ADVANCED MAXIMAL ENTROPY MEDIA COMPRESSION PROCESSING
Invented by Denis; Andrew, Wills, JR.; Harry Howard, Seer Global, Inc.
Media files are everywhere—songs, movies, podcasts, and more. But as our desire for high quality grows, so does the size of these files, making storage and streaming tough. What if a new way could shrink these files dramatically, without losing what makes them sound or look amazing? Let’s break down a new patent-pending approach that uses smart AI, smart math, and a deep understanding of how people see and hear to make media files smaller, faster, and even better.
Background and Market Context
Let’s start with the basics. Every day, billions of people listen to music, watch videos, join conference calls, or play games. All of these activities rely on media files that travel across the internet or sit on our devices. As we want better and better quality—think high-resolution video or “lossless” audio—these files get bigger and bigger. That means they use up more space on phones and computers, eat up more of our data plans, and take longer to stream or download.
Companies that store or send this content—like streaming platforms, broadcasters, and cloud storage providers—face big challenges. If they use old compression methods, they risk losing details that make a song or video feel “real.” If they don’t compress enough, files become so big that users get frustrated waiting for them to load or play.
For many years, the main way to shrink media files has been to use clever tricks from math and engineering. Techniques like MP3 for audio, or H.264 for video, work by removing pieces of the signal that are thought to be less important, or by finding repeating patterns and storing them more simply. But these methods rely on rules set decades ago—rules that guess at what people can hear or see, and rules that don’t change much even as our devices and tastes evolve.
Today, the need for efficient, high-quality compression is bigger than ever. Think about:
- New formats like 4K and 8K video, which are much bigger than older formats.
- “Lossless” audio formats that promise perfect sound but require lots of space.
- Mobile devices and wireless networks, where saving bandwidth and battery life is crucial.
- Cloud gaming and virtual reality, where delays and glitches ruin the experience.
At the same time, we have new tools—especially artificial intelligence and machine learning—that can learn from huge piles of data, spot patterns no human could see, and adapt to new situations on the fly. The patent described here brings all this together, aiming to set a new standard for media compression—one that doesn’t just shrink files, but does so in a smarter, more flexible, and more “human-aware” way.
Scientific Rationale and Prior Art
To see why this new approach matters, let’s look at what came before. Early compression methods were built on a few simple ideas:
- Cut out what people supposedly can’t hear or see (like very soft sounds or very high frequencies).
- Store repeating patterns once, rather than over and over.
- Use special codes to make common patterns take up less space (think of Morse code, where “E” is just one dot because it’s used often).
For audio, formats like MP3 and AAC use “psychoacoustic” models—that means they try to guess what sounds you won’t notice, so they can throw them away. For video, formats like H.264 or HEVC break images into small blocks, predict what will change from one frame to the next, and only store the differences.
More recently, researchers started using AI and deep learning. Some new patents use neural networks to clean up noisy recordings, fill in lost pieces, or even make low-quality sounds or images look and feel richer. Other inventions use “autoencoders”—special neural networks that learn to squeeze information into a smaller space and then stretch it back out again.
But these newer methods still have gaps. Many focus on one type of media (just audio, for instance), or work only in special situations. Some AI models need so much computing power that they are too slow or expensive for real-world use. Others forget about “backward compatibility”—meaning files can’t be played on regular devices and need special software.
Another key problem: most existing systems don’t really understand what parts of a song or video are most important to people. They use simple rules and hope they work for everyone. But human perception is complicated. What we notice—and what we don’t—depends on context, on what’s happening in the scene or the song, and on our brains and bodies.
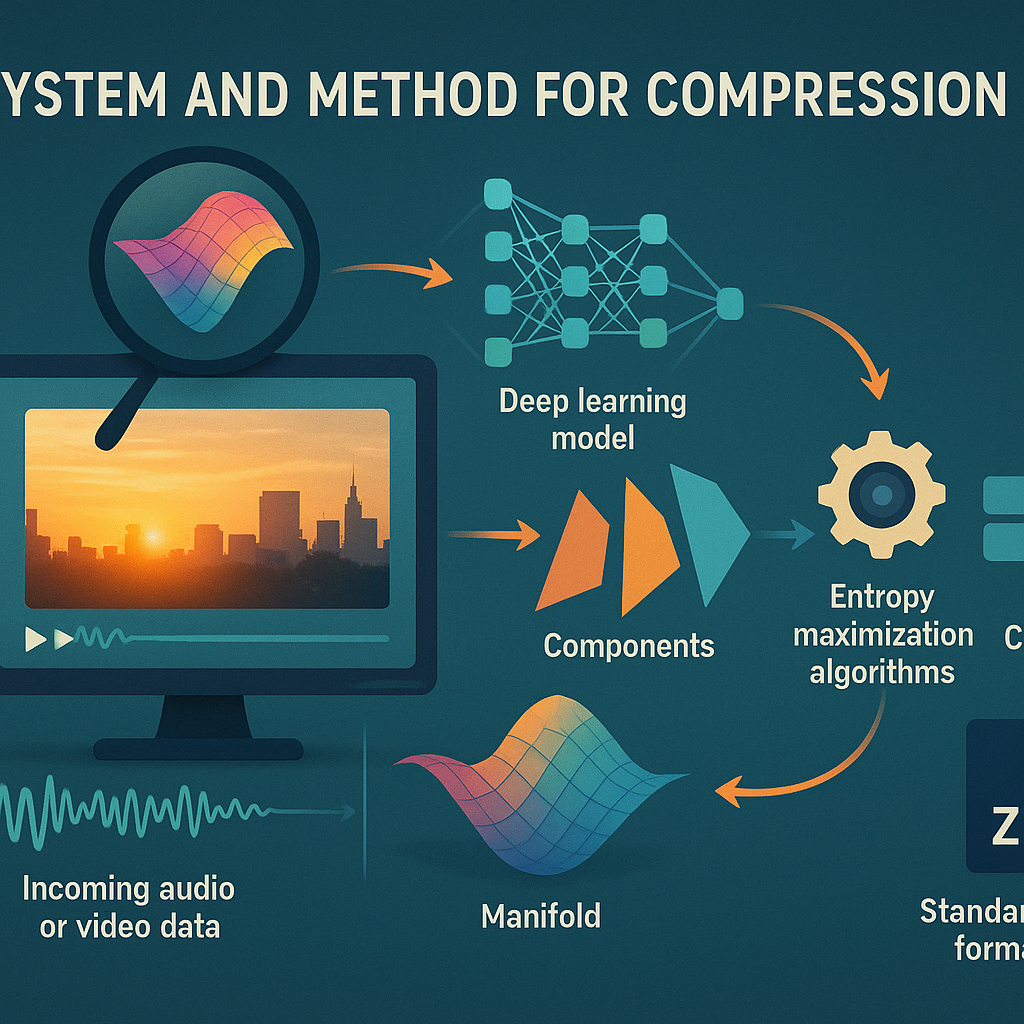
The new patent tackles these challenges head on, blending signal processing, machine learning, and real insights into perception. It looks at not just what’s in the file, but how people actually experience it. It uses “multi-faceted analysis”—breaking down the media in several ways at once—and builds a “dimensional manifold” that captures the true shape of the information. The system then uses advanced AI models to pack the most important parts tightly, while letting less important details take up less space. And it does all this while making sure the result can still be played, stored, or streamed using common formats.
Here’s what really stands out compared to earlier inventions:
- Combining many types of analysis (spectral, statistical, perceptual, and more) rather than just one.
- Using a deep learning model trained not just to compress, but to understand and match what people actually notice.
- Applying smart “entropy maximization” to make sure every bit of the file carries as much useful information as possible, with noisy or redundant bits swept aside.
- Designing the system to work with standard file containers, so it fits into existing apps and devices.
This is a leap beyond what’s been possible before, making media files smaller, faster, and—most importantly—better for the people who enjoy them.
Invention Description and Key Innovations
So how does this new method work? Let’s walk through it step by step, using simple words and real-world examples.
1. Multi-Faceted Media Analysis
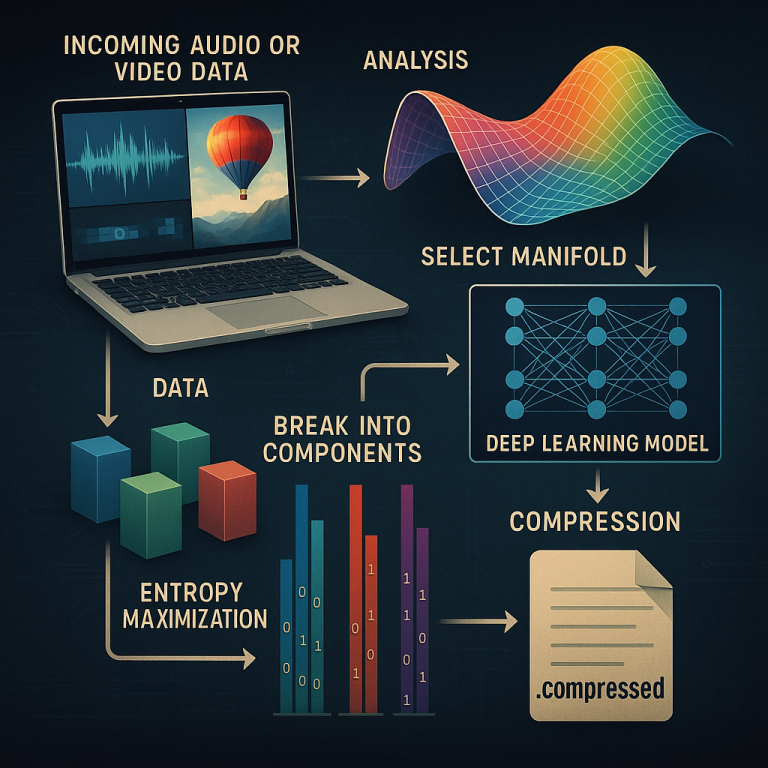
The first step is to carefully study the media—whether it’s a song, a movie, or a podcast. But instead of just looking at the raw data, this system breaks it down from several angles:
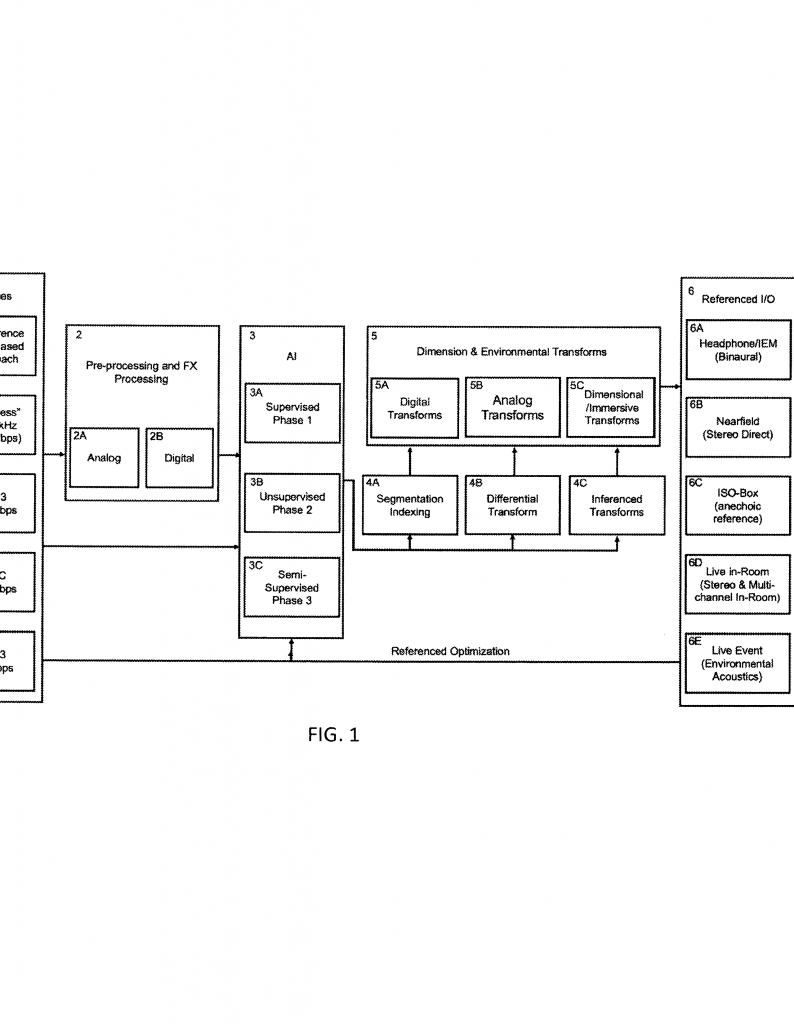
- Spectral Analysis: This means looking at what frequencies (pitches for sound, colors for video) are present, and how they change over time. For sound, it might use something called a “Short-Time Fourier Transform”—think of it as a way to make a moving picture of the sound’s ingredients. For video, it looks at 3D groups of frames to spot both color and motion patterns. Wavelet transforms help see details at many scales, from tiny blips to broad sweeps.
- Statistical Analysis: The system checks how different parts of the media relate to each other—do some pieces always go together? Are there patterns that repeat? It uses math tools like averages, variances, and correlations to find these links.
- Perceptual Analysis: Here’s where things get very smart. The system uses models of how people actually hear and see. For audio, it applies “psychoacoustic” rules (like how loud sounds can hide softer ones). For video, it uses “saliency” models to spot what parts of the image are likely to grab your eye, and “just noticeable difference” models to know what changes people can really detect.
- Temporal-Spatial Correlation: This means looking at how things change over time (like a drumbeat or a moving car) and across space (how an image’s different areas relate). It finds motion, texture, and other patterns that can be stored more efficiently.
2. Dimensional Manifold Selection and Optimization
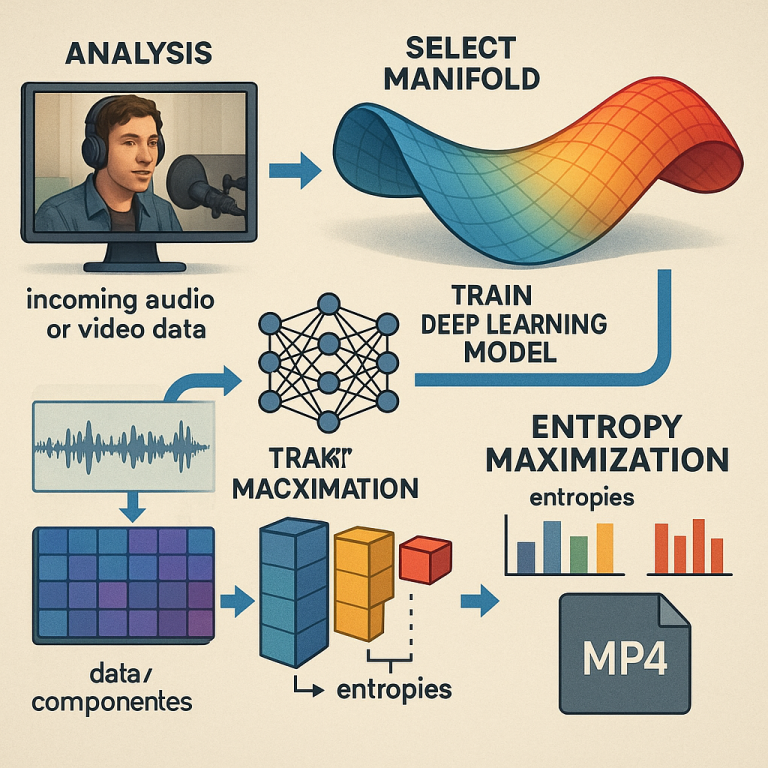
After breaking down the media, the system needs a smart way to represent it—a kind of map that keeps all the important details, but leaves out the noise and extra baggage. This map is called a “dimensional manifold.”
Think of it like folding a giant, messy blanket (the original media) into a neat, small square (the manifold), making sure none of the pretty parts get hidden. The system uses math tools like Isomap, Locally Linear Embedding (LLE), and t-SNE to figure out the best way to do this folding. It estimates just how many dimensions are needed—no more, no less—and tunes the process so the folded version is as close as possible to what matters most.
This step is crucial. It means that when the system compresses the media, it’s not just throwing stuff away at random—it’s keeping the “shape” and “feel” that make the song or video special.
3. Deep Learning Model Training
Now comes the heart of the invention—a deep learning model, usually an “encoder-decoder” network with attention mechanisms. This model learns to take the original media, map it into the neat, compact manifold, and then (if needed) stretch it back out again into a form that sounds or looks just as good.
The model is trained with lots of examples, starting with easy cases and moving to harder ones—a process called “curriculum learning.” It uses a special loss function that considers not just raw accuracy, but also how well the result matches what people would notice (perceptual loss) and how consistent it stays with the manifold structure.
By using skip connections and residual links, the model keeps fine details intact—like the shimmer of a cymbal or the glint in someone’s eye in a video. The model can even adapt to new types of media or new genres with just a little extra training.
4. Entropy Maximization
Once the media is mapped onto the manifold, the next step is to squeeze out every bit of useful information, so nothing is wasted. The system calculates the “Shannon entropy” for each part of the manifold—this is a way to measure how much information is packed in. It uses tools like Independent Component Analysis (ICA) to split out pieces that are really different from each other.
Then, it applies the “Principle of Maximum Entropy”—meaning it arranges things so the information is spread out as evenly as possible, with no clumps or empty spaces. High-entropy parts (the ones carrying a lot of meaning) get more attention—more bits, more care—while lower-entropy parts can be stored more simply.
This step ensures that the compressed file is as dense and efficient as possible—no space is wasted on noise or repetition.
5. Compression and Coding
With the manifold and the entropy-maximized data ready, the system applies the compression. This means:
- Cleaning up the input with noise reduction, so junk isn’t stored.
- Using vector quantization to group related parts and store them together.
- Applying context-adaptive coding—basically, using different tricks in different places, depending on what patterns are present.
The result is a file that’s much smaller, but still holds everything needed to recreate the original media with amazing accuracy.
6. Encoding into Standard Formats
Finally, the compressed data is packaged into standard file containers—like WAV or FLAC for audio, or MP4 for video. The system includes all the extra info needed (like manifold parameters and model details) as metadata, so the file can be used with existing players and workflows. Versioning ensures that as the method improves, older files can still be read, and newer files will work with updated software.
This means companies and users don’t need new devices or apps—everything works out of the box.
Key Innovations at a Glance
What makes this approach truly different?
- All-in-One Analysis: By looking at the media from many angles at once, the system captures what really matters, not just what’s easy to measure.
- Smart Manifold Mapping: The folding process keeps the “soul” of the content, letting the system compress deeply without losing magic.
- Custom AI Training: The deep learning model is trained not just to shrink files, but to understand how people actually experience media.
- Information-Packed Encoding: Entropy maximization makes sure every bit is worth its spot, so files are tight and efficient.
- Compatibility: Files work with current systems, so adoption is easy and fast.
- Flexible Output: The same system can make lossless or lossy files, handle audio or video, and adapt to new formats as they come.
The result is a system that makes media files smaller, faster to send or store, and—most importantly—better for the people who listen and watch. Whether you’re a music lover, a movie fan, a streamer, or a company delivering content to millions, this technology promises a new level of quality and efficiency.
Conclusion
Media compression has always been a balancing act—make files small, but not too small; keep quality high, but not too slow or expensive. This new AI-powered approach, as described in the patent application, changes the game. By combining deep analysis, smart mapping, and advanced machine learning, it finds the sweet spot where files are tiny, but nothing important is lost.
For users, this means songs and videos that sound and look better, load faster, and don’t eat up storage or data. For companies, it means lower costs, happier customers, and the ability to adapt to whatever the future brings—new formats, new devices, new ways to enjoy media.
As media keeps growing, and as our standards for quality keep rising, solutions like this will be key. They don’t just solve old problems—they open new doors, making it possible to experience the world’s sounds and sights in ways we’ve only dreamed of.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250220187.

