SYSTEMS, METHODS, AND DEVICES FOR HOUSEHOLD CLASSIFICATION
Invented by WHITELY; Christopher Paul, XING; Zhao
Welcome! Today, we’re going to explore a new and powerful method for predicting what content households might watch—even when we don’t know their past viewing habits. This technology is changing the way advertisers, networks, and service providers reach their audiences. Let’s break it down in simple terms, focusing on why it matters, the science behind it, and how the invention works.
Background and Market Context
Television and digital media have changed a lot in recent years. Not long ago, everyone watched the same shows at the same time. But now, households have many ways to watch content—on cable, satellite, or the internet, and on TVs, tablets, and phones. This change gave rise to what’s called “addressable advertising.” This means that advertisers can now send different ads to different homes, even if they’re watching the same show. For example, a family in one neighborhood might see a car commercial, while another family watching the same show in a different neighborhood might see an ad for a new movie.
This type of advertising works much better because it’s more personal. If you show people ads for things they care about, they’re more likely to pay attention and maybe even buy something. But there’s a big challenge: to send the right ad to the right home, you need to know a lot about what that home likes to watch and who lives there.
Sadly, it’s not always easy to get this information. Many homes don’t share their viewing habits, and some aren’t even customers of the service providers who want to target them. This is a problem for advertisers who want to make the most out of their budgets. If you don’t know what a household likes, it’s hard to know which ad to send them. Sometimes, you end up sending the same generic ad to everyone, which isn’t very effective.
Because of these gaps, companies are looking for better ways to figure out what households might want to watch—even if they don’t have direct data about them. They want to use whatever information is available to make smart guesses. If they can do this well, they can make ads more relevant, help networks get better ratings, and give viewers a better experience.
This need for smarter predictions is at the heart of the invention we’re discussing. It’s about making the best use of what we know, filling in the blanks, and giving every home a more tailored media experience.
Scientific Rationale and Prior Art
To understand how this invention works, it helps to know what’s been tried before and why those older methods often fall short. In the past, companies have used simple ways to guess what households might watch. Some methods just looked at the neighborhood or zip code—if your neighbors like a certain show, maybe you do too. Others used basic details like age or income to lump people into big groups. But these simple methods often missed the mark.
A more advanced approach is to collect lots of data about households that have shared their viewing habits. For example, suppose you know that people in a certain group—maybe families who rent apartments in the city and have two children—tend to watch a lot of kids’ programming and family movies. If you find a new household that matches those details, you might guess they have similar tastes. This is called “lookalike modeling.” It’s better than guessing based on zip code, but it still has problems.
One big issue is that you might not have complete data. Some homes have only one device tracked, like a set-top box, when in reality, they might watch a lot of content on smart TVs or tablets. If you only see part of the picture, you can make the wrong guess about their habits. For example, if you don’t see any record of them watching sports, you might think they don’t like sports, when really they watch all the games on a different device you can’t track.
Another problem is that the mix of tracked households might not match the real world. Maybe your data comes mostly from high-income neighborhoods, but you want to predict behaviors in all types of homes. If you use data that doesn’t represent the whole country, your predictions will be off.
Older systems also struggled to handle many different variables at once. People are complex! It’s not just about where they live or how much they earn—it’s about things like family size, hobbies, work schedules, and even how many devices they own. Good predictions need to consider all of these factors, not just one or two.
Finally, most previous solutions couldn’t adjust for missing or unbalanced information. If you were missing data for certain types of households or devices, you just had to live with less accurate results. There wasn’t a good way to “fill in the gaps” or weigh the data so it matched the real mix of homes across the country.
The invention we are dissecting moves past these problems by combining several smart ideas. It uses data from known households, compares them to unknown ones using many features, and then adjusts the results to better match reality. It’s like having a smart detective who not only looks for matches but also corrects for missing clues, making sure the final answer is as close to the truth as possible.
Invention Description and Key Innovations
Now, let’s get to the heart of the invention. The main idea is pretty simple: use what you know about some households to make good guesses about others. But the way it does this is smart, careful, and much more accurate than old methods. Let’s walk through how it works in everyday language.
First, the system starts with two groups: households with known viewing habits, and households whose habits are unknown. For the known group, you might have details about what shows they watch, how much time they spend watching, what devices they use, and so on. For the unknown group, you might only have some basic facts, like where they live, how big their family is, or what kind of home they have.
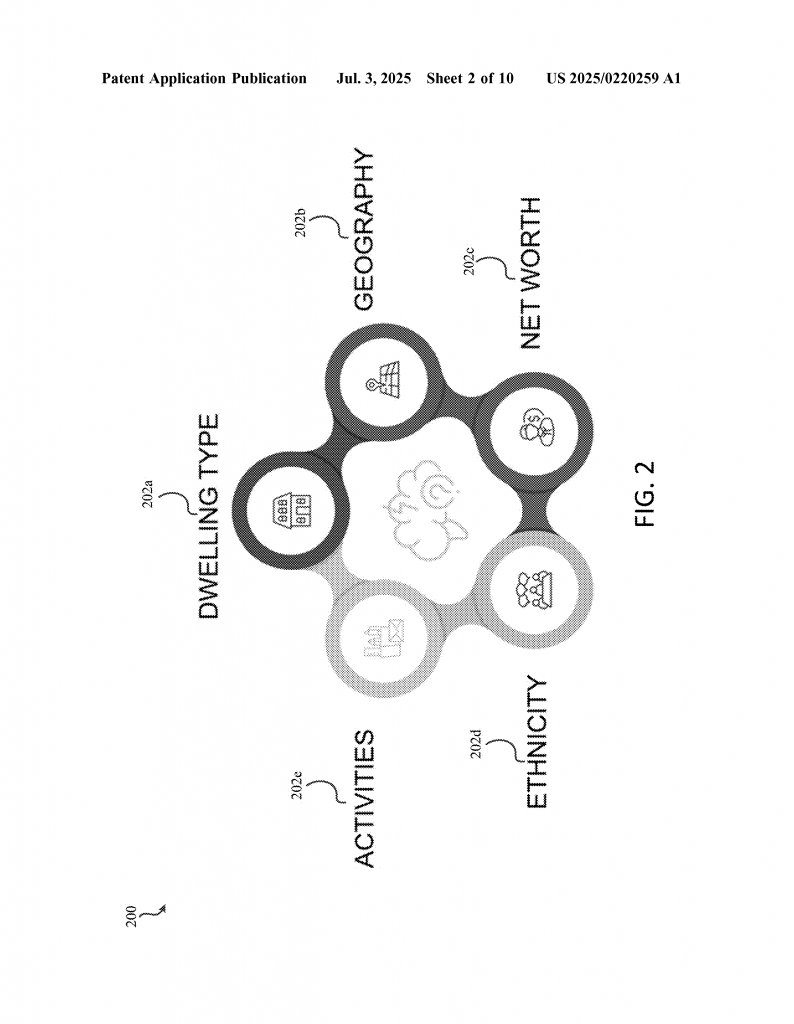
Here’s where the process gets clever. The system compares the unknown home to the known homes, looking at as many features as possible. These features can include things like:
- Dwelling type (house, apartment, etc.)
- Ethnicity
- Geography (city, state, zip code)
- Net worth and income
- Household size and composition
- Spending habits
- Occupation
- Number and type of devices in the home
Instead of just looking at one or two features, the system lines up many at once. It then finds a group of known households that are most similar to the unknown one. To measure similarity, it uses something called “distance”—not the kind you measure with a ruler, but a way to see how close two homes are based on all these features. The smaller the distance, the more alike they are. Sometimes it uses mathematical formulas like Euclidean distance or cosine similarity, but you don’t need to know the math to get the idea.
Once it has this group of lookalike households, the system looks at their viewing habits. If most of them spend a lot of time watching family movies on weekends, the system predicts the unknown home probably does too. It can also average things out—for example, if the group watches two hours of kid’s shows a day, that’s the guess for the unknown home.
But there’s a twist. Sometimes, the known data isn’t complete. For example, if you only have data from one device in a home, but the home actually has three devices, you might be missing a lot. People might watch shows on a device you don’t see. If you don’t fix this, you’ll undercount what the household really watches.
To solve this, the invention brings in national data—bigger surveys or research that show, on average, how many devices households have. If your known group is mostly single-device homes but the real country has lots of multi-device homes, the system adjusts by giving more weight to the homes with two or three devices. Think of it like turning up the volume on those households so they count more in the average.
The system can also fix other imbalances. For example, maybe your known data says only 3% of homes watch over-the-air TV, but national data shows it’s really 14%. The invention “calibrates” the results so they line up with the truth. This might mean pretending some single-device homes really have more devices, or randomly assigning some extra viewership to fill the gap.
On top of all that, the system can be used in reverse. Maybe an advertiser knows a group of homes are heavy sports watchers and wants to find more homes like them. They give the system a “seed” list, and the method looks for other homes that match the same features. It can even score each home based on how likely it is to fit the target group, so advertisers can focus on the best prospects.
The system is also flexible. It can use different features depending on what you’re trying to predict. If you’re looking for heavy mobile users, spending habits might matter more. If you’re looking for news watchers, age or occupation might matter more. The system adjusts its comparisons to fit the problem.
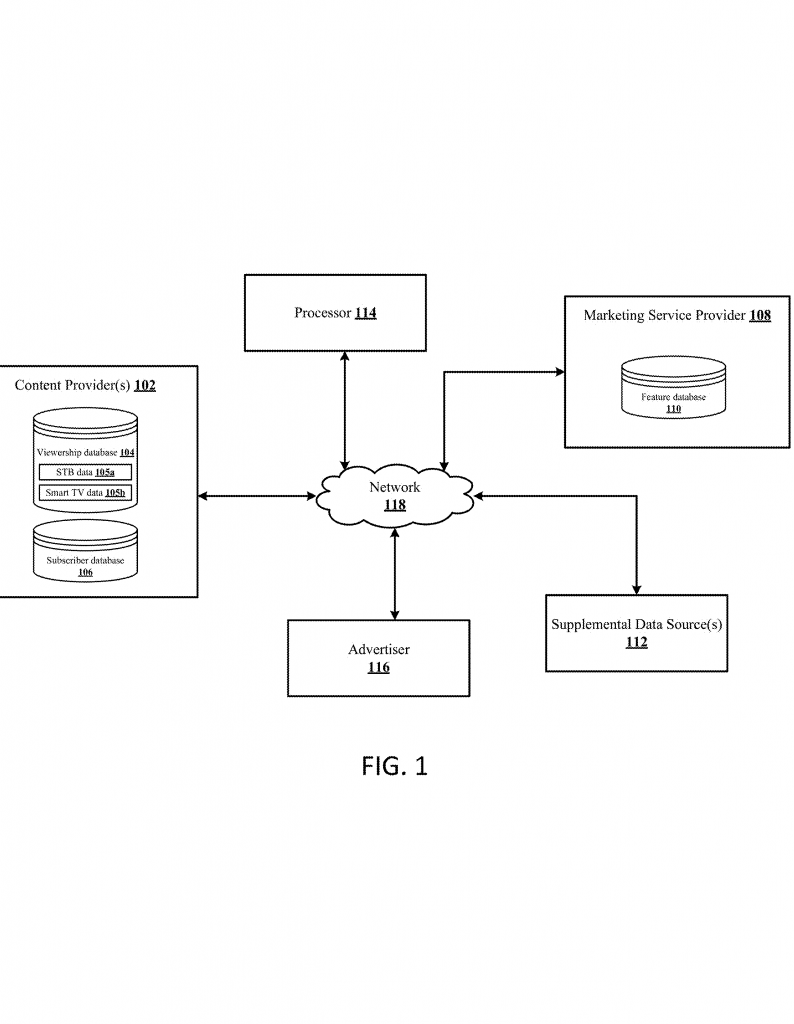
Once the predictions are made, the system can send the results to advertisers, networks, or other parties. This helps everyone make smarter choices—showing the right ad, picking the right content, or understanding who’s really watching.
Let’s look at a simple example. Suppose you want to know if a new household in Texas is likely to watch a lot of sports. You don’t have their viewing data, but you know they live in a three-bedroom house, have two kids, both parents work, and they have three TVs. The system finds similar homes in its known group. If those homes mostly watch sports on weekends on multiple devices, the system predicts the new home does too. If the known group is missing some device data, the system uses national stats to adjust the prediction, making it more accurate.
In summary, the invention’s key innovations are:
- Using many features at once to find the best matches between known and unknown households.
- Measuring similarity with smart mathematical tools.
- Adjusting for missing data by using national device and viewing statistics.
- Calibrating results so predictions match real-world patterns.
- Scoring and ranking households by how likely they are to fit a target group.
- Flexible use for different types of content, devices, and user needs.
All of this adds up to smarter, more accurate predictions about what households are likely to watch—even when you don’t have their full viewing history. This benefits advertisers, networks, and viewers alike by making media more relevant and engaging.
Conclusion
Predicting what people like to watch is no easy task, especially when you don’t have all the data. But with the method described here, companies can make much better guesses using the information they do have. By comparing many features, filling in gaps with national data, and making careful adjustments, this invention offers a new level of precision in household content predictions.
For marketers and networks, this means more effective advertising and programming. For viewers, it leads to a better, more personalized experience. The approach is smart, flexible, and ready for the complex world of modern media. As homes continue to diversify their viewing habits and devices, smart prediction systems like this one will be more important than ever.
If you’re looking to stay ahead in the fast-changing world of media and advertising, understanding and using these advanced prediction methods is a must. They help close the gap between what you know and what you need to know—making every message, ad, or show more likely to find its perfect audience.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250220259.

