Invention for System and Method for Efficient Generation of Machine-Learning Models
Invented by Austin Walters, Jeremy Goodsitt, Vincent Pham, Capital One Services LLC
Machine learning models are built using algorithms that learn from data and make predictions or decisions without being explicitly programmed. However, the process of generating these models can be time-consuming and resource-intensive, often requiring extensive computational power and expertise. This is where the System and Method for Efficient Generation of Machine-Learning Models comes into play.
This innovative system and method offer a streamlined approach to developing machine learning models, reducing the time and resources required while maintaining high accuracy and performance. It leverages advanced algorithms, automation, and optimization techniques to expedite the model generation process.
One of the key advantages of this system is its ability to handle large datasets efficiently. Traditional machine learning approaches often struggle with processing massive amounts of data, leading to longer processing times and increased costs. The System and Method for Efficient Generation of Machine-Learning Models addresses this challenge by employing techniques such as parallel processing, distributed computing, and data sampling to accelerate the model generation process.
Furthermore, this system incorporates feature selection and dimensionality reduction techniques, which help identify the most relevant and informative features from the dataset. By reducing the number of features, the system not only speeds up the model generation process but also improves the model’s performance and interpretability.
Another crucial aspect of this system is its focus on model optimization. It employs various optimization algorithms to fine-tune the model’s parameters and hyperparameters, ensuring optimal performance and accuracy. This optimization process helps eliminate overfitting, a common challenge in machine learning, where the model performs well on training data but fails to generalize to new, unseen data.
The market for System and Method for Efficient Generation of Machine-Learning Models is driven by several factors. Firstly, the increasing adoption of machine learning across industries, including healthcare, finance, retail, and manufacturing, is fueling the demand for efficient model generation techniques. Organizations are realizing the potential of machine learning in improving operational efficiency, predicting customer behavior, detecting fraud, and optimizing processes.
Secondly, the exponential growth of data is pushing businesses to find more efficient ways to process and analyze information. The System and Method for Efficient Generation of Machine-Learning Models addresses this need by offering faster and more scalable solutions, enabling organizations to derive insights from their data in real-time.
Moreover, the growing availability of cloud computing resources and advancements in hardware technology are facilitating the adoption of this system. Cloud-based machine learning platforms provide the necessary computational power and scalability required for efficient model generation, making it accessible to businesses of all sizes.
In conclusion, the market for System and Method for Efficient Generation of Machine-Learning Models is witnessing substantial growth due to the increasing demand for streamlined and scalable machine learning solutions. This technology enables organizations to leverage the power of machine learning to drive innovation, improve decision-making, and enhance operational efficiency. As businesses continue to embrace machine learning, the demand for efficient model generation techniques will only grow, making this market a promising and lucrative one for both established players and emerging startups.

The Capital One Services LLC invention works as follows
A system for determining data requirements to generate machine-learning models. The system can include one or multiple processors, and one or several storage devices that store instructions. The instructions can configure the processors to perform various operations, including: receiving a dataset and generating data categories. Generating a plurality primary models using the data of the respective data category as training data. Generating a sequence secondary models, by training the corresponding primary model with progressively less data.
![]()
Background for System and Method for Efficient Generation of Machine-Learning Models
In machine learning and artificial-intelligence modeling, training datasets are used to configure predictive and classification models. Modeling algorithms adjust parameters and customize operations to perform prediction or classification tasks using the training datasets. Hyper-parameters govern the training process. These parameters set the basic elements of the models and are not directly linked to the training data. Hyper-parameters can include, for example, the number of trees selected to govern the training of random forests. Hyper-parameters can also include the number hidden layers which govern a neural networks training.
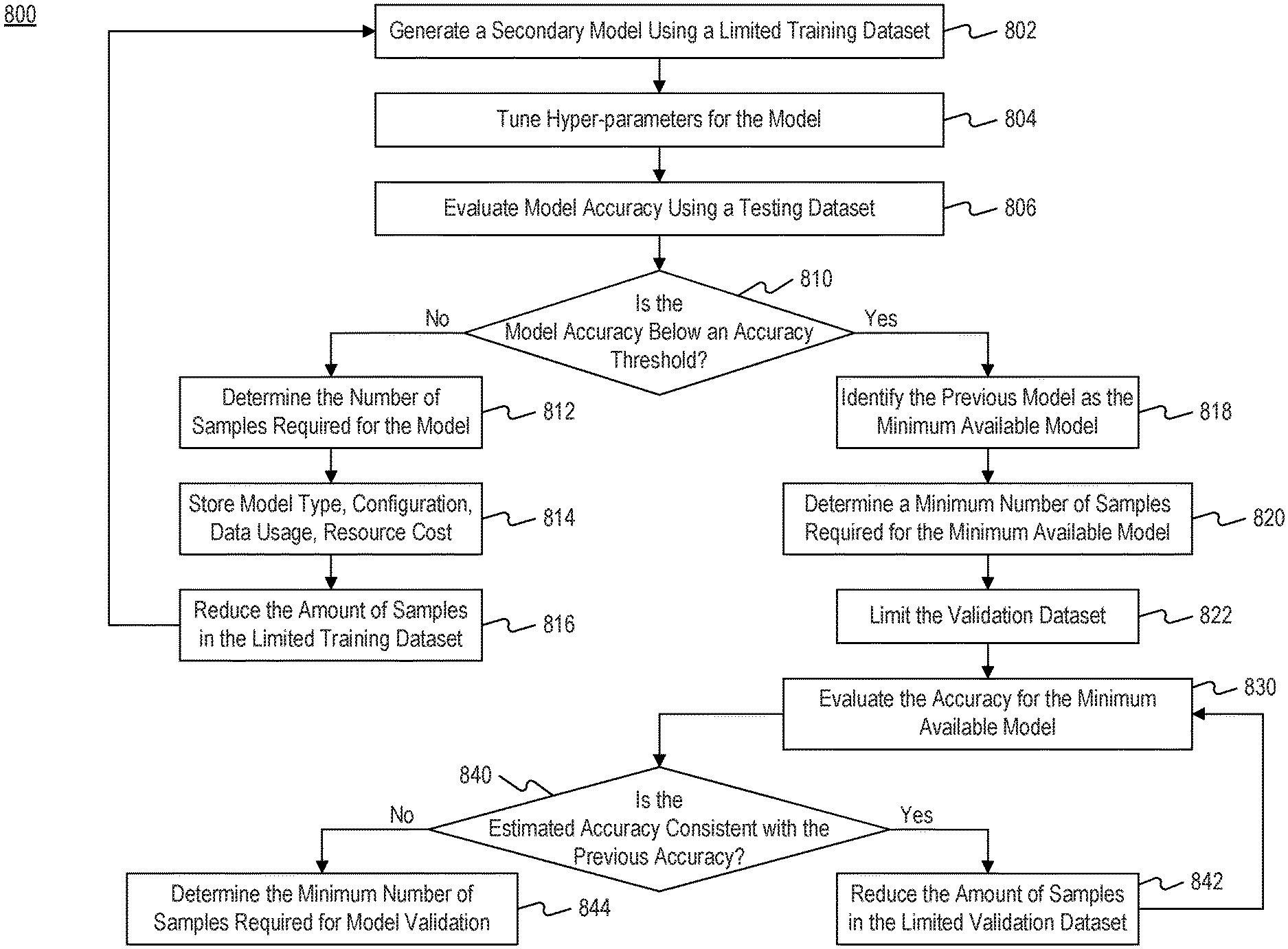
Training machine-learning models requires both hyper-parameters and parameters to be adjusted. In order to generate a predictive model, for example, hyper-parameters are selected, the parameters of the model are adjusted based on training data, the prediction is compared with validation data, the accuracy is evaluated, and the parameters may be adjusted until the target accuracy has been achieved. To achieve a successful machine-learning model, a model’s parameters are not enough. The tuning of hyper-parameters for machine-learning is an essential part of the training process. To tune hyperparameters the entire training job is repeated with different hyperparameters.
The tasks required to create machine-learning models are often time-consuming and costly. The first is that training models can be computationally expensive, as it requires large datasets with a multitude of data points. In order to adjust values in a model while processing petabytes or terabytes worth of data, expensive parallel frameworks and supercomputers are usually required. The second is that tuning hyper-parameters to a dataset can also require significant computing resources, as iterations are required for tuning. This could lead to a large increase in computer costs. Even when tuning iterations are spread across multiple processing units tuning processes still take a lot of time and consume a lot of resources. They also create complex challenges in terms resource allocation and coordination.
After training a model users often realize that computer resources have been wasted because the model failed to achieve the target accuracy, or it turned out to be “overfitted.” Overfitting occurs when a model has too many parameters in relation to the number observations and a low prediction accuracy. Overfitted models are the result of training with a large sample size or too many iterations. In such cases, parameters are too closely correlated to the training data, and the model is unable to work with independent data. Overfitted models begin to memorize the data without evaluating its general trend. Overfitted models waste a lot of computational resources. Overfitted models not only use more resources, as they require processing a large dataset for training and additional tuning iterations. They also have lower accuracy, which forces users to restart their training process using alternative configurations.
The disclosed system and method for efficient generation of machine-learning and artificial-intelligence models address one or more of the problems set forth above and/or other problems in the prior art.
One aspect” of the disclosure is a system that determines data requirements for machine-learning models. The system can include one or multiple processors, and one or several storage devices that store instructions. The instructions can configure the processors when executed to perform various operations, including: receiving a sample dataset from a database; generating data categories from the dataset; generating primary models from each data category using the corresponding data as training data. Primary models may include different model types. For each primary model, generating secondary models from training each primary model with less and less training data.
The operations may include receiving, from a database, a sample dataset including a plurality of samples; generating corresponding data categories based on the sample dataset, the data categories being associated with category data profiles; for each of the different data categories, generating varying primary models using the corresponding one of the training information, the primary models including different model types; for each one the primary models, determining progressively less training to train the corresponding one the secondary model. The operations can include receiving a sample dataset from a database including a variety of samples, generating data categories from the sample dataset and associated data profiles, and then generating primary models for each data category using the data as training data. Each primary model may have different model types.
The present disclosure also includes a computer-implemented technique for determining the data requirements required to create machine-learning models. The method can include receiving, from an online database, a dataset of samples, and creating a plurality data categories. These data categories are associated with data profiles. For each data category, it is possible to generate a variety of primary models that have different types.
The disclosure is directed at systems and methods that are efficient in generating machine-learning algorithms for prediction or classification. The disclosed methods and systems may improve model generation by estimating the minimum data requirements before training the model. In some embodiments the system can estimate the minimum requirements by creating sample models using different datasets with different data profiles. The system can determine and store correlations among data profiles, target models types, tuned hyperparameters and the minimum number of samples required (for training or validating) to achieve a desired accuracy. When a user attempts to create a model from a new dataset the system can identify a closely-related data profile and estimate the minimum requirements for the model based upon a sample model that is associated with the data profile.
Estimating the minimum data requirements can reduce the computing resources needed to generate the new model. When the new dataset exceeds the minimum number of samples required, a new model can be created using a small portion of the user dataset. By limiting the dataset, you can avoid overprocessing training data and prevent potential overfitting. Moreover, by reducing the number of samples, the complexity of the models can be reduced (e.g. reduce the number parameters), which could reduce resource consumption at hyper-parameter optimization or other stages. The system can also save resources by not generating models which will not reach a target accuracy due to insufficient training data. The system can inform a user if the model will not reach the target accuracy using the training data available, saving resources.

In some embodiments, the system can also recommend or suggest model types on the basis of the dataset provided by the user. The system can, for example, generate several types of sample model (including regressions and instance-based models, clustering models, and deep learning models), and estimate the minimum data requirements of each type. The system can then recommend a type of model that will achieve the desired accuracy based on the user’s dataset. Using the sample models, the system can also make it easier to determine hyper-parameters when creating new models. Sample models can be simplified and optimized because they are trained using smaller datasets. In some embodiments, a system may be able to compare datasets using their data profiles in order to estimate similarity between training datasets. The system can, for example, use a statistical analysis to identify a data profile most closely related with the user data used to create a new model. The system can then tune parameters and hyperparameters based on the configuration of a sample model that was trained using a small sample dataset, but has a similar profile. It may also use the same hyperparameters or similar ones for the new model. The system could then reduce the cost of tuning hyper-parameters, and improve the efficiency of the predictive model generation.
In some embodiments, a user may find it easy to operate the system via a graphic user interface on client devices. The graphical interface may include controls, recommendations and/or options to automatically train models with parameters and hyperparameters likely to produce the most efficient models.
The disclosed systems and method address the technical problem of reducing computing resources during the generation and estimation of data requirements for new model. The disclosed systems and method also improve computer functionality by avoiding costly guess-and check optimizations which result in machine-learning models that are over- or under-tuned. The disclosed systems and methods also improve resource allocation in parallelized processes of predictive model generation. By comparing data profiles, disclosed systems and method may also avoid low-performing systems due to unexpected variances in the dataset. This is done by identifying similar sample models which reduce the complexity of hyperparameter tuning. These features lead to systems and methods which improve the efficiency of computerized systems in generating machine-learning algorithms.
A detailed description of the disclosed embodiments will be given, with examples illustrated in the accompanying drawings.
FIG. Block diagram 1 shows an example system 100 in accordance with the disclosed embodiments. The system 100 can be used to identify or estimate the data requirements for training machine-learning predictive model with a goal of reducing computation expenses. The optimization system 105 of the System 100 can include a data profiler 110, a model generation 120, and a hyper-parameter optimizer 130. The system 100 can also include online resources, client devices, computing clusters, databases, and computing clusters. As shown in some embodiments (see FIG. In some embodiments, as shown in FIG. In other embodiments, components of system can be directly connected to each other without network 170.
Online resources” 140 can include one or multiple servers or storage services offered by an entity, such as a website hosting provider, cloud or backup service provider, for example. In some embodiments online resources 140 can be associated with servers or hosting services that store web pages containing user credit histories and records of transactions. Online resources 140 can be linked to a cloud computing system such as Amazon Web Services in other embodiments. In other embodiments, the online resources 140 are associated with a message service such as Apple Push Notification Service or Google Cloud Messaging. In such embodiments online resources 140 can handle the delivery messages and notifications related functions of the disclosed embodiments such as completion notifications and messages.
Client devices 150 can include one or multiple computing devices configured to perform operations in accordance with the disclosed embodiments. For example, client devices 150 may include a desktop computer, a laptop, a server, a mobile device (e.g., tablet, smart phone, etc. Gaming devices, wearable computing devices, and other computing devices are all examples of client device 150. Client devices 150 can include one or multiple processors that are configured to execute instructions from memory (such as the memory in client devices 150) to perform operations in order to implement functions described below. Client devices 150 can include software that, when executed by processors, performs internet communication (e.g. TCP/IP), and content display processes. Client devices 150, for example, may execute browser software which generates and displays content-based interfaces on a display connected or included with client devices 150. Client devices 150 can execute applications to allow client devices 150 communicate with components via network 170 and generate and display interfaces using display devices in client devices. Display devices can be set up to display icons or images described in relation to FIG. 14. The disclosed embodiments do not limit themselves to any specific configuration of client devices. Client device 150, for example, may be a portable device that stores and runs mobile applications in order to perform functions provided by optimization system 110 and/or online resource 140. In certain embodiments client devices 150 can be configured to run software instructions related to location services such as GPS locations. Client devices 150, for example, may be configured so that they determine a geographical location and then provide location data as well as time stamp data to correspond to the location data.
Computing clusters 160 can include multiple computing devices that are in communication. In some embodiments computing clusters may consist of a grouping of processors communicating through fast local-area networks. Computing clusters 160 can also be a cluster of GPUs configured to operate in parallel. Computing clusters 160 can include heterogeneous and homogeneous hardware in such embodiments. Computing clusters 160 in some embodiments may include GPU drivers for each GPU type present on each cluster node. They also may include Clustering APIs (such as MPI) and VirtualCL cluster platforms such as OpenCL wrappers. This allows for most applications to use multiple OpenCL devices transparently in a cluster. Computing clusters 160 can also be configured to use distcc, a program that distributes builds of C++, Objective C, and Objective C++ code to multiple machines over a network in order to speed up the building process, MPICH, a standard message-passing protocol for distributed memory applications, Linux Virtual Server? or Linux-HA? or any other director-based clusters.
Databases 180 can include, for example, Oracle? Oracle, for instance, may be included in the databases 180. databases, Sybase? Sybase? HBase, Cassandra, or sequence files. The databases 180 may contain computing components, such as a database management system, a database server, or other similar components. “Configured to receive and process data requests stored in memory devices of database(s), and to provide data from database(s).
While databases 180 is shown separately, some embodiments may include or relate databases 180 to optimization system 105 (data profiler 110), model generator 120 (hyper-parameter optimizer 130), online resources 140, or any combination thereof.

Databases180 may be configured to collect or maintain data associated with the sample datasets that were used to create the sample models, and to provide them to the optimization system, model generator, hyper-parameter optimizer, and client devices, 150. The data may be collected by databases 180 from various sources, such as online resources 140. The databases 180 are described in more detail below, along with FIG. 5.

Click here to view the patent on Google Patents.

