COMPUTER-IMPLEMENTED METHOD FOR GATHERING USABLE INFORMATION FROM AN UNRELIABLE DATA SOURCE AND RELATED SYSTEM
Invented by Shearer; Andrew, Steele; Charlie, Mamyrin; Dmitry, Crowell; Collin
In today’s world, data is everywhere. We rely on computers to collect and share information every second. But what happens when some of the data is bad and brings everything to a halt? This new patent application introduces a smart way to keep data flowing, even if some records are “toxic.” Let’s look at why this invention matters, how it builds on what’s come before, and what makes it special.
Background and Market Context
Almost every business now depends on data stored far away, often “in the cloud,” to run websites, apps, and services. These remote data sources are accessed through things called APIs—essentially bridges that let computers talk to each other. When you buy something online, check your bank account, or watch a movie, you are using APIs.
But sometimes, there’s a problem. Imagine asking for a big set of records—maybe a list of customers or sales—from a remote server. If just one record in the batch is broken or “toxic,” the whole request can fail. That means you get nothing, even if most of the data was fine. Like trying to carry a basket of apples but dropping them all because one was rotten.
Businesses need to pull large amounts of data for all sorts of reasons: daily updates, backups, analytics, customer service, and more. If a single bad record can stop the show, it means lost sales, missed insights, and angry customers. This is especially tough for companies that sync data between different systems—think online stores, warehouses, and shipping companies all trying to stay in sync.
Old ways of dealing with these failures are not good enough. Some systems just ignore failed requests, which means missing out on data. Others try to fetch data one record at a time. That works, but it’s painfully slow and uses a lot of computer power. Retrying the same request over and over doesn’t help either—if a record is broken, it stays broken, and you waste time waiting.
The market is hungry for a better answer. Businesses want reliable, fast, and complete data transfers, even when some records are bad. They need a way to get as much good data as possible, without letting a single toxic record spoil the bunch. This demand is only growing as more companies move their data to the cloud and rely on remote APIs for daily operations.
That’s why this patent application is so important. It promises a clever method to keep the data flowing, even when some records are troublemakers. It’s a new way to make sure missing or broken data doesn’t grind business to a halt.
Scientific Rationale and Prior Art
To understand why this invention matters, let’s see what has been tried before and why it’s not enough.
When a remote server returns an error, it often just says “something went wrong.” It doesn’t tell you which record is the problem, or even if the server is working at all. This makes it very hard to know what to do next. If you ask for 100 records and one is broken, you don’t know which one. You just know you got nothing.
Some common old solutions are:
1. Ignoring failures: If the request fails, just skip it and move on. But this means you lose all the data for that request, even if only one record was bad. This is risky, especially if you need complete data for reports or legal reasons.
2. Record-by-record fetching: Instead of asking for a big batch, ask for each record one at a time. This helps you get around the toxic record, but it’s very slow. Imagine trying to empty a swimming pool with a teaspoon. If you have thousands of records, this method takes forever and uses a lot of computer resources.
3. Repeated retries: If a request fails, just try again after a short wait. Maybe the problem will fix itself. If not, try again after a longer wait. This “exponential backoff” can lead to long delays and doesn’t help if the record is truly broken. You end up wasting time and still don’t get your data.
These methods have real costs. Ignoring failures loses valuable data. Record-by-record fetching slows down the whole system. Retries waste time and energy, especially when the same error keeps happening. None of these really solve the problem of toxic records in a smart way.
Some systems try to split batches into smaller pieces after a failure, but they usually do this in a very basic way. They don’t remember which records are toxic, or they don’t keep track of what’s already been tried. This leads to repeated work, slow progress, and sometimes more data loss.
What’s missing is a way to quickly find exactly which records are toxic, skip just those, and save all the good data. The solution needs to be fast, smart, and able to handle large amounts of data from servers that might not always be working perfectly.
This is where the new patent steps in. It offers a methodical, organized approach to handle toxic records, with the goal of saving as much good data as possible and keeping the process running smoothly.
Invention Description and Key Innovations
This patent application introduces a computer-implemented method and system that tackles the toxic record problem head-on. Let’s break down what it does, how it works, and why it’s a game-changer.
The Core Idea:
When you ask a remote server for a range of records, the system doesn’t just take “no” for an answer. If there is an error, it doesn’t give up, do endless retries, or waste time fetching records one by one. Instead, it uses a smart process to find where the toxic records are hiding, skip them, and collect all the good records.
Step-by-Step Process:
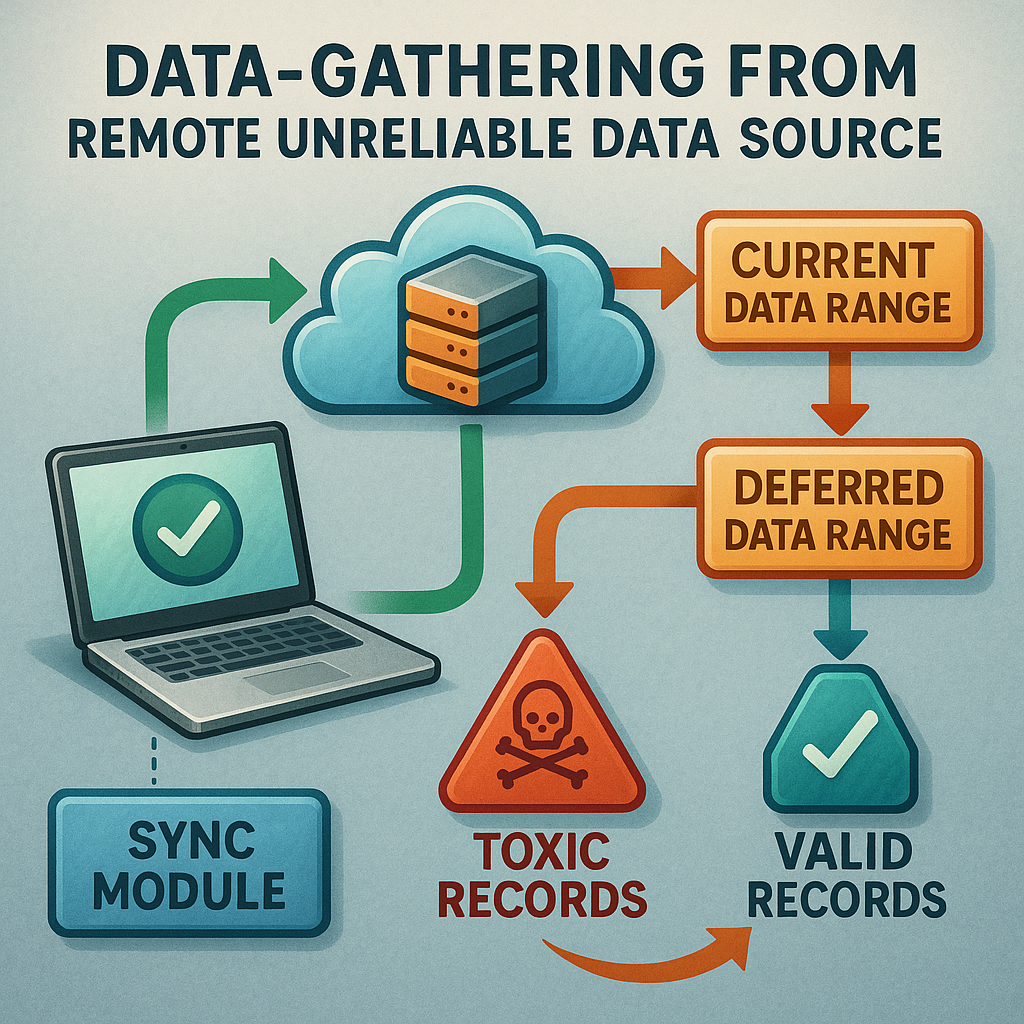
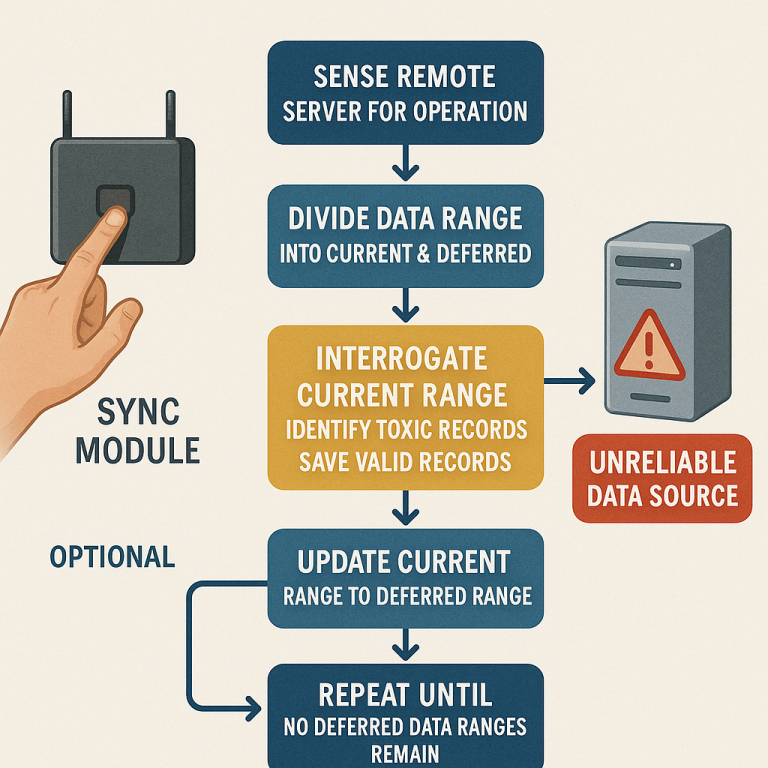
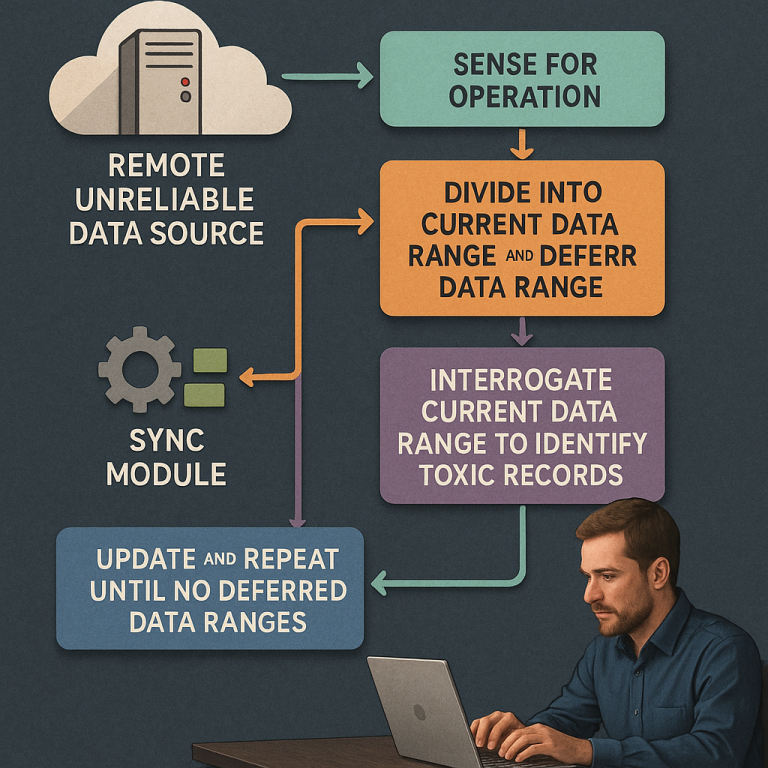
1. Check if the server is working. The system starts by sending a simple command (like a “ping”) to make sure the remote server is online. If it’s down, the system waits and tries again later.
2. Request a batch of data. If the server is up, the system asks for a range of records. If it gets all the data back with no errors, it saves everything and moves on.
3. If there’s an error, start dividing. If the server returns an error, the system splits the requested range into two smaller parts: a “current” range and a “deferred” range. It then tries to fetch the “current” range.
4. Keep narrowing down. If the smaller range still fails, split it again and try each part. This keeps going—like cutting a loaf of bread in half again and again—until the system finds the smallest piece that still causes an error. When it gets to a single record that always fails, it knows it’s found a toxic record.
5. Log the toxic record. The system records which record is toxic so it can be reviewed or retried later. It then skips that record and continues fetching the rest.
6. Repeat for the deferred parts. The system keeps going back to the deferred ranges, splitting and testing each one, until all the good data has been saved and only the toxic records are left uncollected.
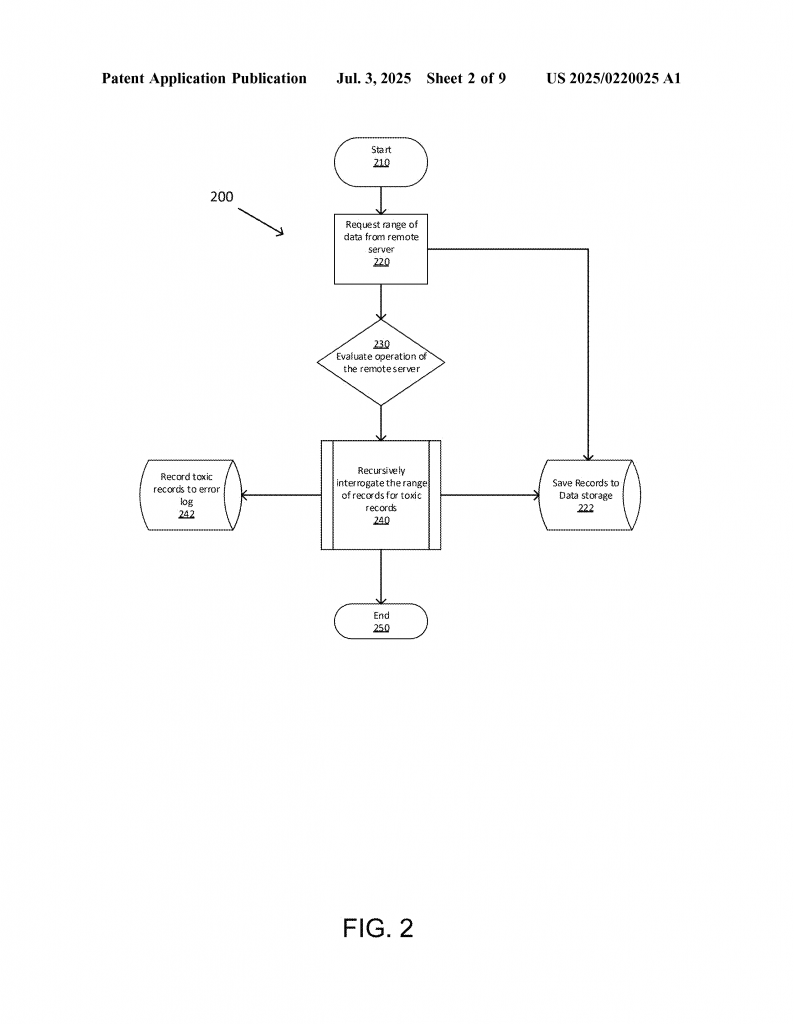
This method is recursive, meaning it can repeat the process as many times as needed, each time getting closer to the exact spot that’s causing trouble. It’s like a detective narrowing down suspects until only the guilty one is left.
Key Innovations:
– Smart Splitting: Instead of giving up or getting stuck in a loop, the system always tries to save as much data as possible. When a request fails, it divides the range and keeps trying the smaller pieces until it finds the bad record.
– Error Logging: Toxic records aren’t ignored. Their exact location is saved in a log so they can be fixed or retried later. This makes it much easier to find and fix data problems.
– Automatic Resuming: If the process is interrupted, it can pick up where it left off. The system keeps track of what’s been done, so it never wastes time repeating work.
– User Control: Users can set the size of the ranges, the delay between retries, and other options. This gives flexibility to adapt to different servers and needs.
– Efficient Use of Resources: By only splitting and retrying parts that fail, the system avoids wasting time and computer power. It doesn’t need to fetch every record one at a time, and it doesn’t endlessly retry doomed batches.
– Works with Many Systems: The method works with any system that lets you ask for data in ranges—by date, number, page, or other identifiers. It’s not tied to any one type of server or API.
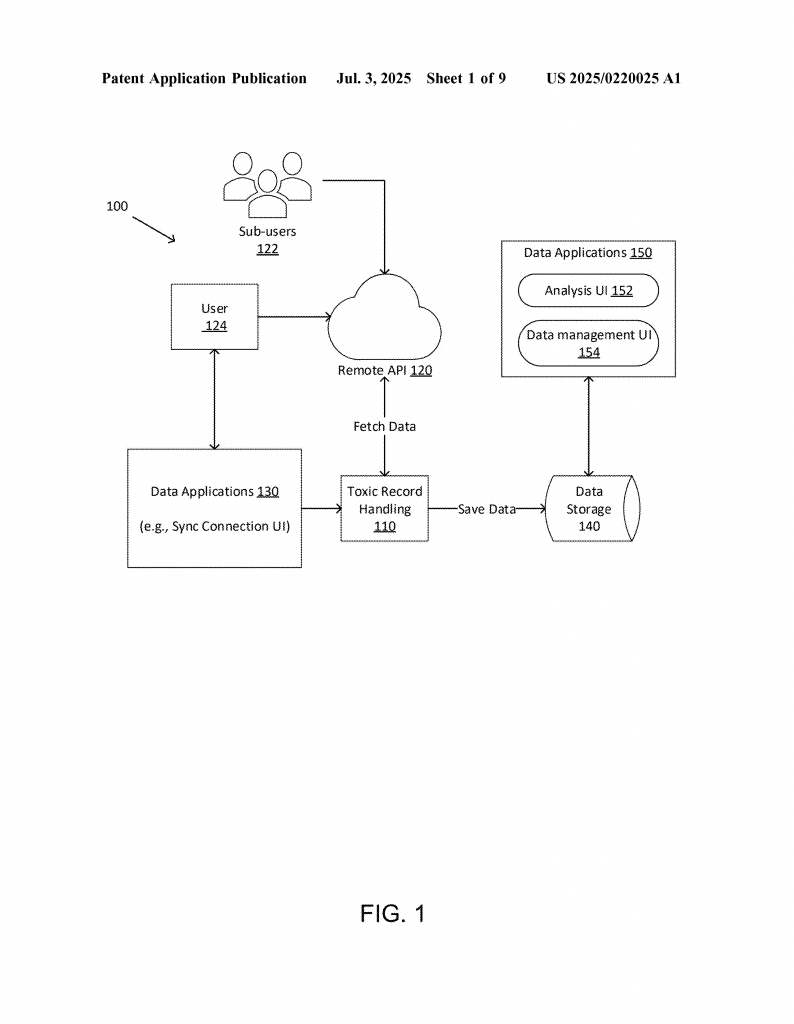
– Seamless Integration: The invention includes modules for user interfaces, backend logic, caching, and error handling, all working together. Users can watch the process, get reports, and take action if needed.
Real-World Example:
Suppose you want to copy a year’s worth of sales records from a remote store’s server. You ask for all the records from January to December. If there’s a broken record in June, the old way would mean losing the whole batch or having to fetch each record separately. With this invention, the system quickly finds the problem record in June, logs it, and saves every other record—January to May, and July to December—without missing a beat.
Why It Matters:
This approach is a big step forward for any business that depends on remote data. It means fewer failures, more complete data, and less wasted time. Companies can trust that their data syncs will work even when some records are bad. IT teams spend less time chasing errors and more time building value.
For system designers, the method is easy to fit into existing tools. It doesn’t require special hardware or expensive upgrades. It’s a smart layer that makes any data retrieval process more reliable and efficient.
Other Uses:
While the main target is data reading, the patent also covers using the same method for writing data—updating records on a remote server. If a write fails because of a toxic record, the system can use the same splitting and logging process to find the problem and save the rest.
The method also works with “chunking” systems that break up big sync jobs into manageable pieces. It can keep track of progress, skip over bad chunks, and always aim to save as much good data as possible.
Conclusion
Dealing with toxic records has long been a headache for anyone who needs to gather data from remote servers. The old ways—ignoring errors, fetching one by one, or endlessly retrying—are slow, unreliable, and wasteful. This new patent application lays out a smarter way to handle the problem. By breaking down requests, zooming in on toxic records, and always saving the good data, it offers a practical, efficient, and reliable answer.
For companies and developers, this means more complete data, faster syncs, and fewer headaches. It’s a win for business, technology, and everyone who depends on clean, reliable data. This invention makes the cloud a safer, smarter place for information to flow.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250220025.

