NETWORK-ACCESSIBLE MACHINE LEARNING MODEL TRAINING AND HOSTING SYSTEM
Invented by Faulhaber, JR.; Thomas Albert, Stefani; Stefano, Thomas; Owen

Welcome! Today, we are going to dive deep into an exciting patent about a system that helps people build, train, and use machine learning models over a network. This technology lets users train models on powerful computers without owning them, and use those models for predictions whenever needed. In this post, we will explore the world this invention lives in, the science and earlier solutions behind it, and finally, break down what makes this invention unique and important.
Background and Market Context
Imagine you are a teacher who wants to help many students with homework at the same time. You have only one desk and one set of books, so it’s hard to help everyone at once. Now, picture a library with many desks and books. Any student can come in, pick a desk, and use the books they need. When they finish, they leave, and another student can use the same desk. This is a lot like how computers work in big companies and data centers today.
Years ago, companies had to buy big, expensive computers to do hard work like training machine learning models. These models learn from lots of data and need powerful machines to work well. If someone needed to train a model, they had to set up everything themselves, from buying the right computer parts to installing special programs. It was slow, costly, and not easy for most people.
As more businesses and people wanted to use machine learning, it became clear that not everyone could afford or manage these big computers. Cloud computing changed this. With cloud computing, a person or company can use computers over the internet, paying only for the time and power they use. Many users can share the same physical computers by running “virtual machines”—these are pretend computers that work like real ones, but many can run on one actual machine.
With this shift, the idea of a “network-accessible machine learning service” was born. These services let anyone train, update, and use machine learning models from anywhere, using shared computers in the cloud. This made it easier and cheaper for people to use advanced technology. Companies could offer powerful tools to many customers at once, without each customer needing to buy their own hardware.

Today, this approach is used by big tech companies and startups alike. It lets people work faster, save money, and be more creative with their data. But even with these advances, there were still problems. Traditional services often only worked with one type of model or expected data in a specific format. If someone wanted to use a new kind of model or data, they were stuck. There was a need for a more flexible, easy-to-use system that could handle many types of models and data, and let users make changes quickly as they learned new things.
Scientific Rationale and Prior Art
To understand why this invention matters, let’s look at how machine learning has been handled in the past. Machine learning is like teaching a computer by showing it lots of examples. The computer figures out patterns and can then make predictions or decisions on new information. Training these models takes a lot of power and memory, especially with big data sets.
Before cloud computing, training a model meant setting up a powerful computer, installing all the right programs, and making sure everything worked together. This was hard, slow, and often required special knowledge. If a person wanted to try a new idea, like changing how the model learns or using different data, they often had to start over or make big changes to their setup. If they wanted to stop and pick up later, or try several models at once, it was even harder.
Virtualization—a way to make many pretend computers on one real machine—helped a lot. Now, companies could run many jobs on one physical computer, keeping them separate and safe. Cloud providers took this further, letting anyone use these virtual machines over the internet. Services like Amazon Web Services, Microsoft Azure, and Google Cloud started to offer machine learning tools. But there were still limits. Many services only worked with certain models or needed data in a special way. If someone wanted to use a new kind of model or language, they often couldn’t.
Another big step was the use of “containers.” Containers are like lunchboxes for code—they keep everything the program needs in one place, so it works the same anywhere. With containers, people could package up their machine learning code and be sure it would run the same way on any computer. This made sharing and scaling models much easier. But, even with containers, it was hard to manage the process of starting, stopping, or changing training jobs in the cloud. It was also tough to run different models or handle changes in the middle of training.
Earlier patents and systems tried to solve these problems but had limits. They often required users to fit their work into a tight box: only certain model types, only certain data formats, and little ability to change things on the fly. If a user wanted to change the model’s “hyperparameters”—settings that control how it learns—or switch to a new kind of model, they had to start from scratch. Running many jobs at once was sometimes possible, but not easy or flexible.
There was a clear need for a system that let users send in their own model code and data, no matter the type or language, and have the service handle all the hard parts. The system should let users tweak settings, update code, or even switch models during training, all without stopping everything or losing their progress. It should also let users run many models at once, split the work across several machines if needed, and check how well their models are doing as they train.
Before this invention, users spent too much time setting up computers, dealing with errors, or waiting for their turn. They couldn’t easily change their minds or try new ideas. The process was slow, rigid, and not friendly for people who wanted to experiment and learn quickly.
Invention Description and Key Innovations
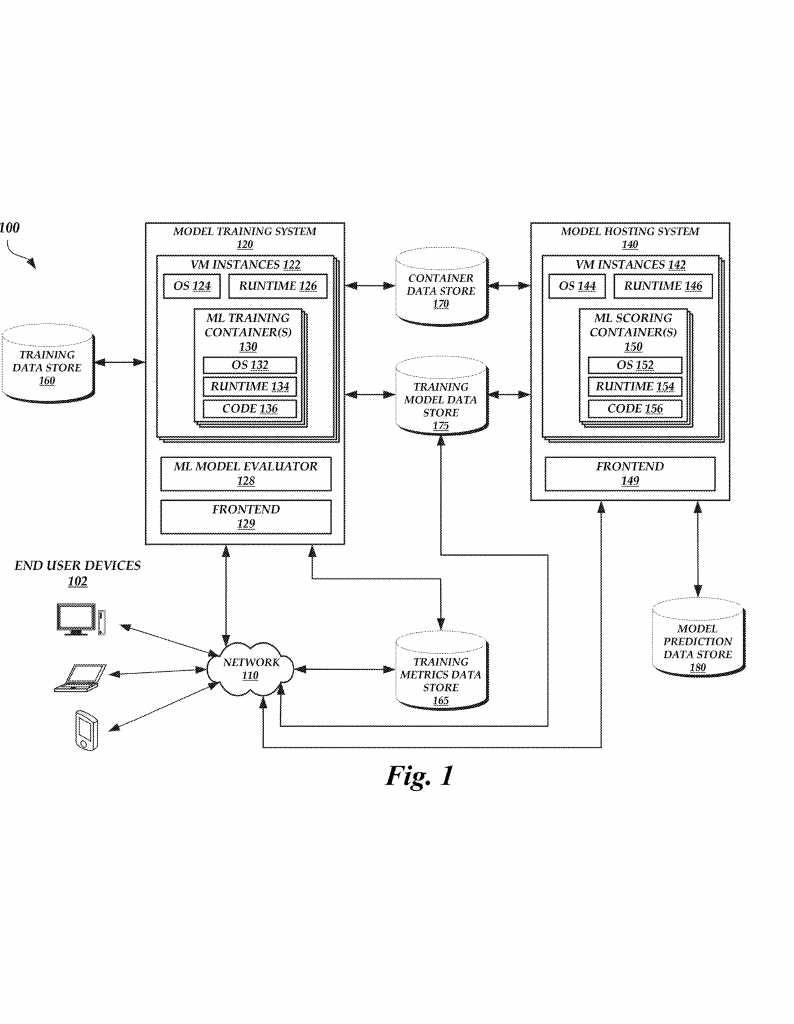
Now, let’s walk through what this patent brings to the table. The system described in this patent acts like a smart library for machine learning. It offers a network-accessible service where users can send in requests to train, change, and use machine learning models, all handled by powerful backend computers. Here’s how it works, step by step, using simple language.
First, a user (this could be a person or a business) sends a training request from their device—maybe a laptop or a phone. This request tells the system where to find the container image (the lunchbox of code), where to find the training data, and any special settings (hyperparameters) for training. The request might also say what kind of computer is needed—does it need a lot of memory? Does it need a special graphics chip (GPU)? The system reads the request and gets to work.
The system then starts up a new virtual machine, like opening a fresh desk in our library. It loads the container image into a special space called a training container, which is kept separate from everything else. This container has everything needed to run the model code. The system then gives the container the training data and starts training the model, using the settings provided. As the model learns, it creates “model data”—the rules and numbers that describe what it has learned so far.
One of the clever parts of this invention is how it lets users change things without stopping everything. If the user wants to tweak how the model learns, switch to a new version of the code, or even change the whole model, they can send a modification request. The system can swap out the code or settings, update the container, and keep going. This makes it easy to experiment and improve models without wasting time or losing work.
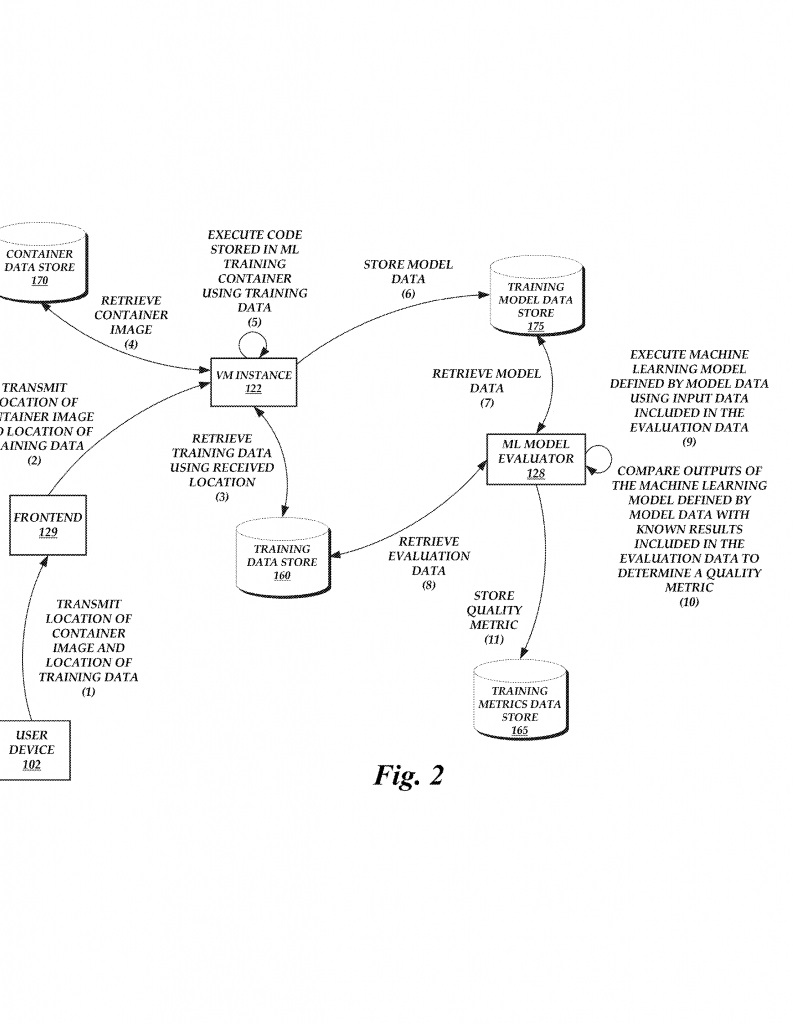
The system also keeps track of how well the model is doing as it trains. It can pause at many points, check the model’s quality using special test data, and store these results. Users can look at these quality checks to decide if they want to keep going, make changes, or stop early. This saves time and helps users avoid training bad models.
Another big feature is parallelism. The system can train several parts of a model at the same time, across many containers or even many virtual machines. This is like having many students working on different chapters of a book at once, then sharing what they learned. It makes training faster and more scalable, so even very big models with lots of data can be handled quickly.
When the model is ready, the user can ask to deploy it for predictions. The system creates a new container (called a scoring container) and loads the trained model data into it. When the user wants to get a prediction—say, to find the best move in a game or the likely price of a house—they send an execution request. The system runs the model code in the scoring container using the new data and sends back the result. All of this happens over the network, so the user doesn’t need to own or manage any of the hardware.
The system is also very flexible. It works with any kind of model code, written in any language, and with any data format. Users don’t need to rewrite their code or change their data to fit a special system. They can use off-the-shelf models, models they wrote themselves, or even models from a marketplace. The system handles all the messy work of setting up, running, and managing the training and prediction jobs.
Some more key points:
– The system can store many versions of a model as it trains, letting users pick up from an earlier point if needed.
– It can automatically scale up or down, handling many users and jobs at once without slowing down.
– It can handle groups of related models, passing results from one model to another as needed.
– It keeps everything secure and separate, so users’ data and models don’t get mixed up.
– Users can interact with the service through different tools—command lines, apps, or web interfaces—making it accessible for beginners and experts alike.
All of these features work together to create a system that is powerful, easy to use, and open to many kinds of users. It lets people focus on solving problems and being creative, instead of fighting with computers and code.
Conclusion
This patent for a network-accessible machine learning model training and hosting system is a big step forward for everyone who wants to use machine learning. By letting users send in any kind of model code and data, make changes on the fly, train many models at once, and deploy them for predictions—all over the network—it opens up new possibilities for businesses, scientists, and students. The invention takes away the hardest parts of machine learning work and makes it as easy as sending a request and getting results. In a world where data is everywhere and the need for smart tools is growing fast, this system stands out for its flexibility, power, and ease of use.
If you are exploring machine learning, this kind of technology means you can move faster, try new ideas, and get better results, all without worrying about the heavy lifting in the background. The future of smart computing is here, and it’s more open and friendly than ever before.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217699.

