SYSTEM AND METHOD FOR CORRELATING VIRTUAL MACHINE INTERRUPTIONS AND NODE CHARACTERISTICS

Invented by Park; Chin Hwan, Gustafson; Adam Marc, Harris; William, Bhimanadhuni; Ramakoti R., Sierra; Jessica Dean, Ko; Li-Fan, Swanson; Nicholas Anthony, Zheng; Lingling, Benge; Cristopher, Jiang; Siduo, Dagli; Yash Jayesh, Ajayi; Kehinde, Mehr; Maryam Nikouei, Jin; Meng

Cloud computing is everywhere now. It helps businesses run fast and scale up or down as needed. At the heart of this are virtual machines (VMs), which let many users share the same hardware safely. But sometimes, these virtual machines stop working. That is a problem, especially when you need things to run all the time. A new patent application offers a powerful way to find out why VMs stop and how to fix it. This article will help you understand why this matters, how this solution is different from past methods, and what makes this invention special.
Background and Market Context
Cloud computing is now the engine for much of the world’s digital services. From streaming videos to banking and health care, almost everything relies on servers running in the cloud. These servers often use virtual machines. Virtual machines let one big computer act like many smaller computers, so each customer can have their own space, software, and data, all kept separate.
Cloud providers, like Amazon, Microsoft, and Google, want to keep their customers happy. That means making sure their virtual machines are always up and running. But sometimes, things go wrong. A virtual machine might crash, run slowly, or even stop altogether. When that happens, businesses can lose money, customers can get angry, and trust in the cloud can drop.
Because of this, cloud companies work very hard to track how often VMs go down. This is called the “interruption rate.” They watch for patterns, like how many times a VM goes down compared to how long it was running. But just counting these numbers is not enough. It might show that something is wrong, but not why it’s happening.
One big challenge is that sometimes, when one piece of computer hardware (like a server node) fails, it can take down many virtual machines at once. Just looking at the total number of interruptions doesn’t show the full picture. It’s kind of like seeing all the lights go out in a city block and not knowing if it was one house or the whole power grid that failed.
Another problem is figuring out if the cause is in the software (like the programs running inside the VM) or the hardware (like a broken memory chip or power supply). Without knowing the cause, it’s hard to stop these problems from happening again.
As cloud computing gets bigger and more important, these problems get harder to solve. There are thousands, even millions, of virtual machines running at once, each with different setups and needs. Some use lots of memory, some use lots of storage or special chips for fast math. Each one has its own risks and weak spots.
This growing complexity means that just tracking basic uptime and downtime doesn’t help enough. Cloud providers need smarter ways to see patterns, find root causes, and fix issues before they become big problems. They want to know not just how often VMs go down, but why, and what can be done to prevent it. That’s where the new patent comes in.
Scientific Rationale and Prior Art
Let’s look at how cloud companies have tried to solve VM interruption problems in the past. Usually, they track when a virtual machine goes down. They keep logs of these events and measure how often it happens compared to the total time the VM was running. This gives a simple number—an “interruption rate.”
This number is helpful. It lets companies compare different cloud providers or different types of virtual machines. But it doesn’t say much about what actually caused the interruption. It’s like knowing your car broke down 3 times last year, but not knowing if it was the engine, the tires, or the battery.
Some systems collect more details, like log files or crash dumps. A log file keeps track of what a system was doing before it failed. A crash dump grabs a snapshot of the system’s memory and software state at the moment of the crash. These give clues about what might have gone wrong, but they usually focus only on the software side.
The hardware side—the physical parts like memory chips, processors, and network cards—also matters. But most older systems didn’t tie together the events from the VM with the exact state of the hardware at that moment. Or, they’d just look at hardware health in a general way, without linking it to specific VM failures.
When a hardware node fails, every VM running on it often fails too. Past systems sometimes missed this, or treated each VM failure as a separate event, even though they all had the same root cause. This made it hard to see patterns, like if a certain type of memory chip was causing lots of problems, or if a special kind of virtual machine was more likely to fail on certain hardware.
Some companies tried to group interruptions by time or by hardware, but usually in a very basic way. They might see that a server rebooted and caused all its VMs to go down, but they wouldn’t connect that to the brand or model of the hardware, or to the type of VM running at the time.
These limitations meant that root-cause analysis—the process of finding out why something failed—was slow and often not very accurate. It was hard to predict which combinations of VMs and hardware were most risky. It was even harder to use this information to make things better, like moving sensitive VMs to safer hardware, or avoiding bad combinations of hardware and software.
The scientific idea behind the new patent is to collect detailed data from both the virtual machine and the hardware node, right at the time of the interruption. Then, by looking for patterns and links between the two, the system can find out if certain VMs are sensitive to certain hardware, or if some hardware parts cause more problems than others.
This is a step forward from just counting failures. It’s more like detective work—gathering clues from both sides and using them together. By doing this, cloud providers can spot hidden problems, catch trouble before it spreads, and make smarter decisions about where to run each VM.
Another difference is that this new method can dig deep, down to the level of individual hardware parts—like specific brands, models, or even serial numbers. It can look at how different VM setups (like those needing lots of memory or special graphics chips) behave on different types of hardware. It can even use advanced math and machine learning to find patterns that people might miss.
In short, while older systems saw only part of the problem, this new approach sees the whole picture. That means better uptime, fewer surprises, and happier customers.
Invention Description and Key Innovations
Now, let’s talk about what this patent application actually does, and why it stands out.
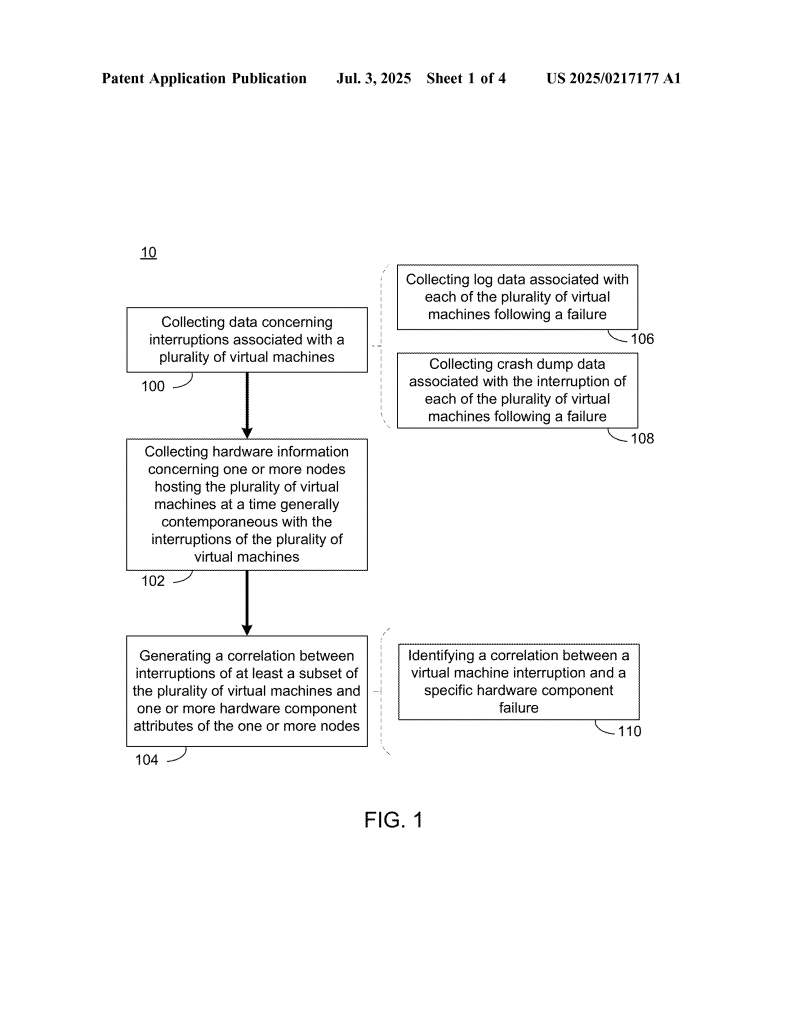
The invention is a smart way for a computer system to watch over lots of virtual machines and the hardware nodes that run them. It works in three main steps:
First, it collects detailed data every time a virtual machine is interrupted. This includes not just the basic fact that a VM went down, but also log files and crash dumps. These show what the VM was doing, what software it was running, and its settings—like how much memory or storage it had, and what type of VM it was (for example, general purpose, memory-heavy, or GPU-accelerated).
Second, it grabs hardware information from the node hosting the VM, at almost the same time as the VM interruption. This hardware data is very detailed. It shows if any hardware parts failed or had errors, and the state of each part—such as the processor, memory, storage, network cards, and power supply. It even records details like the maker, model, generation, and SKU (stock keeping unit) of each part.
Third, the invention uses this combined data to find links—called correlations—between VM interruptions and hardware attributes. It looks for patterns, like whether certain types of VMs are more likely to be interrupted when running on nodes with specific hardware. It can even zoom in to see if a certain brand or model of memory chip, for example, is tied to more VM failures.
This is not just theory; it’s very practical. The system can find out if a memory-heavy VM is more likely to crash on servers with a certain kind of RAM, or if compute-heavy VMs have problems with certain processors or network cards. If strong patterns are found, the system can act on them—like avoiding those risky combinations in the future, or moving VMs to safer hardware before trouble happens.
Let’s look at some of the nitty-gritty details and unique features of this invention:
– The system watches for all kinds of VM interruptions, from small slowdowns to total crashes and reboots. For each event, it records the full context, including the VM’s configuration and the hardware’s status.
– It combines real-time data (what’s happening right now) with historical data (past logs and crash dumps), giving it a big pool of clues to work with.
– It’s not just about finding if a VM failed, but about finding which combination of VM and hardware is most likely to fail. For example, maybe a certain kind of high-memory VM is fine on one brand of server, but not on another.
– The invention collects data down to very fine levels, such as the exact model and SKU of every hardware part. This lets the system spot issues that might only happen with certain batches or versions of hardware.
– It uses smart math and modeling, like statistical analysis and machine learning, to find these patterns. It can even adjust its models if the data shows that some nodes or hardware types are related (not fully independent), making its predictions more accurate.
– The system can use what it learns to take action. If a risky combination is found, it can move VMs to safer nodes, avoid bad pairings in the future, or even suggest changes to how hardware is bought and installed.
– By linking VM events with hardware events down to the component level, the system can help with root-cause analysis much faster. This helps tech teams fix problems sooner and avoid repeat failures.
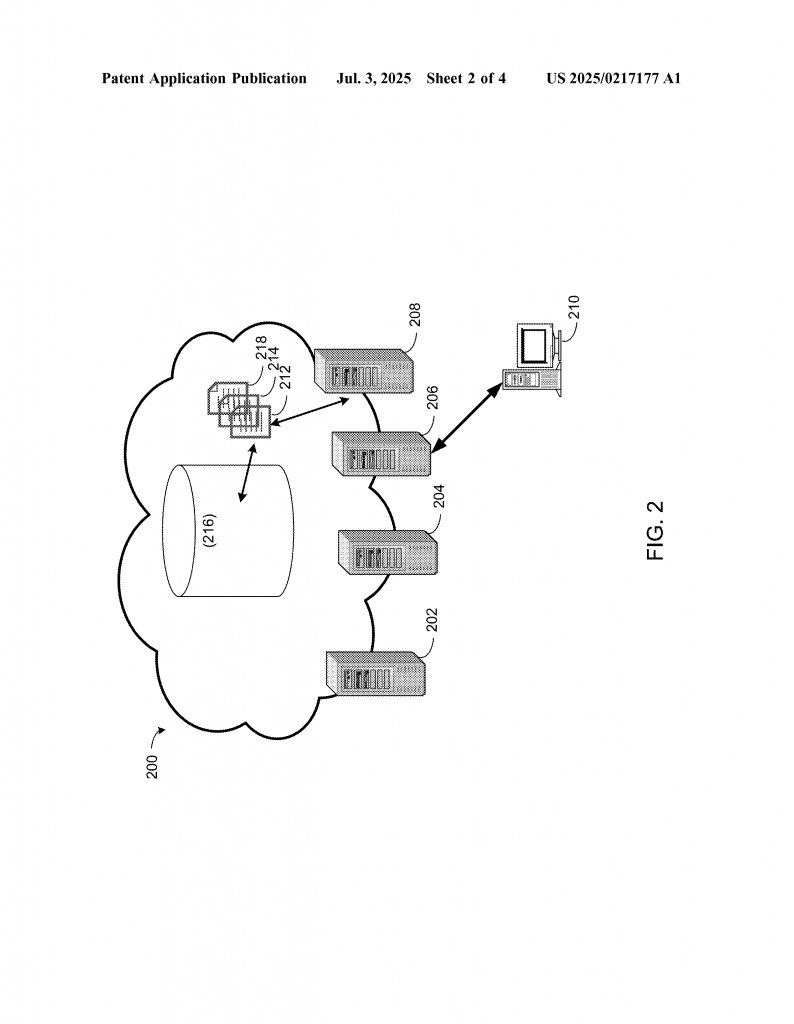
– The invention can be implemented as software running on servers, or as a computer program installed on any kind of computer or cloud system.
– It also supports many different operating systems and hardware setups, making it flexible for use in any cloud or data center.
– The system is built to scale. It can handle tracking and analyzing data from thousands or even millions of VMs and nodes at once.
– Finally, it is not limited to just fixing problems after they happen. By learning from past data, it can predict which combinations are risky and prevent problems before they start.
What makes this invention truly special is how it brings together all the puzzle pieces. Instead of just looking at VMs or hardware alone, it connects them. It can pinpoint which virtual machines are most sensitive to certain hardware traits, and which hardware parts are most likely to cause trouble for certain types of VMs. This kind of insight was not possible with older, less detailed tracking systems.
This means cloud companies can make smarter choices about how they set up, run, and maintain their systems. They can promise better uptime to their customers, save money by avoiding unnecessary hardware swaps, and keep their systems running smoothly.
Conclusion
Virtual machine interruptions have always been a big challenge for cloud providers. Just counting how often they happen is not enough. To truly solve the problem, you need to know why they happen and how to stop them.
This new patent application brings a smarter way to connect the dots between virtual machine failures and the hardware they run on. By collecting rich data from both sides and looking for patterns, it gives cloud companies the tools they need to see the real causes of problems and take action to prevent them.
With this invention, the cloud can become more reliable, efficient, and predictable. Customers will see fewer interruptions, and providers can offer better service. In the fast-moving world of cloud computing, that’s a big step forward.
If you manage virtual machines, build cloud systems, or just care about uptime and reliability, this is an innovation worth watching. It could very well shape the future of how we keep our digital world running smoothly.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217177.

