SYSTEM AND METHOD FOR CENTRALIZED CRAWLING, EXTRACTION, ENRICHMENT, AND DISTRIBUTION
Invented by WHITE; Alex, SCHLER; Jonathan, P39 Tech LLC
The internet is full of useful information. Finding and understanding that information is important for many businesses and services today. This article explains a new approach for collecting website data in a smart, safe, and organized way using a centralized web crawler. We will look at why this matters, how past solutions worked, and what makes this invention stand out.
Background and Market Context
Websites are like online books full of pictures, words, and videos. Companies want to know what is on these websites so they can offer better ads, services, or products. This is why web crawlers were created. A web crawler is a computer program that visits websites and saves data for someone to use later.
In the past, every company would build its own crawler. Imagine many people trying to read the same book at the same time. This caused problems. Too many crawlers made websites slow. Some sites blocked crawlers they did not trust. Also, building a crawler takes a lot of work and money, especially if you want to collect data from many different websites, in different languages, and keep the data fresh all the time.
Security was another big worry. Each crawler was like a stranger knocking on the door of a website. Website owners did not always know who was safe and who might be trying to cause harm. Too many connections could make a website crash or open it up to attacks. Site owners and internet companies began blocking unknown crawlers or only allowing a few that they trusted.
Another challenge came from the need for real-time data. Some industries, like digital advertising, need to make decisions in just a split second. If the website is slow because too many crawlers are visiting, advertisers might miss the chance to show the right ad to the right person. This is a big deal when you only have a few milliseconds to act.
So, the market needed a better way. Companies wanted to get the information they needed, but without causing problems for websites or spending too much time and money building their own systems. They also wanted to stay safe and only use trusted sources. This invention answers those needs by using one main crawler that collects data and then shares it with everyone who needs it. This makes the process faster, safer, and easier to manage.
Scientific Rationale and Prior Art
Let’s talk about how web crawling and data extraction worked before. Early web crawlers were simple. They would visit every page and copy everything. But this meant collecting lots of junk, like ads, navigation menus, or even empty pages. Most of this data was not useful, and it filled up computers with too much information.
To make crawlers smarter, some systems started using rules. For example, only collect pages from certain websites or only collect pages with certain words. Others tried to pick out the “main content” from each page, leaving out things like sidebars or footers. But even with these improvements, each company still had to build and run its own system.
Some crawlers began working with website owners directly or through special connections called APIs. This helped a little, but there were still too many crawlers doing the same job. It was like every student in a class making their own copy of the textbook, instead of sharing one.
Another idea was to use caches, which are like a memory that stores copies of web pages. If someone wants the same data again, they can get it from the cache instead of visiting the website again. This helps, but it does not solve the problem of too many crawlers or of sharing data safely.
Data enrichment is another key idea. After collecting data, some companies would send it to special analysis systems. These systems could look at pictures and say what’s in them, check if the language is friendly, or decide if a page is safe. But usually, this enrichment was done separately by each company, leading again to repeated work and wasted resources.
The main problem with all these older solutions was that they were scattered. Each company did its own crawling, its own data cleaning, and its own enrichment. This led to waste, confusion, and sometimes even trouble for website owners. There was no single place to collect, clean, and share data in a way that everyone could trust.
This invention builds on these ideas but takes them further. It combines centralized crawling, smart data picking, caching, and flexible enrichment into one system. It also lets outside analysis systems add even more information to the data, making it richer and more useful for everyone.
Invention Description and Key Innovations
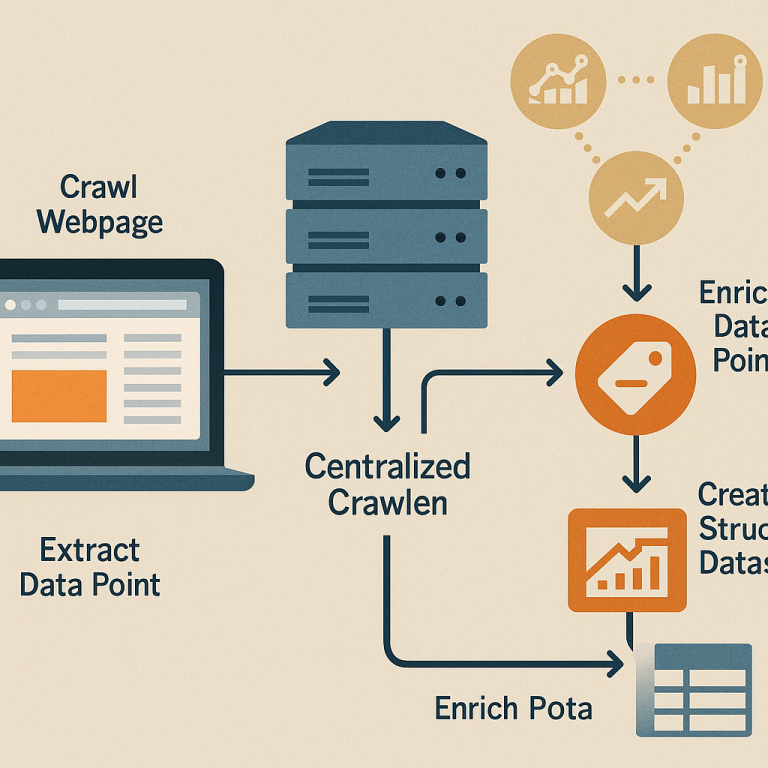
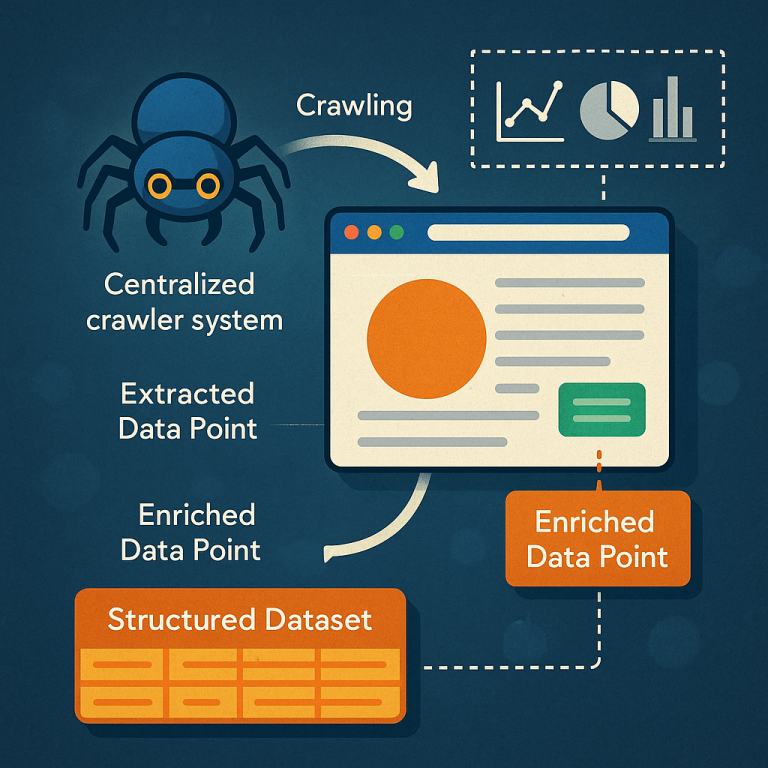
The new system is a centralized crawler. This means there is just one main program that collects data from websites. Instead of letting every company run its own crawler, this system does the job once and shares the results. Here’s how it works in simple steps:
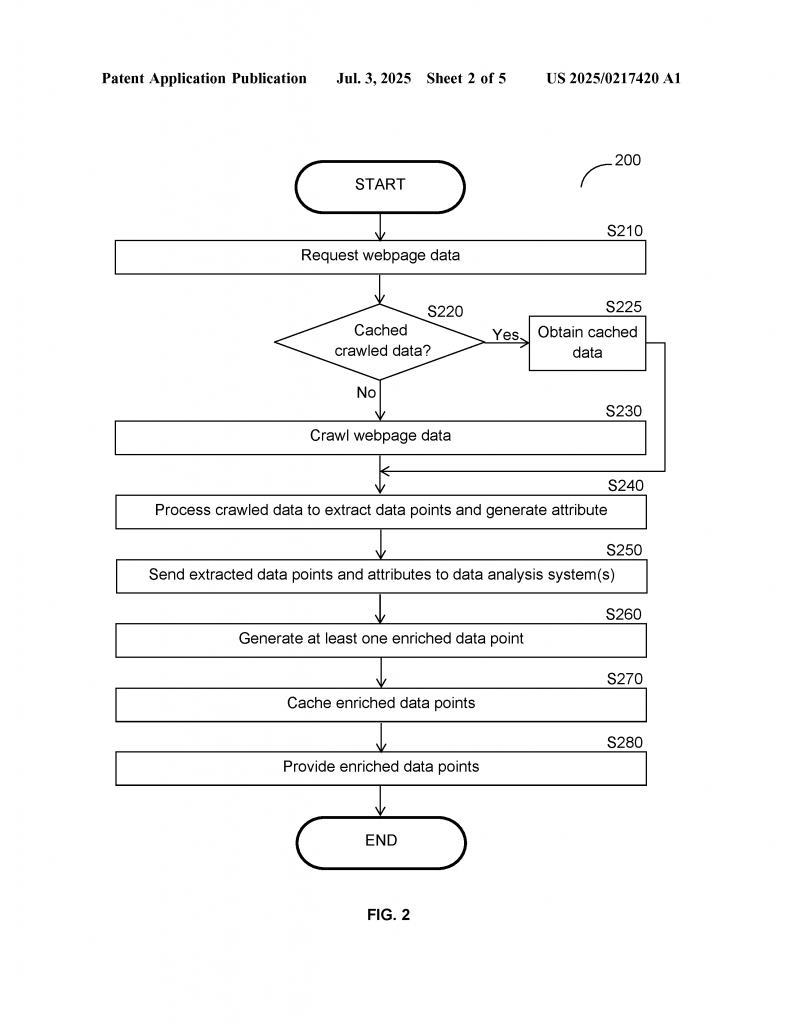
First, the crawler decides what web pages to visit. It does this by looking at rules. The rules can come from the people who want the data, from website owners, from analysis systems, or from the system itself. For example, it could crawl only popular pages, only certain topics, or only when there is a real user visiting.
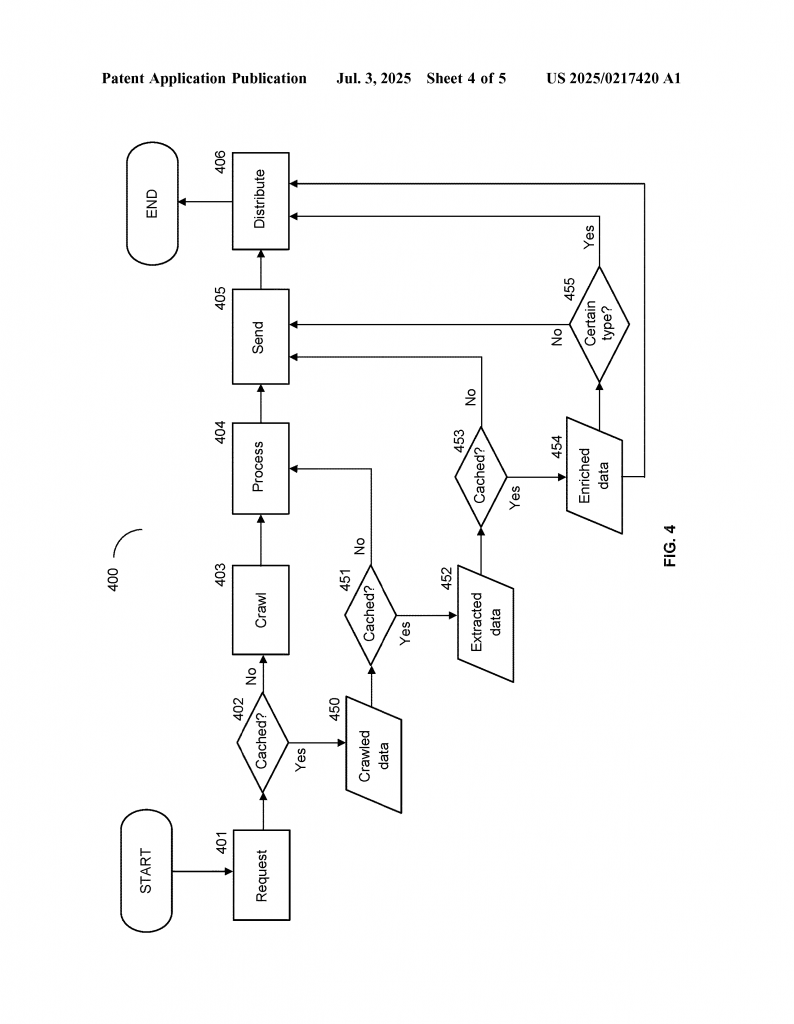
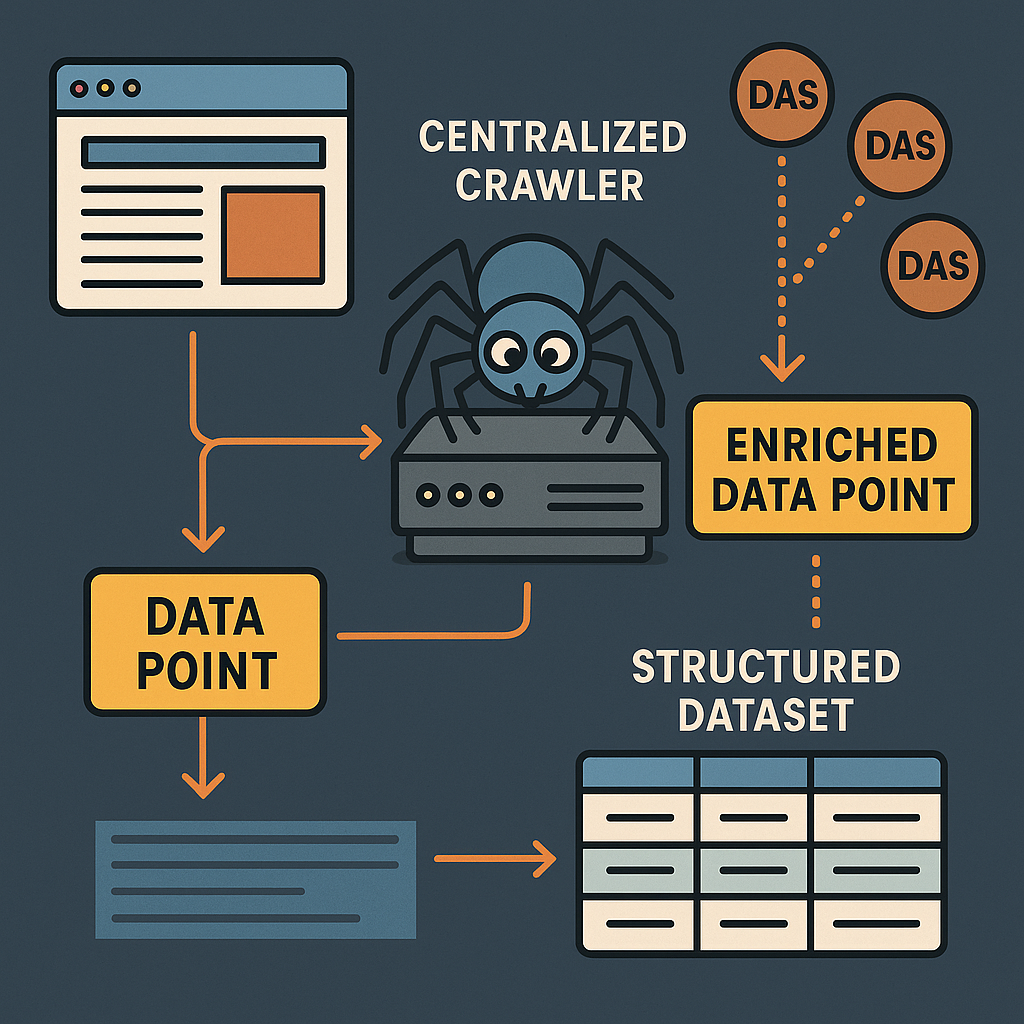
When the crawler visits a web page, it collects not just the page’s content (like words and pictures) but also extra data called metadata. Metadata tells you things like what kind of page it is, what language it’s in, or its topic.
Next, the crawler uses smart algorithms to pull out the most important parts of the page. These are called data points. For example, the main story in a news article, the key image, or the headline. This makes the data smaller and more useful, because it leaves out things like menus or ads that don’t really matter.
The system then creates a structured dataset. This means all the useful information is put into a format that is easy to search, store, and use again. If someone wants the same data later, the system checks its cache (its memory). If the data is already there and still fresh, it is shared right away, saving time and resources.
Now comes the enrichment step. The system sends certain data points to outside analysis systems. These are special programs that can add more details. For example, an image analysis system can say what objects are in a photo. A language system can tell you if the words are positive or negative. Each outside system can set its own rules about which data it gets and how often.
As more analysis is done, the system adds these new “enriched” data points to the dataset. Over time, each web page’s dataset becomes richer and more complete. If a new kind of analysis becomes available, the system can add it too, making the data even more valuable.
The invention’s cache is also very smart. It remembers not just the web page, but also the key data points and any extra information added by analysis systems. It makes sure that the data stays up to date by using refresh rules. For example, a sports news page might be checked more often than a personal blog, because it changes more.
When someone needs data, the system checks if it is already in the cache. If it is, the data is shared right away. If not, the system crawls the page, extracts data, enriches it, and then shares it. This keeps everything fast and efficient.
Security is also better. With just one trusted crawler, website owners can know who is visiting and sharing their data. This lowers the risk of attacks and keeps the internet safer for everyone.
The system is flexible. It works for websites, mobile apps, and can be set up to follow any kind of rule. It can handle different languages, topics, and types of content, from text to images and video. Because it is centralized, it can scale up to cover the whole internet or focus on just a few sites, as needed.
With this invention, companies do not need to build their own crawlers or worry about missing out on important data. They get high-quality, up-to-date information that is already cleaned and enriched, ready to use for advertising, research, or any other purpose.
Conclusion
Collecting and using web data is important for modern businesses, but the old way of doing things was slow, costly, and sometimes unsafe. This new centralized crawler system changes that. By handling crawling, data picking, enrichment, and caching all in one place, it makes the process faster, safer, and more useful for everyone. It saves time, protects websites, and gives everyone access to better, richer data. With this approach, the future of web data looks brighter, simpler, and much easier to manage.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250217420.

