored in the computer.
When you want to show the text later, you choose how you want it to look. The computer can turn the RHE strings back into simplified Chinese, traditional Chinese, or Pinyin. If you want to see both the character and the Pinyin together, that’s easy too. You can even search, sort, or index the data using the RHE form, which is very handy for language learning or dictionary apps.
The RHE method is smart about difficult parts of Chinese. It can handle words that change tone at the end, or words that get the “r” sound added (like “huār” for “flower”). It does this by changing the tone number in a simple way, so the computer always knows when to add the “r” or switch to a soft tone.
Let’s look at a real example. Take the word for “China,” which is “中国.” In RHE, it might be stored as “zhong1guo2007.” “zhong” is the first syllable, “1” is the first tone, “guo” is the second syllable, and “2007” is the Mark. If someone wants to see the word in Pinyin, the computer can turn it into “zhōngguó.” If they want the simplified Chinese, it’s “中国.” If they want traditional, it’s “中國.” The RHE string is always the same, making it easy to switch between forms.
For a poem or a longer text, every word is stored as its own RHE element. The computer then uses the mapping tables to show the text in the way the reader wants. This helps a lot with learning, since you can see both the character and the Pinyin, and you can be sure of the correct tone and meaning for each word.
Another great thing about RHE is that it lets you search for words by sound, not just by character. Since the RHE strings include the Pinyin spelling and tone, you can look for all words that sound the same, or sort words by how they are said, not just how they look.
The RHE format is designed to work with any computer or device. It uses only the basic letters and numbers that every system understands. It can be used for mobile phones, tablets, computers, servers, or even in the cloud. The mapping tables can be updated as needed, and the system can grow to include more words, phrases, or even new dialects.
In summary, the RHE system brings together the best of all worlds. It keeps the meaning and sound of each word clear, makes it easy to switch between writing systems, and is simple to use for both people and computers. It opens the door to new ways of learning, searching, and enjoying the Chinese language on any device.
Conclusion
The Readable Hanyu Expression (RHE) patent is a big step forward for Chinese language processing. It solves old problems by making every word easy to read, pronounce, and display in any form you want. Whether you are a student, a teacher, a businessperson, or just someone who loves the Chinese language, RHE makes Chinese text more accessible than ever before. By blending sound, tone, and meaning into one simple storage format, RHE paves the way for smarter apps, better learning tools, and a richer digital experience for Chinese speakers everywhere.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217574.

