EFFICIENT AND EFFECTIVE SYSTEM AND METHOD TO BUILD MULTI-LINGUAL LARGE LANGUAGE MODELS
Invented by Wang; Hai, Tang; Zheng, Srinivasan; Vijay, Kwon; Hyuk Joon, Yadav; Vikas, Wang; Feixuan, Jin; Hongxia
Building smart computers that talk and understand people is no longer science fiction. Today, large language models (LLMs) are behind many tools we use, from chatbots to translation apps. But making one language model work well in more than one language is still very hard. This article will help you understand how new inventions are making it easier, cheaper, and faster to teach these models new languages without starting over from scratch.
Background and Market Context
Let’s start with the big picture. LLMs, like the ones behind popular AI chatbots and digital assistants, have changed how we use technology. They summarize news, answer questions, write code, and even help with math. Originally, these models were trained for just one language, usually English. But the world needs more. People want to use these smart models in every language, from Spanish and Chinese to Korean and beyond.
In the past, if a company wanted an LLM that spoke two or more languages, they would need huge sets of text in every language and massive computer power. Training just one LLM from scratch could cost millions of dollars and take weeks or even months. Very few companies could afford this. That left most of the world stuck with models that only worked well in English or a few other big languages.
The problem is not just about reaching more people. Many businesses, schools, and hospitals need tools that can read, write, and understand local languages. Governments want their people to have smart assistants that understand their laws and culture. Even everyday users want to type or speak in their own tongue and get good answers back. The market is huge, but the cost and effort to make these models truly multilingual are huge as well.
Imagine a small business in Korea wanting a chatbot for customer service. If they had to build and train a new LLM, it would be too expensive. But if there was an easier way to take a model that already works in English and teach it Korean, more people could use these tools. That’s why inventors are looking for smarter ways to “teach” LLMs new languages without starting from zero.
The invention we’re talking about here tackles this very problem. It explains a new, clever way to make English-trained LLMs learn other languages step by step, saving time, money, and computer power. It’s designed to keep the model strong in its first language while adding new ones, instead of making it weak or forgetful. This is opening the door for more businesses, schools, and even governments to use AI in their native language, making technology fairer and smarter for all.
Scientific Rationale and Prior Art
Now let’s look at how language models have worked until now, and why teaching them new languages has been so hard. Most LLMs learn by reading huge amounts of text. They break words into small pieces called tokens. For example, “dog” is a token, but so is “do” or “g.” The model learns to guess the next token in a sentence by looking at all the tokens before it. The more it reads, the smarter it gets.
The problem comes when you want to add a new language. Each language has its own set of words, rules, and even characters. If you trained your model in English, it might not understand how to break up or “tokenize” a word in Korean or Arabic. And even if it could, it would have no idea what those words mean unless it read millions of sentences in that new language.
The “old way” to make a multilingual model was to start over with all your languages mixed together from the start. This meant collecting massive amounts of text in every language you want, mixing them, and training a brand-new model. It’s like filling a giant library with books in every language and making your AI read all of them at once. This takes a huge amount of data, powerful computers, and lots of time. Only big tech companies could afford it.
Some people tried to add languages to existing models by just feeding them sentences in the new language, hoping the model would learn. But this was not very effective. The model’s “vocabulary” (the tokens it knows) didn’t fit the new language well. For example, an English-trained model might break up a Korean word into many tiny, meaningless tokens, making it very slow and inaccurate. The model would also mix up the new language with the old one, losing some of its original skills.
Other tricks included using parallel texts (sentences in two languages that mean the same thing) for translation tasks, but these did not solve the main problem: how to make the model’s brain (its token vocabulary and knowledge) actually “understand” the new language as well as the old one, and to do so efficiently.
There was also the challenge of “catastrophic forgetting.” When you teach the model a new language, it might forget what it learned in the first language. So, people tried various balancing acts—mixing data from both languages, tuning different parts of the model, but the results were often hit-or-miss.
To sum up, all these older methods either cost too much, took too long, or made the model weaker in some languages while adding new ones. There was a need for a method that could make an existing language model support new languages without starting from scratch, without needing huge amounts of new data, and without making it forget what it already knew. This is exactly what the new invention achieves.
Invention Description and Key Innovations
Let’s walk through how the new method works and what makes it special. Imagine you have an LLM that’s already really good at English. You want it to speak Korean, too. Here’s how the invention makes this possible, step by step.
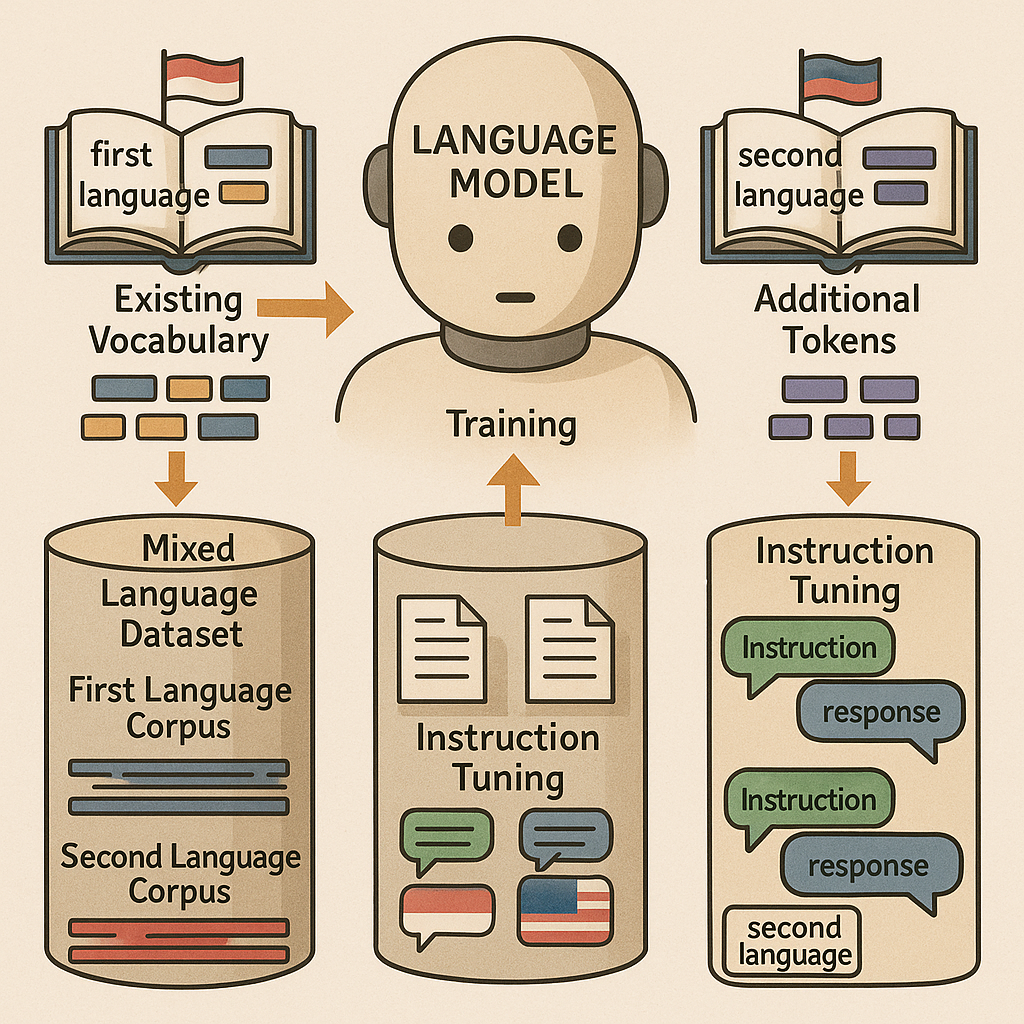
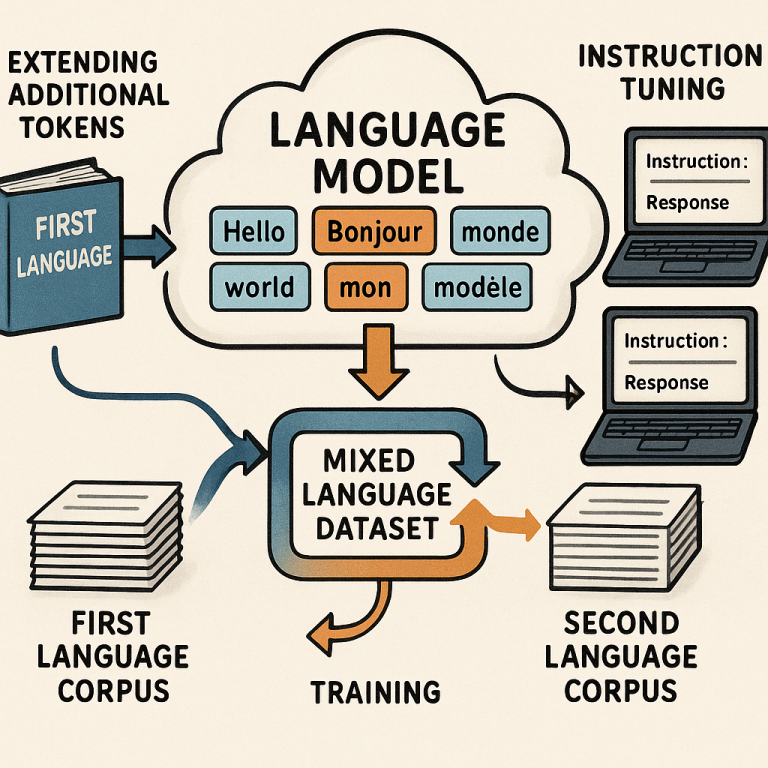
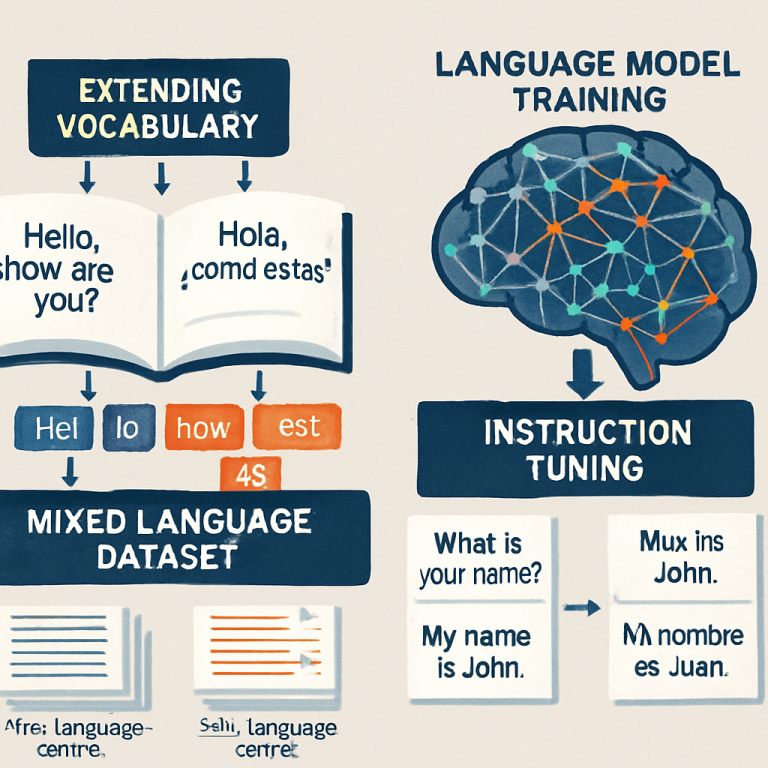
First, the method extends the model’s vocabulary. This means adding new tokens for the words and letters found in Korean. Instead of forcing the old model to break Korean words into bits that make no sense, the model now learns the real building blocks of the new language. This makes the model much faster and smarter when dealing with Korean text.
But there’s a trick. When the new tokens are added, the model needs to give them a starting “meaning”—an embedding. Instead of starting with random guesses, the invention uses the knowledge from the first language. It looks at how the original model built up the meaning of similar tokens and uses that as a starting point for the new tokens. For example, if the new Korean word shares some sounds or parts with an English word, the model can use what it knows about those parts to guess the meaning.
Next, the model is trained on a mix of English and Korean sentences. Here’s where the real magic happens. Instead of just flooding the model with Korean and hoping for the best, the method carefully balances how much English and how much Korean the model reads. This helps the model get strong in Korean, but not at the cost of forgetting English.
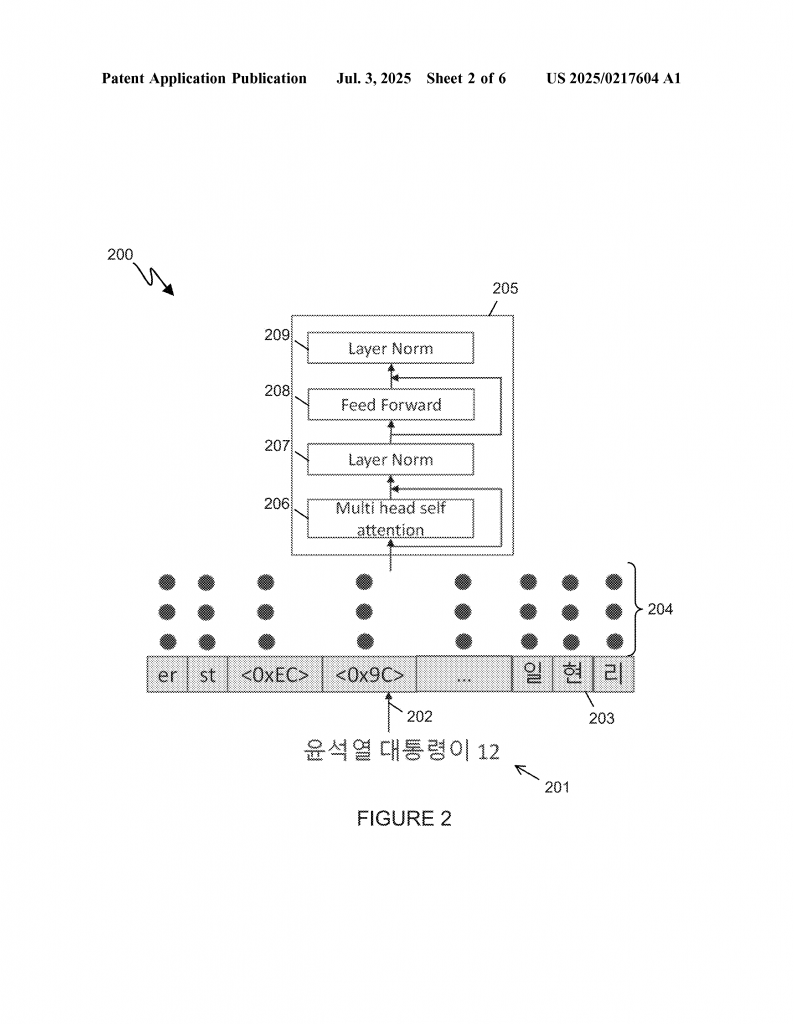
The invention even allows the ratio of English to Korean data to be tuned for best results. If the model starts to get weaker in English, you add more English data. If it’s slow to pick up Korean, you tweak the mix to favor Korean. This way, you get a model that’s strong in both languages.
But the process doesn’t stop there. After this first mixed training, the model gets a second round of fine-tuning, called instruction tuning. This means giving it lots of example questions and answers in both languages. Some of these are regular instructions, like “Translate this,” or “Summarize that.” Others are special examples that help the model learn to switch between languages smoothly. For instance, the model might be given a sentence in English and asked to finish it in Korean, or vice versa.
The invention also uses something called “machine translation parallel data.” These are pairs of sentences that mean the same thing in both languages. They help the model understand how ideas move from one language to another. Another clever trick is “conditional denoising,” where the model is given incomplete sentences with missing words and learns to fill in the blanks. This makes the model better at understanding messy or half-written sentences, which is common in real life.
Importantly, this whole process can be repeated. Once the model is strong in English and Korean, you can add Chinese next using the same method. You just extend the vocabulary again, initialize the new tokens smartly, adjust the data mix, and tune the model. This step-by-step approach means you can build a model that speaks many languages, always keeping it balanced and efficient.
The invention works not only in computers but in all sorts of electronic devices. Phones, tablets, smart speakers, and even smart home appliances can use these smarter, multilingual models. The method can be carried out by software, by hardware, or by both working together. And because it doesn’t need to start from scratch, it uses much less computing power and data than the old ways.
Tests show that this approach makes models that are just as good (or better) in new languages as models trained from scratch, but at a fraction of the cost and time. It also keeps the old language skills strong, avoiding the problem of “catastrophic forgetting.” It even makes the models faster, as they use fewer tokens to represent words in the new language, which means less waiting for answers.
To sum up, the key innovations are:
– Adding new tokens for each language, so the model truly understands new words.
– Using what the model knows about old tokens to smartly start learning new ones.
– Mixing the old and new language data just right to keep the model strong in both.
– Using special tuning data that helps the model switch and align languages smoothly.
– Allowing the process to be repeated for more and more languages, one step at a time.
Conclusion
Making language models truly multilingual has always been a tough challenge. The old way, training from scratch, was slow, expensive, and limited to the biggest companies. This new invention changes everything. By extending the model’s vocabulary, initializing new tokens smartly, and carefully mixing training data, LLMs can now learn new languages quickly and keep their old skills. The process is efficient, affordable, and scalable, opening the door for businesses and users everywhere to enjoy smart AI in their own language.
This means more people can use AI tools in their daily life, from customer service bots to smart assistants at home or work. It also means companies can reach more customers, and users can get better, faster answers in any language they choose. As more languages get added, the technology becomes more inclusive, fair, and useful for everyone. The future is multilingual, and with inventions like this, it’s closer than ever.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217604.

