MACHINE LEARNING SYSTEM FOR PREDICTION OF RESOURCE USAGE BY 5G NETWORK SLICES OR CELLS

Invented by Gaurav; Aman, Vora; Moksha Kuldipbhai, Patankar; Ajit Krishna
Innovation in 5G mobile networks is happening fast. Managing resources across hundreds of thousands of network cells and slices is a huge challenge. The patent application we are exploring introduces a new way to predict network usage with machine learning. This helps mobile networks use their resources better, keep up with demand, and save money. Let’s break down what makes this approach unique, why it matters today, and how it stands out from older ideas.
Background and Market Context
Mobile networks are everywhere. We use them for calls, streaming, smart devices, cars, and even factory machines. The jump from 4G to 5G brought faster speeds and more possibilities. Now, 5G networks are made up of many small parts called “cells” and “slices.” A cell covers an area with wireless service. A slice is a special, virtual part of the network for different needs, like private business connections or smart cities.
Mobile network companies have to keep the service running smoothly for all these users. This is hard, because usage changes all the time. Sometimes, one area gets busy and needs more network power. Other times, a network slice is added or removed for a new business or event. If the network can’t keep up, users get slow service or dropped connections. If the network gives too many resources to one area, it wastes money and energy.
In the past, network operators had to guess how much network each cell or slice would need. They used basic rules or simple math to try to balance resources. But these old ways can’t keep up with the size and speed of 5G networks. Now, there can be hundreds of thousands of cells and slices, and new ones can start or stop at any time.
At the same time, the market wants better service, less downtime, and lower costs. Companies are looking for smarter ways to run their networks. Using artificial intelligence and machine learning is becoming more popular, but it’s still new in mobile networks. The patent we are looking at shows a practical way to use machine learning to solve these big problems.
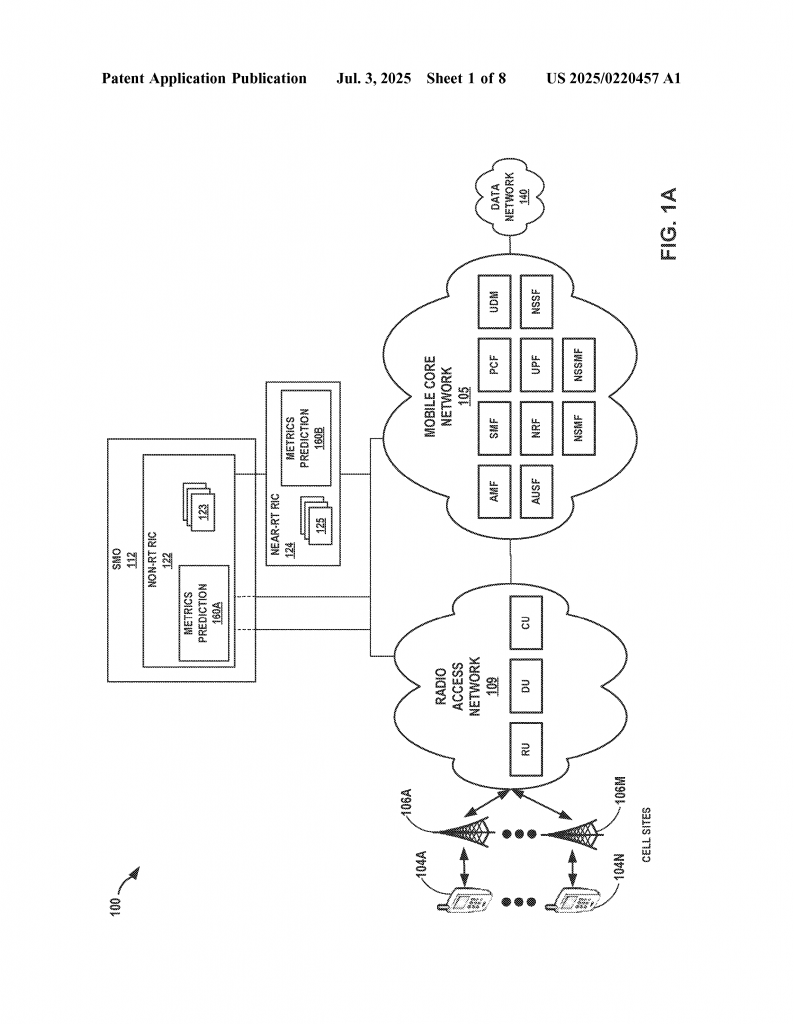
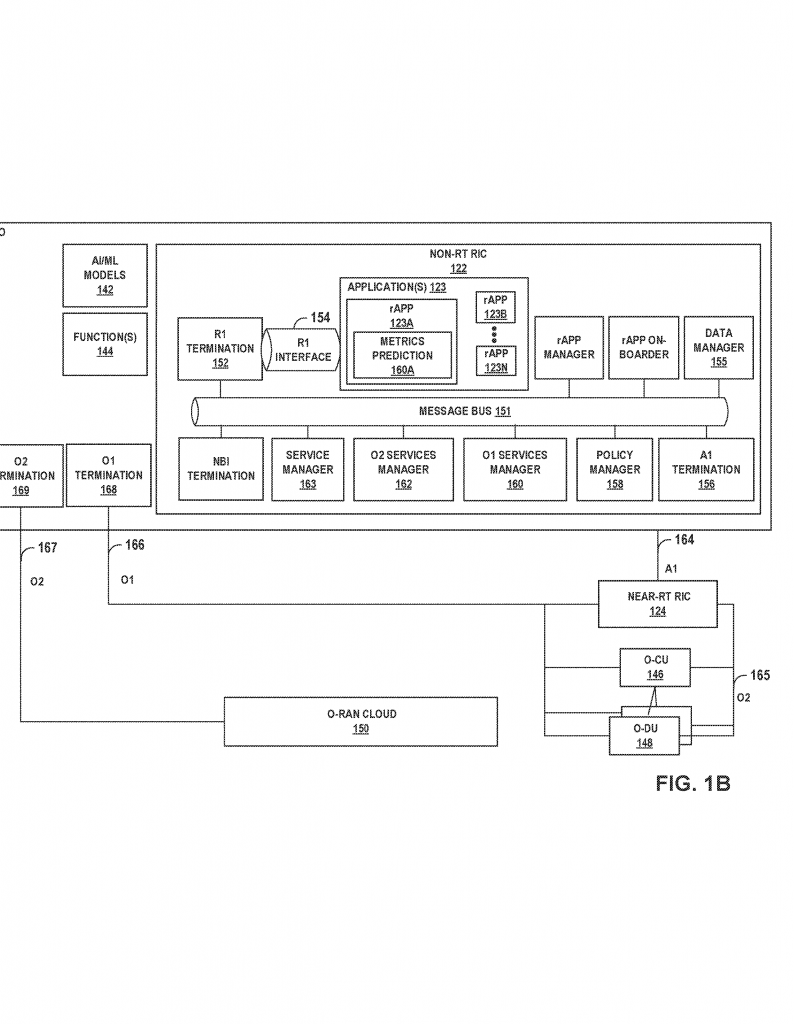
This solution fits right into new 5G systems, especially ones using the Open Radio Access Network (O-RAN) approach. O-RAN lets different companies build parts of the system, making networks more flexible. It also allows for special apps, called rApps and xApps, to control and manage the network in real time or in the background. This patent’s invention can live inside these apps, making it easier for network operators to adopt.
The goal is clear: predict how much network power each cell or slice will need in the future. Then, adjust the resources automatically to keep everything running smooth, fast, and cost-effective. This helps network providers meet customer needs, avoid waste, and stay ahead in a competitive market.
Scientific Rationale and Prior Art
Why is predicting network usage so important? In 5G, the number of devices and the amount of data keep growing. Each device or user can need a different amount of network at different times. Sometimes, a new slice or cell is added with very little history. Other times, usage patterns shift quickly in ways that are hard to guess.
Old solutions tried to handle this by making one prediction model for each cell or slice. That means, if you have 100,000 cells or slices, you need 100,000 separate models. This gets out of hand quickly. It’s hard to manage, slow to update, and takes a lot of computer power and storage. Plus, when a new cell or slice is added, you have almost no data to train a model, so predictions are not accurate.
Other basic methods just used average usage or simple rules. For example, if a cell was busy at 6 PM yesterday, they’d assume it would be busy at 6 PM today. But these rules don’t work well if usage patterns change, or if there’s a special event, or if new network parts are added or removed.
Some recent research tried clustering—grouping similar cells or slices together—and then building shared models for each group. But these solutions often used fixed clusters or did not adjust for changes over time. They also didn’t handle new cells or slices well, and they usually didn’t work with the special O-RAN apps (rApps and xApps) that are part of modern 5G networks.
Another challenge is working with different types of data. In a network, you might want to predict many things—like how much bandwidth is used, how many users are connected, or what the key performance indicators (KPIs) are for reliability or speed. Older methods needed a separate model for each type of prediction, making things even more complex.
The scientific need is for a system that:
– Works for many cells and slices at once, even as they are added or removed.
– Can handle different types of data and performance metrics.
– Makes good predictions even when there is little history for a new cell or slice.
– Fits into the O-RAN architecture, supporting both near-real-time and non-real-time control.
– Is easy to scale, manage, and update.
This patent builds on those ideas, but adds new ways to group data, standardize it, and train machine learning models that can be shared across many network parts. It uses clever clustering, data transformation, and flexible training to solve the gaps left by past methods.
Invention Description and Key Innovations
Let’s look at how this patent solves the problem of predicting network resource usage. The invention uses a clever mix of data grouping, data transformation, and machine learning to make reliable predictions for many network cells and slices—all at once.
Here’s how it works, in simple terms:
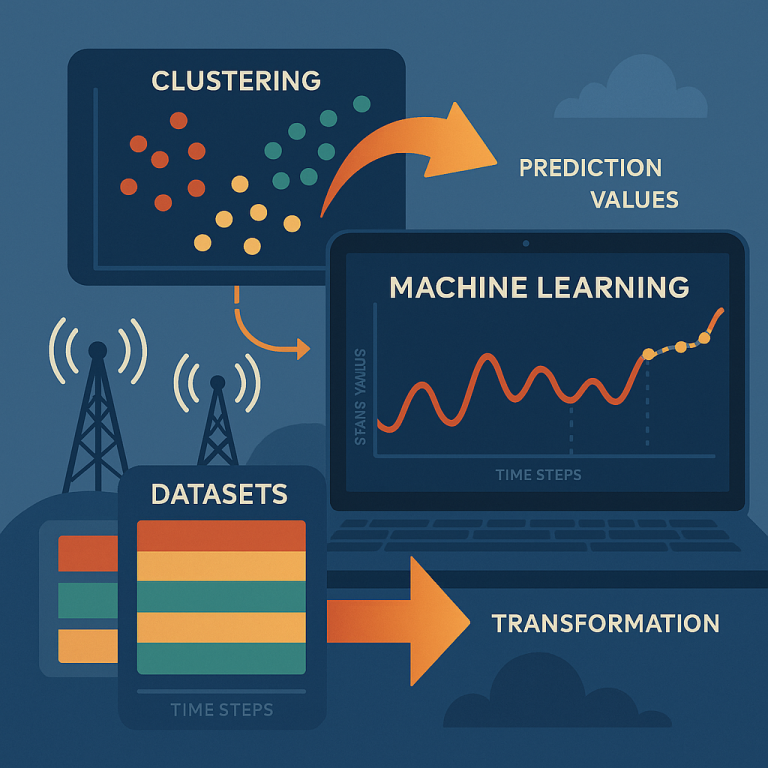
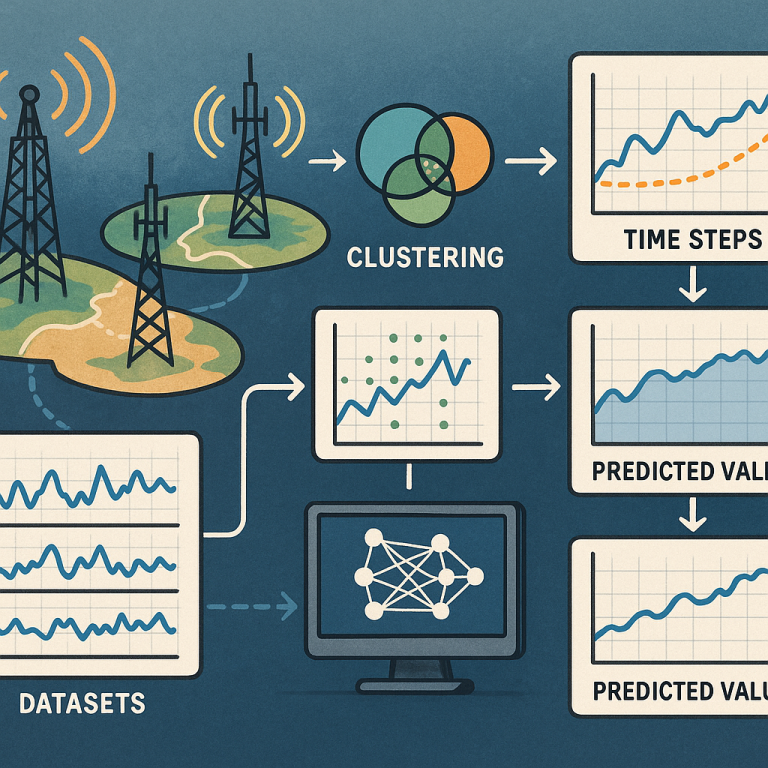
First, the system collects data from many cells or slices. This data is like a timeline, showing how a certain performance metric (like bandwidth usage, number of users, or a specific KPI) has changed over time for each cell or slice.
Next, the system uses a clustering algorithm. Clustering means it looks for groups of cells or slices that behave in a similar way. For example, maybe all the cells in a busy downtown area have similar traffic patterns, or maybe slices for a certain type of business act alike. The clustering can be based on the actual data, on the location of the cells, or on special network IDs.
Once the clusters are made, the system takes a “sliding window” of the most recent data for each member of the group. A sliding window is just a small chunk of past data, like the last 10 or 20 time points. This is important because the most recent data usually gives the best hints for what will happen next.
Before training the machine learning model, the system transforms the data. It standardizes the values in each sliding window—this means it adjusts the numbers so that they all have a similar scale and average. This step is key because it lets the model learn patterns that apply across many cells or slices, even if their raw numbers are very different.
Now, the machine learning model is trained. But here’s the clever part: instead of making a separate model for every cell or slice, the system trains one model per cluster. Each model learns from all the data in its group. This makes the model much better at handling new cells or slices that don’t have much history, since it can borrow patterns from similar network parts.
When a new prediction is needed—maybe for a cell that was just added—the system can still make a good guess. It finds the cluster that fits best, uses the latest data from the new cell (even if it’s not much), and lets the model trained on the group fill in the gaps.
The system can be set up in two main ways:
1. Uni-model approach: Everything is treated as one big cluster and a single model is trained for all data. This is simple and works well when the network parts are similar.
2. Multi-model approach: The system makes several clusters and trains a separate model for each. This is better when different regions or types of network parts behave differently.
This approach is flexible. It can handle different kinds of data, like bandwidth, KPI scores, or other performance metrics. It works for both real-time and non-real-time control, fitting perfectly in the O-RAN architecture using rApps and xApps. The system can even use extra data, like the location of a cell, to help the clustering work better.
The benefits are big:
– The system can scale to handle hundreds of thousands of network parts, without needing a separate model for each.
– It reacts quickly to changes, like when a new cell or slice is added, without waiting for lots of historical data.
– It saves computer power, storage, and time.
– It can predict different kinds of network usage, helping operators balance resources, avoid congestion, and reduce waste.
– It fits into current 5G network management tools, making adoption easier for network operators.
In practice, this means better service for users, lower costs for network operators, and a more flexible, responsive mobile network overall. The invention opens the door for smarter, AI-driven mobile networks that can adapt to new challenges as they happen.
Conclusion
This patent brings a fresh, smart way to predict and manage network resources in the fast-moving world of 5G. By grouping similar network parts, transforming their data, and training shared machine learning models, the invention solves problems that older methods couldn’t. It handles large, complex networks with ease, adapts to new or changing network parts, and fits neatly into modern 5G systems using O-RAN standards. The result is a more efficient, reliable, and cost-effective network for everyone. As 5G networks keep growing, solutions like this will be key to keeping up with the demands of tomorrow’s connected world.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250220457.

